Lessons from Jim Fan
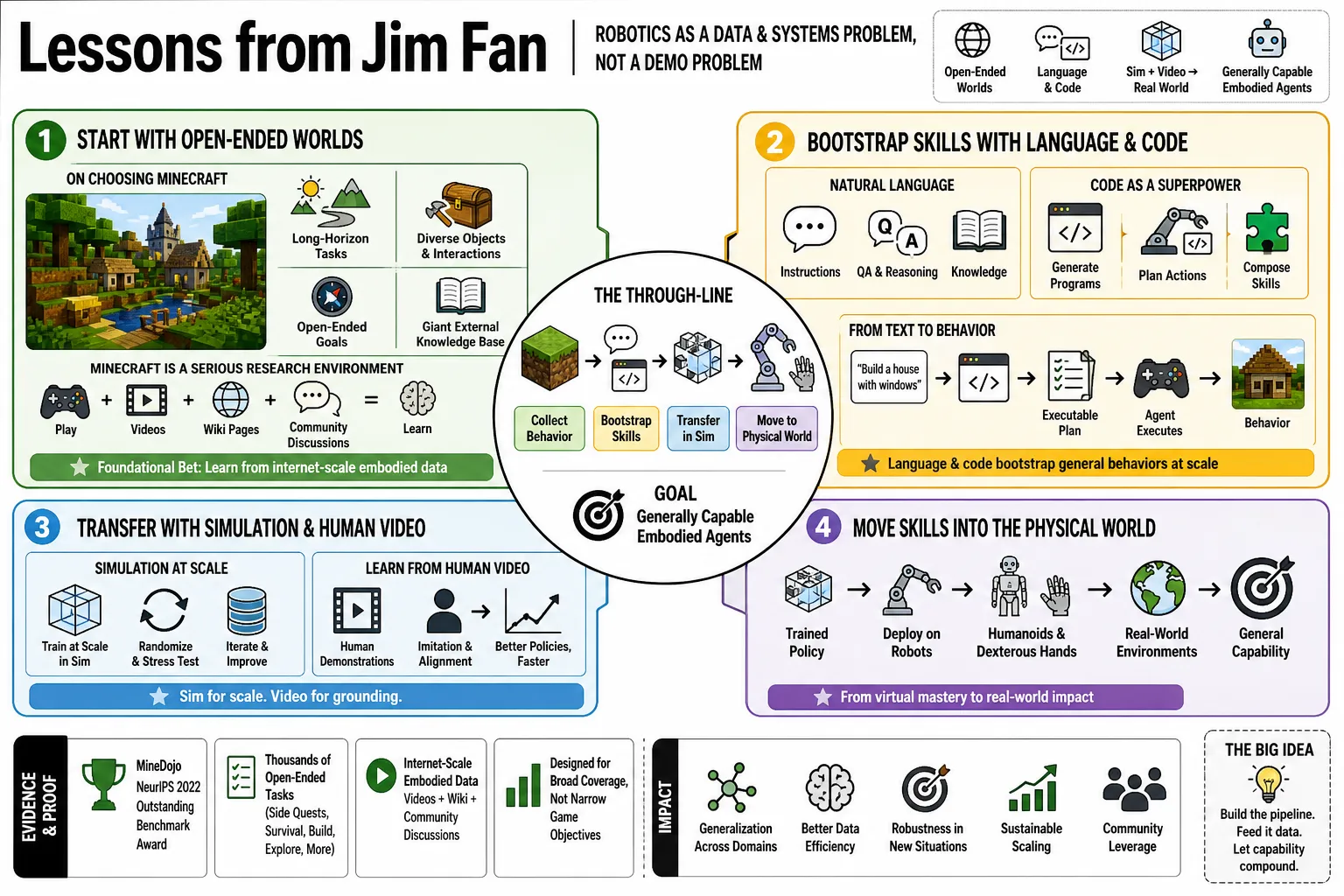
Jim Fan leads NVIDIA's work on generally capable embodied agents: systems that learn across games, simulations, humanoid robots, dexterous hands, and world models. His work is useful because it treats robotics as a data and systems problem, not a demo problem. The through-line is clear: use open-ended worlds to collect behavior, use language and code to bootstrap skills, then use simulation and human video to move those skills into the physical world.
Part 1: Start With Open-Ended Worlds
- On choosing Minecraft: MineDojo treated Minecraft as a serious research environment because it contains long-horizon tasks, diverse objects, open-ended goals, and a giant external knowledge base. — Source: MineDojo arXiv
- On internet-scale embodied data: MineDojo's core bet was that an agent could learn from Minecraft videos, wiki pages, and community discussions instead of relying only on handcrafted reward functions. — Source: NVIDIA MineDojo Blog
- On broad task coverage: The MineDojo benchmark was designed around thousands of open-ended tasks rather than a small set of narrow game objectives. — Source: MineDojo Project
- On research prizes: MineDojo won a NeurIPS 2022 Outstanding Datasets and Benchmarks Paper Award, which helped validate Minecraft as more than a toy domain. — Source: NVIDIA NeurIPS Awards
- On learning from culture: The important move was not only the simulator; it was connecting the simulator to the surrounding human culture of tutorials, walkthroughs, forum posts, and videos. — Source: MineDojo Paper
- On embodied AI before robots: Fan's path shows that virtual worlds can be the cheapest place to debug embodied intelligence before moving to expensive hardware. — Source: Jim Fan Website
- On open tools: MineDojo shipped a simulation suite, knowledge bases, algorithms, and pretrained models, reinforcing Fan's bias toward reusable research infrastructure. — Source: NVIDIA SRL MineDojo
Part 2: Turn Language Models Into Skill Builders
- On Voyager's claim: Voyager was framed as the first LLM-powered embodied lifelong learning agent in Minecraft, continuously exploring, acquiring skills, and making discoveries without human intervention. — Source: Voyager Project
- On code as action: Voyager's key move was using GPT-4 to write executable code, turning language reasoning into actions inside the game. — Source: Voyager arXiv
- On the skill library: Voyager stores successful programs in a persistent skill library, so progress becomes accumulated code rather than a temporary chat transcript. — Source: Voyager Project
- On self-debugging: The agent uses environment feedback and execution errors to revise its own code, making debugging part of the learning loop. — Source: Voyager arXiv
- On curriculum design: Voyager's automatic curriculum pushes it toward novelty, so it keeps searching for new items and capabilities instead of repeating solved tasks. — Source: Voyager Project
- On public impact: The Voyager work stood out because it gave a concrete example of an LLM agent that could accumulate capabilities over time, not merely answer prompts. — Source: WIRED
- On the practical lesson: Fan's agent work suggests that durable memory should often be a tool library, a codebase, or a world model, not a longer prompt. — Source: Voyager arXiv
Part 3: Make Robotics Promptable
- On VIMA's premise: VIMA showed that robot manipulation tasks could be expressed through multimodal prompts that interleave text and visual tokens. — Source: VIMA arXiv
- On general robot manipulation: VIMA treated manipulation as a sequence-modeling problem, using a transformer agent that reads prompts and autoregressively outputs motor actions. — Source: VIMA Project
- On prompt interfaces: The lesson from VIMA is that robotics interfaces can look more like instructions and examples than fixed controllers. — Source: VIMA arXiv
- On model scaling: VIMA's result matters because it connected robot manipulation to the same prompt-based learning pattern that had already worked in language. — Source: VIMA Paper PDF
- On early foundation models: Fan describes VIMA as one of the early multimodal foundation models for robot manipulation, placing it in the lineage before today's humanoid models. — Source: Jim Fan Website
- On unifying perception and action: The key architectural lesson is to stop treating vision, language, and motor control as separate products and instead train a single policy surface. — Source: VIMA Project
- On task diversity: A robot foundation model needs diverse tasks during training because brittle single-task competence does not transfer well to real homes or factories. — Source: GEAR Lab
Part 4: Automate the Bottlenecks
- On Eureka's target: Eureka attacked reward design, one of the most stubborn human bottlenecks in reinforcement learning. — Source: Eureka Project
- On coding rewards: Eureka used coding LLMs to generate and improve reward functions, turning reward design into an iterative program-search problem. — Source: Eureka arXiv
- On simulation loops: Eureka used GPU-accelerated simulation in Isaac Gym to evaluate batches of candidate reward programs quickly. — Source: Eureka Project
- On robot dexterity: Fan highlights Eureka because it taught a five-finger robot hand difficult skills like pen spinning, showing that language models can help with physical control indirectly. — Source: Jim Fan Website
- On the broader pattern: Eureka fits Fan's larger thesis: use foundation models to automate the parts of robotics research that used to require slow expert hand-design. — Source: GEAR Lab
- On reward functions as code: Once the reward is code, agents can mutate, test, and revise it, which makes the training loop more scalable than manual tuning. — Source: Eureka arXiv
- On infrastructure leverage: The important artifact is the loop: generate candidate code, run simulation, score behavior, and feed the result back into the model. — Source: Eureka Project
Part 5: Build Foundation Models for Humanoids
- On Project GR00T: NVIDIA announced Project GR00T as a general-purpose foundation model initiative for humanoid robots. — Source: NVIDIA Newsroom
- On humanoid learning: GR00T is meant to help robots understand natural language and learn coordination, dexterity, and other skills from human actions. — Source: NVIDIA Newsroom
- On platform thinking: The GR00T work sits inside a broader Isaac robotics stack that includes simulation, data generation, and workflow infrastructure. — Source: NVIDIA Isaac GR00T
- On GR00T N1: GR00T N1 was released as an open foundation model for generalist humanoid robots. — Source: GR00T N1 Research
- On dual systems: GR00T N1 uses a vision-language module for interpretation and a diffusion transformer module for generating fluid motor actions. — Source: GR00T N1 arXiv
- On data mixture: The GR00T N1 recipe uses real robot trajectories, human videos, and synthetic data rather than betting on one data source. — Source: GR00T N1 Research
- On deployment: The paper reports deployment on a Fourier GR-1 humanoid for language-conditioned bimanual manipulation. — Source: GR00T N1 arXiv
- On ecosystem strategy: Fan's robotics strategy is also a partner strategy: make a model and data platform that many humanoid companies can adapt. — Source: NVIDIA Isaac GR00T
- On synthetic data: GR00T-Gen and related workflows use simulation-ready environments and synthetic trajectories to expand robot training coverage. — Source: NVIDIA Technical Blog
Part 6: Treat Human Video as Robot Fuel
- On EgoScale: EgoScale reframed dexterous robot learning as a scaling problem over egocentric human video. — Source: EgoScale Project
- On data scale: EgoScale trained on more than 20,854 hours of action-labeled egocentric human video, over 20 times larger than prior efforts cited by the project page. — Source: EgoScale Project
- On the scaling law: The EgoScale team reported a near-perfect log-linear relationship between human data scale and validation loss. — Source: EgoScale arXiv
- On robot transfer: EgoScale combined large-scale human pretraining with a small amount of aligned human-robot mid-training to improve downstream dexterous manipulation. — Source: EgoScale Project
- On high-DoF hands: The policy improved average success rate over a no-pretraining baseline using a 22-degree-of-freedom robotic hand. — Source: EgoScale arXiv
- On the data bottleneck: Fan's newer work makes the case that robotics progress depends less on isolated teleoperation datasets and more on reusable human-motion priors. — Source: EgoScale Project
- On embodiment transfer: EgoScale's transfer across higher- and lower-DoF hands supports the idea that human motion can become an embodiment-agnostic training signal. — Source: EgoScale arXiv
Part 7: Move From Simulation to World Models
- On DreamGen: DreamGen uses video world models to generate neural trajectories that help robot policies generalize across behaviors and environments. — Source: DreamGen Project
- On pseudo-actions: Because video models generate videos rather than robot commands, DreamGen recovers pseudo-action sequences through latent action or inverse-dynamics models. — Source: DreamGen arXiv
- On zero-shot generalization: DreamGen reports zero-shot behavior and environment generalization after using teleoperation data from only a single pick-and-place task in one environment. — Source: DreamGen Project
- On DreamDojo: DreamDojo is a generalist robot world model trained from large-scale human videos, then post-trained on small target-robot data. — Source: DreamDojo arXiv
- On open artifacts: NVIDIA released DreamDojo artifacts on Hugging Face, continuing Fan's preference for public research objects rather than closed demos alone. — Source: DreamDojo Hugging Face
- On DreamZero: DreamZero introduced a World Action Model built on a pretrained video diffusion backbone. — Source: DreamZero arXiv
- On replacing VLA limits: The World Action Model direction tries to make vision and action first-class rather than appending actions to a language-heavy model. — Source: DreamZero PDF
- On the systems arc: The progression from MineDojo to Voyager to GR00T to DreamZero is a progression from game agents to executable skills to robot policies to learned physical futures. — Source: GEAR Lab
Part 8: The Research Operating System
- On GEAR's mission: GEAR's stated mission is to build foundation models for embodied agents in both virtual and physical worlds. — Source: GEAR Lab
- On the research portfolio: GEAR organizes its work around multimodal foundation models, general-purpose robots, foundation agents, and simulation or synthetic data. — Source: GEAR Lab
- On career positioning: Fan's own biography connects Stanford vision research, early OpenAI experience, NVIDIA robotics, and a consistent interest in agents that act in worlds. — Source: Jim Fan Website
- On OpenAI roots: Fan notes that he was OpenAI's first intern in 2016 and worked on World of Bits, an early agent project for browser control from pixels. — Source: Jim Fan Website
- On public thought leadership: Fan's recent AI Ascent appearance placed his robotics argument in front of founders and researchers focused on the next phase of AI infrastructure. — Source: Sequoia AI Ascent 2026
- On the robotics end game: His 2026 argument is that robotics can follow a parallel path to language models: pretraining, action tuning, reinforcement learning, and eventually automated physical research. — Source: Zeus AI Summary
- On a useful prediction: The most actionable version of Fan's thesis is not a timeline; it is the stack: human video, world models, simulation, robot foundation models, and automated evaluation loops. — Source: GEAR Lab
- On the durable lesson: Fan's work argues that embodied AI advances when research teams build data engines and training loops that make every successful behavior reusable. — Source: Jim Fan Website