Lessons from Lin Qiao
Lin Qiao is the CEO and co-founder of Fireworks AI, an inference platform built to make generative AI fast and affordable. She previously spent seven years as a senior engineering director at Meta, where she led the team that scaled PyTorch into the default machine learning framework. Her work focuses on the practical mechanics of getting AI out of the lab, shifting attention from training massive models to optimizing them for speed, cost, and actual enterprise use cases.
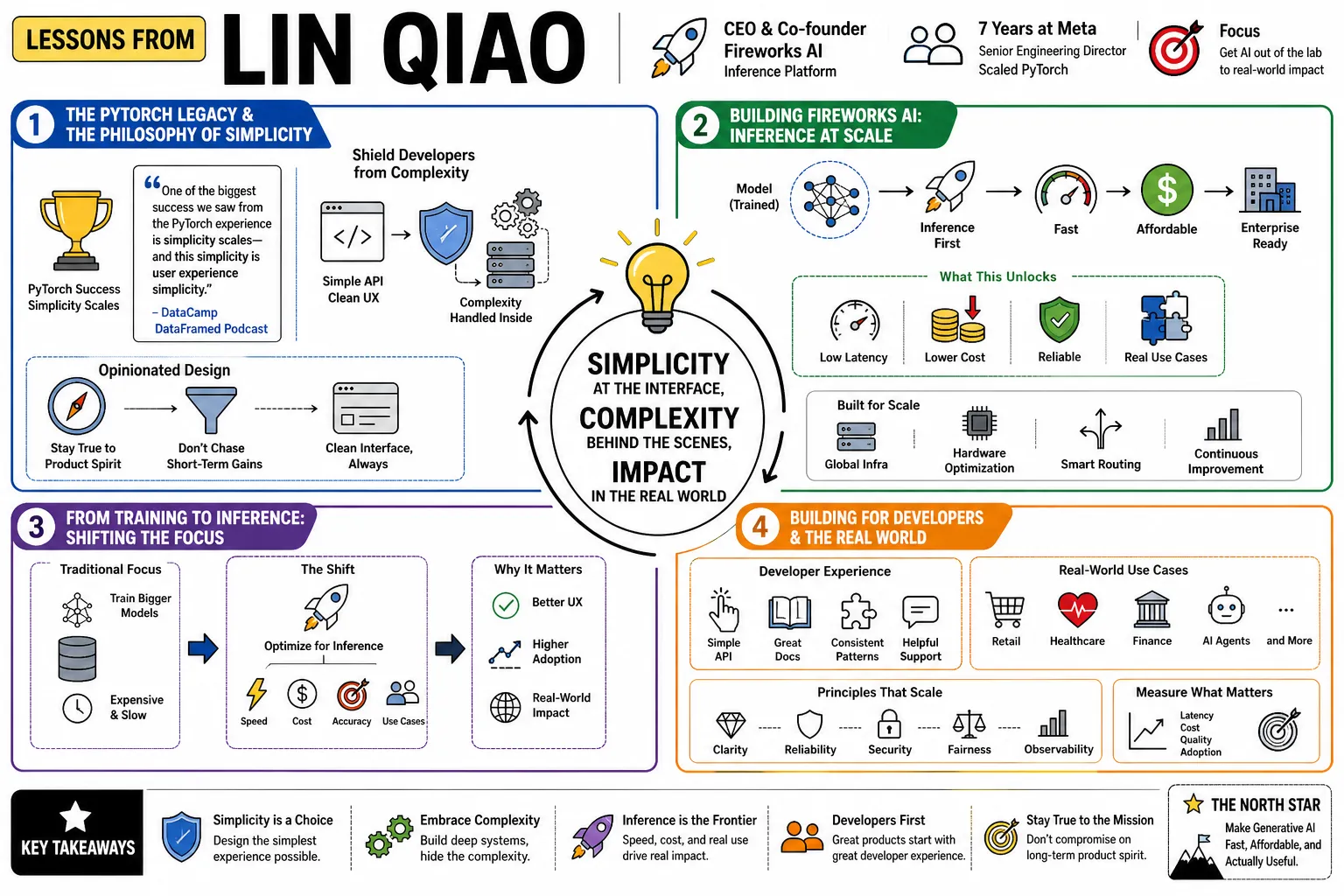
Part 1: The PyTorch Legacy & the Philosophy of Simplicity
- On the primary lesson of PyTorch: "One of the biggest success we saw from the PyTorch experience is simplicity scales—and this simplicity is user experience simplicity." — Source: DataCamp DataFramed Podcast
- On shielding developers from complexity: "At Fireworks, they’ve embraced enormous complexity behind the scenes to provide a simple API for developers." — Source: The Stack
- On opinionated design: Product leaders should not compromise on the core product spirit or design for short-term gains; they must maintain a clean interface even as the underlying infrastructure grows. — Source: Humanloop Interview
- On making things work for the user: While engineers can solve any degree of complexity, end users and developers just want things to work without having to configure them endlessly. — Source: Focal VC Interview
- On the nature of AI development: "I think that's just the nature of AI. It requires a lot of experimentation. And there are multiple things to experiment on. At the top, experimentation is the top of the funnel." — Source: DataCamp DataFramed Podcast
- On building PyTorch's ecosystem: The framework was built to be intuitive for researchers, so that making it simple for model creators naturally meant those models flowed easily into production. — Source: The New Stack
- On framing the problem: "How you frame the problem you want to solve is the framing, right? Because the framing will directly determine which technology you're going to pull into the stack to solve the problem." — Source: DataCamp DataFramed Podcast
- On deterministic vs. probabilistic systems: Before generative AI, logic was coded in the application itself and was deterministic. Today, developers must manage the inherently probabilistic nature of language models. — Source: Sequoia Capital's Training Data
- On the importance of debuggability: PyTorch succeeded heavily because its dynamic nature allowed for standard Python debugging tools, giving researchers rapid feedback loops. — Source: Turing Post
- On unifying fragmentation: A core mission at Meta was reducing the fragmentation of AI frameworks, consolidating disparate tools into a single stack to reduce engineering hassle. — Source: TWIML AI Podcast
Part 2: The Economics of Inference & The Iceberg Problem
- On the cost of scaling AI: "The whole cost structure of productionized application on top of GenAI significantly changed... If they have a viable product, that means they can scale quickly. And if they're losing money at the small scale, they're gonna bankrupt quickly." — Source: DataCamp DataFramed Podcast
- On the GenAI PMF trap: "In GenAI, hitting product-market fit can actually be the beginning of bankruptcy." — Source: Turing Post
- On the inference iceberg: "You can visualize it like an iceberg. Right now, a huge iceberg of GenAI applications is being built, but most of it is still submerged under the waterline because infrastructure costs are so high." — Source: Turing Post
- On future capital expenditure: "We believe the future demand is on inference, and the demand on inference is going to be way, way, way bigger than training. That underlines the need for that infrastructure spend for the inference side." — Source: Turing Post
- On the true bottleneck of AI: "What limits AI today isn't imagination – it's the cost of running it at scale." — Source: Turing Post
- On holding the latency bar: "Latency is a critical part of product experience. Holding the latency bar doesn't change before and after GenAI." — Source: Sequoia Capital's Training Data
- On separating product success from business success: "In today's stage, having a product-market fit and having a viable business are completely two separate things." — Source: DataCamp DataFramed Podcast
- On system saturation: "The whole system is saturated." The rapid adoption of generative AI has caused cascading bottlenecks from semiconductor components all the way to energy grids. — Source: India Times
- On exponential consumption: "This is the year token consumption is going to grow exponentially... Demand is only just getting started." — Source: Business Insider
Part 3: The Shift From Training to Production
- On the AI customer journey: "The AI customer journey moves from training to inference, and as these first products find PMF, many are hitting a wall on latency and cost." — Source: Sequoia Capital's Training Data
- On compressing timelines: The goal for enterprise AI deployment is to compress the timeframe of building and inference from five years to just five days. — Source: TwinMind
- On moving past lab experiments: While the first wave of generative AI was about training and lab experimentation, the current phase is strictly about executing inference at a massive scale. — Source: Sequoia Capital's Training Data
- On the limitations of foundational training data: "Put all the foundation models together, it will still have limited knowledge because its training data is limited. Its training data has a starting time, ending time." — Source: Sequoia Capital's Training Data
- On hidden enterprise knowledge: A vast amount of the world's functional knowledge is hidden behind private APIs that general foundational models cannot access. — Source: Sequoia Capital's Training Data
- On infusing product knowledge: "How to infuse your product knowledge into your model is a new area that most people don't know how to do." — Source: Substack Newsletter
- On optimization timing: Startups should focus heavily on capability and quality at day one, but must pivot to optimizing speed and cost the moment they establish product-market fit. — Source: TWIML AI Podcast
- On declarative inference engines: Like SQL in databases, the future of inference relies on developers specifying desired outcomes while the engine handles complex model sharding and caching automatically. — Source: TwinMind
- On the developer's role: "Fireworks wants to provide value by making application developers shine. Our role is to build the best tools and infrastructure for them." — Source: Turing Post
Part 4: Small Expert Models vs. Generalist Giants
- On the end of the monolithic model era: "The next wave of quality is not going to be one of 'single model solves all problems.' The future, in short, will involve hundreds of small expert models solving narrower sets of problems." — Source: The Stack
- On enterprise specialization: "Enterprises don't need a single massive AI that performs everything at a mediocre level—they require highly optimized models that excel in specific domains like healthcare, law, and finance." — Source: Focal VC Interview
- On starting points for experimentation: "I will actually suggest them to try on the large model first... but with this new advancement, I think the small models are becoming more and more appealing." — Source: DataCamp DataFramed Podcast
- On the one-size-fits-one approach: The future of AI value creation belongs to a diverse ecosystem of specialized models rather than relying on one general-purpose commodity. — Source: The MAD Podcast
- On reducing latency through small models: A specialized infrastructure stack optimized for smaller models in the 7B to 70B parameter range is required to achieve high responsiveness for real-time applications. — Source: TwinMind
- On compound AI systems: The next breakthrough isn't a single massive model, but compound AI systems that interweave multiple specialized models, tools, and retrieval mechanisms. — Source: The Stack
- On mitigating hallucinations: "AI models are not deterministic; models are probabilistic. The downside of that is that they can hallucinate... The best way to reduce that is to give it a lot of context." — Source: The Stack
- On speculative decoding: Achieving high performance often involves pairing a small, fast model with a large model to deliver large model quality at small model speed. — Source: TWIML AI Podcast
- On compound model strategy: Specialized compound models demonstrate that complex reasoning can be achieved at the inference layer by orchestrating multiple open-source models, driving down costs. — Source: The Stack
Part 5: Open Source Innovation & Enterprise Control
- On the inevitable victory of open source: "The open community, the open science community, the collective effort we pull together can really beat proprietary. That's my prediction—the open-source model is going to be better than proprietary." — Source: Focal VC Interview
- On enterprise demand for transparency: "We believe strongly in developing in the open. Our business model is mainly focused on open models because they give enterprises transparency and control – something they care about deeply." — Source: Turing Post
- On pragmatic adoption: "Their goal isn't to make open models successful – their goal is to solve business problems and deliver impact. They'll use whatever tool helps them do that." — Source: Turing Post
- On model convergence: The quality gap between proprietary, closed-source models and top-tier open-source models is shrinking rapidly, forcing infrastructure to become the key differentiator. — Source: Sequoia Capital's Training Data
- On democratizing access: Providing low-latency, highly optimized access to open-source models allows startups to build generative AI products without relying entirely on a few massive technology gatekeepers. — Source: HighPerformr
- On avoiding closed-API lock-in: Relying solely on third-party, closed-source APIs is a high-risk long-term strategy for startups that want to maintain control over their data and inference costs. — Source: The Data Exchange
- On the power of the open science community: The rapid, decentralized iteration within the open-source community inherently outpaces the development cycles of siloed, proprietary research labs. — Source: Focal VC Interview
- On utilizing adapter weights: Deploying open-source base models with multi-adapter support allows developers to serve highly customized, fine-tuned models at virtually no extra memory cost. — Source: Summify
- On owning the AI stack: Companies that utilize open-source models to build their own inference pipelines protect their margins and establish deep data sovereignty. — Source: The MAD Podcast
Part 6: The 3D Optimization Framework
- On the three dimensions of inference: The future of AI deployment relies on balancing three pillars: Quality to meet rigorous standards, Speed for ultra-low latency, and Cost for sustainable scaling. — Source: Sequoia Capital's Training Data
- On moving beyond the vibe check: Transitioning from lab prototypes to millions of users requires shifting from subjective vibe checking of model outputs to rigorous, automated evaluation. — Source: TWIML AI Podcast
- On finding the needle in the haystack: Optimizing AI involves searching through hundreds of thousands of combinations of quantization levels, specialized kernels, and sharding strategies to find the exact setup for a specific workload. — Source: SuperDataScience
- On the necessity of distillation: Enterprises must distill large, expensive models into smaller, faster versions without sacrificing the quality necessary for their specific domain tasks. — Source: SuperDataScience
- On co-designing models and products: Models cannot be treated as separate entities; they must be co-designed alongside the actual product, utilizing real-world production data for continuous tuning. — Source: TWIML AI Podcast
- On the bushy tree of choices: "There are like, I will say it's a bushy tree of experimentation you need to try... Do you prompt or do you fine-tune? ... Once you get into good quality, then you go down to the next level." — Source: DataCamp DataFramed Podcast
- On custom hardware kernels: Drastically reducing latency requires writing highly optimized custom compute kernels designed specifically to accelerate the attention mechanisms in transformer models. — Source: Summify
- On automated infrastructure: The goal of modern AI tools is to navigate this three-dimensional optimization space on behalf of the developer, automating the complex backend tuning. — Source: Summify
- On preventing deployment friction: The generative AI development lifecycle requires closely aligning the systems used for training with those used for inference to prevent friction when pushing to production. — Source: TWIML AI Podcast
- On sustainable business growth: Managing the cost dimension is not just about engineering elegance; it is the fundamental requirement for making AI products financially viable as user bases scale. — Source: Sequoia Capital's Training Data
Part 7: Company Building, Strategy & Product-Led Growth
- On the real limitation of founders: "Often the real limitation is your inner voice, not the external world. That's why I believe finding people who challenge you – who make you uncomfortable – is a blessing." — Source: Turing Post
- On the tunnel of discomfort: "It's painful, but if you face it... you come out a different person on the other side. The people who challenge you and push you through the tunnel of discomfort – they're the ones who shape who you become." — Source: Turing Post
- On product-led growth: "I do not like the go-to-market strategy where marketing is like one year, two years ahead of product... product will speak for itself." — Source: Turing Post
- On rapid validation: "It's okay to make wrong assumptions, but it's not okay to not validate for a long time... all we have is a race with time." — Source: Turing Post
- On building a defensible moat: A startup's primary competitive advantage is activating its private data to build proprietary, specialized intelligence. — Source: TWIML AI Podcast
- On iterating at high speed: Companies must establish infrastructure that permits rapid iteration, allowing them to thoroughly test assumptions and establish product-market fit before locking into heavy capital expenditures. — Source: TWIML AI Podcast
- On avoiding marketing fluff: An AI company's primary focus must remain on the engineering reality of its product, ensuring that the software's capabilities actually match its market promises. — Source: Turing Post
- On making hard tradeoffs: Effective leadership in the AI infrastructure space means being highly opinionated about system architecture, even if it requires making short-term sacrifices in user acquisition. — Source: Humanloop Interview
- On bridging research and production: The most successful technical leaders are those who can straddle the gap between cutting-edge, experimental lab research and the strict reliability requirements of global production systems. — Source: The MAD Podcast
Part 8: The Future of AI Agents & Data Flywheels
- On the era of autonomous agents: "Right now, the big theme is agents. Startups and enterprises alike are building them... coding agents, hiring agents, SRE agents that debug and triage production issues." — Source: Turing Post
- On the infrastructure required for agents: "To solve a problem you will have multiple round trips across multiple models... those models have to be much faster, much smaller, and more optimized." — Source: Turing Post
- On the core data flywheel: "Product data aligns with the model, making the model better tuned to the application. A better model drives better user engagement." — Source: Turing Post
- On completing the virtuous cycle: "More engagement produces more data. More data improves the model again. That's the virtuous cycle we want developers to build." — Source: Turing Post
- On data alignment as the next frontier: The next wave of value generation in AI will not come from building bigger baseline models, but from meticulous data alignment—using proprietary feedback to perfectly fit a model to a business task. — Source: TWIML AI Podcast
- On ubiquitous adoption: We are entering a phase where AI tools are completely saturated into the market, as literally every single person begins using these tools in their daily workflows. — Source: Business Insider
- On the necessity of speed for agents: Because autonomous agents require rapid, sequential prompting to execute complex reasoning loops, any latency in the base model multiplies exponentially, making speed the primary bottleneck for agentic AI. — Source: Turing Post
- On leveraging private APIs: The most powerful AI agents of the future will be those capable of seamlessly interfacing with the hidden, private APIs that hold the vast majority of enterprise operational knowledge. — Source: Sequoia Capital's Training Data
- On owning your intelligence: To succeed in the era of AI agents, companies must transition from renting intelligence via generic APIs to actively owning and fine-tuning the models that run their core autonomous systems. — Source: TWIML AI Podcast
- On empowering the developer: By treating AI models as modular, swappable components within a larger compound system, developers are finally given the tools to build agentic workflows that are both creative and financially viable. — Source: The Stack