Lessons from Martin Kleppmann
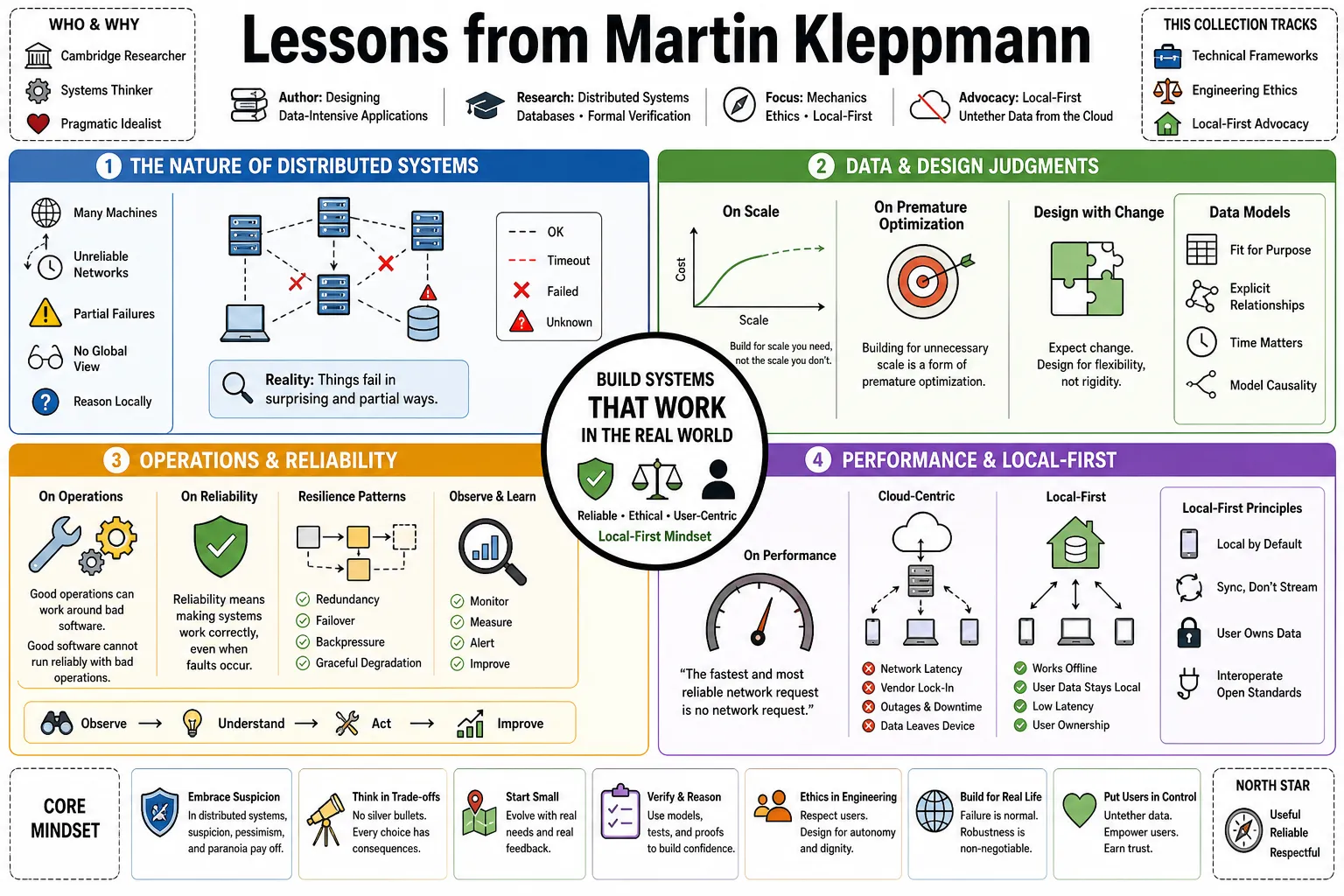
Martin Kleppmann is a Cambridge researcher and the author of Designing Data-Intensive Applications, the default manual for modern backend architecture. His research untangles the mechanics of distributed systems, database design, and formal verification. This collection tracks his technical frameworks, his views on engineering ethics, and his advocacy for "local-first" software that untethers user data from centralized cloud servers.
Part 1: The Nature of Distributed Systems
- On Suspicion: "In distributed systems, suspicion, pessimism, and paranoia pay off." — Source: [Designing Data-Intensive Applications]
- On Scale: "Building for scale that you don't need is wasted effort and may lock you into an inflexible design." — Source: [Designing Data-Intensive Applications]
- On Premature Optimization: "In effect, building for scale that you don't need is a form of premature optimization." — Source: [Goodreads Quotes]
- On Operations: "Good operations can often work around the limitations of bad (or incomplete) software, but good software cannot run reliably with bad operations." — Source: [Designing Data-Intensive Applications]
- On Reliability: "Reliability means making systems work correctly, even when faults occur." — Source: [Designing Data-Intensive Applications]
- On Performance: "The fastest and most reliable network request is no network request at all." — Source: [Local-first software essay]
- On Fault Tolerance: We must design systems to expect and manage faults rather than hoping they won't happen. — Source: [Designing Data-Intensive Applications]
- On Magic Scaling: "There is no such thing as a generic, one-size-fits-all scalable architecture (informally known as 'magic scaling sauce')." — Source: [Goodreads Quotes]
- On System Failures: Distributed systems have a potentially infinite state space due to the permutations of message interleavings, delays, and failures. — Source: [Martin's Blog]
Part 2: Time, Clocks, and Causality
- On Clock Drift: "The quartz clock in a computer isn't very accurate... It can vary depending on the temperature of the machine. Basically, it drifts." — Source: [Timi Learning]
- On Confidence Intervals: "Clock readings have a confidence interval; synchronized clocks for global snapshots." — Source: [Timi Learning]
- On NTP Limitations: Network Time Protocol can cause clocks to jump backward or pause, which breaks application logic that assumes time only moves forward. — Source: [Medium Summary]
- On Logical Clocks: "Logical clocks are an alternative definition of clocks... specifically designed to capture the causal relationships between the events that happen in a system." — Source: [YouTube Lecture]
- On Vector Clocks: Vector clocks allow us to distinguish between two events that are concurrent and two events where one happened before the other. — Source: [YouTube Lecture]
- On Asking the Right Question: The core insight of causality is shifting from asking when something happened to whether one thing happened before another. — Source: [CMU Lecture Notes]
- On Physical Clocks: Relying on physical time-of-day clocks for ordering is dangerous because they are inherently unreliable in distributed environments. — Source: [Designing Data-Intensive Applications]
- On True Ordering: Consensus is essentially equivalent to Total Order Broadcast—ensuring every node processes the same messages in the exact same order. — Source: [Martin's Blog]
- On Time Independence: Causality provides a much stronger foundation for system design than physical time, because it is deterministic and stable. — Source: [Designing Data-Intensive Applications]
Part 3: Databases and Abstractions
- On NoSQL: "The moral of the story is that a NoSQL system may find itself accidentally reinventing SQL, albeit in disguise." — Source: [Goodreads Quotes]
- On Database Tools: "A database is just a tool: how you use it is up to you." — Source: [Designing Data-Intensive Applications]
- On Data Models: "Data models are perhaps the most important part of developing software... they affect how we think about the problem that we are solving." — Source: [Designing Data-Intensive Applications]
- On the CAP Theorem: The common use of the CAP theorem to categorize databases is often too simplistic for analyzing real-world systems. — Source: [Martin's Blog]
- On State: "Databases are global, shared, mutable state... A more promising model is to think of a database as an always-growing collection of immutable facts." — Source: [Turning the Database Inside Out]
- On Abstractions: Abstractions like distributed transactions or linearizability often leak, meaning engineers must understand the underlying trade-offs rather than expecting magic. — Source: [Designing Data-Intensive Applications]
- On Custom Solutions: The architecture of systems that operate at large scale is usually highly specific to the application. — Source: [Goodreads Quotes]
- On Choosing Tech: Engineers should choose technology by understanding the problem first rather than blindly following industry hype. — Source: [GOTO Unscripted]
- On SQL's Endurance: The fact that NoSQL systems eventually add SQL-like querying capabilities proves the enduring utility of declarative data models. — Source: [Designing Data-Intensive Applications]
- On Data Over Code: "Data outlives code." — Source: [Designing Data-Intensive Applications]
Part 4: Event Sourcing and Stream Processing
- On the Inside-Out Database: "The log is the database; everything else—indexes, caches, materialized views—is a projection over the log." — Source: [Turning the Database Inside Out]
- On Event Sourcing: "Rather than performing destructive state mutation on a database when writing to it, we should record every write as an immutable event." — Source: [Martin's Blog]
- On Losing History: "If you overwrite data in your database, you lose this historic information. Keeping the list of all changes as a log of immutable events thus gives you strictly richer information." — Source: [Martin's Blog]
- On Stream Processing: Stream processing is essentially like a database that never stops running. — Source: [Turning the Database Inside Out]
- On Real-Time Functions: "A more fruitful approach is to take the streams of facts as they come in, and functionally process them in real-time." — Source: [Martin's Blog]
- On Idempotence: Stream processing should be idempotent so that even if a message appears more than once, it just takes effect once. — Source: [YouTube Lecture]
- On Kafka: "Kafka is actually rather like the Unix tool tail -f... except it's distributed." — Source: [YouTube Lecture]
- On the Unix Philosophy: Kafka and Samza apply the Unix philosophy to distributed data by providing small, composable tools connected by a common interface. — Source: [Turning the Database Inside Out]
- On Dual Writes: Writing to a database and a cache simultaneously is dangerous; it is safer to use a log-based architecture to guarantee consistent updates. — Source: [Martin's Blog]
- On Derived Data: Caches, indexes, and search systems are simply different derived views computed from the primary event log. — Source: [Designing Data-Intensive Applications]
Part 5: Local-First Software and Ownership
- On the Core Idea: "In local-first applications we swap these roles: we treat the copy of the data on your local device—your laptop, tablet, or phone—as the primary copy." — Source: [Local-first software essay]
- On Servers: "Servers still exist, but they hold secondary copies of your data." — Source: [Local-first software essay]
- On the Best of Both Worlds: "The cloud gives us collaboration, but old-fashioned apps give us ownership. Can’t we have the best of both worlds?" — Source: [Local-first software essay]
- On Instant Response: Local-first software provides instant response times because there are no spinners waiting for network requests. — Source: [Local-first software essay]
- On Offline Support: If the software does not work with the WiFi off, it is fundamentally not a local-first application. — Source: [Metamuse Podcast]
- On Longevity: Software and data should be designed to remain accessible and functional for decades, regardless of the original vendor. — Source: [Local-first software essay]
- On Business Survival: "If it doesn't work when the app developer goes out of business and shuts down their servers, it's not local-first." — Source: [Metamuse Podcast]
- On Privacy by Default: Local-first architectures naturally lend themselves to end-to-end encryption, ensuring security and privacy by default. — Source: [Local-first software essay]
- On User Control: Users should have total ownership of their data and the ability to move it anywhere without friction. — Source: [Local-first software essay]
- On Simplification: Building applications with local-first principles can actually lead to simpler architectures by removing the tight coupling to server state. — Source: [Software Engineering Radio]
Part 6: CRDTs and Collaborative Systems
- On Conflict-Free Merging: CRDTs ensure that when multiple users edit data simultaneously, all replicas will eventually converge to the exact same state without central coordination. — Source: [Automerge Project]
- On CRDTs vs. Consensus: Consensus protocols try to choose one value and discard others, whereas CRDTs keep all changes and merge them deterministically. — Source: [ACM Tech Talks]
- On Optimistic Replication: CRDTs are built on the idea of optimistic replication, allowing local writes to succeed immediately and resolving conflicts later. — Source: [Martin's Blog]
- On JSON Data: Libraries like Automerge demonstrate that complex, nested data structures like JSON can be safely treated as CRDTs for collaborative applications. — Source: [Automerge Project]
- On Collaboration Software: Modern collaboration requires shifting from static files to event-based systems that capture every granular user edit. — Source: [ACM DEBS 2021]
- On Encrypted CRDTs: It is possible to combine the real-time collaboration of CRDTs with the end-to-end encryption found in secure group messaging apps. — Source: [Research Paper Presentation]
- On Decentralization: CRDTs provide the mathematical foundation necessary to build truly decentralized, peer-to-peer software networks. — Source: [Software Engineering Daily]
- On Data Loss: Merging algorithms must be designed so that user work is never silently discarded during conflict resolution. — Source: [Local-first software essay]
- On Network Partitions: CRDTs mathematically guarantee that a system can continue functioning and accept writes even during severe network partitions. — Source: [Automerge Project]
Part 7: Formal Verification and "Vericoding"
- On the Limits of Testing: "Testing systems is great, but tests can only explore a finite set of inputs and behaviors." — Source: [Martin's Blog]
- On Proofs: "If you want to be sure that a program does the right thing in all possible situations, testing is not sufficient: you need proof." — Source: [Martin's Blog]
- On Cost: "For most systems, the expected cost of bugs is lower than the expected cost of using the proof techniques that would eliminate those bugs." — Source: [Martin's Blog]
- On Isabelle/HOL: Isabelle/HOL acts somewhat like a programming language and REPL for mathematical proofs, automating the verification of logical steps. — Source: [Martin's Blog]
- On Invariants: While tools can verify an invariant, designing the correct invariant for a distributed system still requires deep human intuition. — Source: [Martin's Blog]
- On AI and Verification: "AI will make formal verification go mainstream." — Source: [Martin's Blog]
- On Counteracting Hallucinations: "The precision of formal verification counteracts the imprecise and probabilistic nature of LLMs." — Source: [Martin's Blog]
- On Automation: Large language models are well-suited to the tedious task of writing the extensive proof code required for formal verification. — Source: [Martin's Blog]
- On Vericoding: Moving from "vibecoding" to "vericoding" means using AI to generate code that is mathematically proven to be correct, allowing us to skip human review with confidence. — Source: [Martin's Blog]
Part 8: Ethics, Responsibility, and the Future
- On the Power of Technology: "Technology is a powerful force in our society. Data, software, and communication can be used for bad... But they can also be used for good." — Source: [Designing Data-Intensive Applications]
- On Tools vs. Masters: "Data and models should be our tools, not our masters." — Source: [Designing Data-Intensive Applications]
- On Moral Imagination: "If we want the future to be better than the past, moral imagination is required, and that's something only humans can provide." — Source: [Designing Data-Intensive Applications]
- On Algorithmic Bias: If there is systematic bias in input data, machine learning algorithms will inevitably learn and amplify that bias in their output. — Source: [Designing Data-Intensive Applications]
- On Math-Washing: We must avoid the illusion of objectivity, where a decision is assumed to be fair simply because a computer algorithm made it. — Source: [Designing Data-Intensive Applications]
- On Feedback Loops: Predictive analytics can create dangerous self-fulfilling prophecies, reinforcing the very biased behaviors they claim to measure. — Source: [Designing Data-Intensive Applications]
- On Unintended Consequences: Engineers hold a fundamental responsibility to anticipate and mitigate the unintended consequences of the systems they deploy. — Source: [Designing Data-Intensive Applications]
- On Privacy by Design: Data should be purged as soon as it is no longer needed, rather than hoarded indefinitely out of convenience. — Source: [Designing Data-Intensive Applications]
- On the True Cost of Systems: The architectural decisions we make about data storage and privacy will impact users' lives long after the original code is rewritten. — Source: [Designing Data-Intensive Applications]