Lessons from Matei Zaharia
Matei Zaharia built Apache Spark during his UC Berkeley PhD and later co-founded Databricks as its CTO, turning an academic project into standard enterprise infrastructure. This profile follows his move from designing core big data tools to his current work on compound AI systems and programmatic model optimization.
Part 1: The Origins of Apache Spark
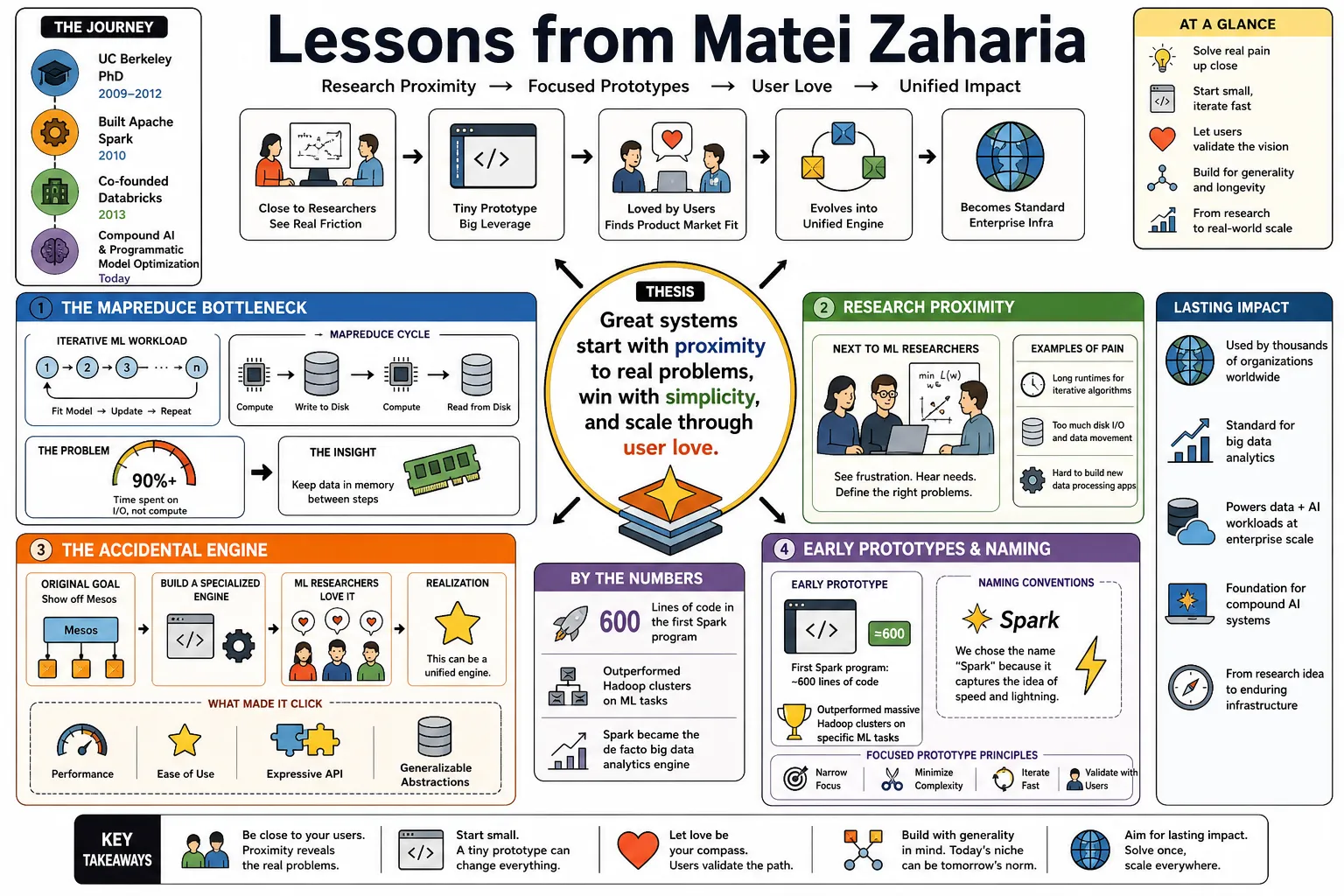
- On the MapReduce Bottleneck: "Iterative algorithms spend more time reading and writing to disk than computing. We needed a way to keep data in memory between steps to make machine learning feasible." — Source: [Unsupervised Learning]
- On Research Proximity: "Sitting next to machine learning researchers showed me their frustration with Hadoop. Proximity to the users defined the problems we chose to solve." — Source: [MLOps Coffee Sessions]
- On the Accidental Engine: "Spark was originally intended as a specialized engine to show off Mesos. It was only after seeing how much the ML researchers loved it that we realized it could be a unified engine." — Source: [Berkeley AMPLab]
- On Early Prototypes: "The first Spark program was only about 600 lines of code, but it outperformed massive Hadoop clusters on specific machine learning tasks." — Source: [Databricks Blog]
- On Naming Conventions: "We chose the name 'Spark' because it was short, easy to remember, and suggested something that could ignite a larger process." — Source: [ACM ByteCast]
- On Hardware Constraints: "Sharing data in memory within the same machine is easily 10 to 100 times faster than the network or the disk." — Source: [SiliconAngle]
- On the CPU Shift: "CPU, which wasn’t really optimized for much in the early systems, eventually became the bottleneck in systems like Hadoop and Spark as memory got faster." — Source: [Data + AI Summit]
- On Generality in Design: "Specialized engines can create complexity and inefficiency; users must stitch together disparate systems. Spark’s generality simplifies application development through a unified API." — Source: [Stanford DAWN]
- On Accessibility: "My team at Berkeley wanted to find a way to make data processing more accessible to users beyond full-time software engineers, such as data analysts and data scientists." — Source: [Monte Carlo Data]
Part 2: The Philosophy of Open Source
- On the Network Effect: "It’s in everyone’s interest to have a common platform to build on because there’s a network effect. The more applications that run on Spark, the more valuable it is for vendors." — Source: [SiliconAngle]
- On Toy Versions: "There’s temptation for vendors to have their open source software be a toy version and then you get the real one from them. That is bad for the community." — Source: [Unsupervised Learning]
- On Vendor Neutrality: "We didn't want to own Spark; we wanted to build a community. We donated Spark to the Apache Software Foundation to prove it was a neutral, vendor-independent project." — Source: [Berkeley AMPLab]
- On Open Protocols: "Just having yet another proprietary way to deliver stuff won’t make a huge dent. Open protocols like Delta Sharing simplify our collective jobs." — Source: [Databricks Blog]
- On Business Utility: "Open source is a tool for distribution and collaboration, but it is not the end goal. Use it only if it serves the product's core mission." — Source: [B2BaCEO]
- On Ecosystem Standards: "With MLflow, we looked at the MLOps space and saw there’s no open source solution that anyone can just extend. We identified the need for an ecosystem standard." — Source: [MLOps Coffee Sessions]
- On Lock-in: "We provide open-source portability to guarantee that users are not locked into our specific vendor implementation." — Source: [No Priors]
- On Open Governance: "Governance shouldn't be a walled garden. By open-sourcing Unity Catalog, we are providing the industry with a standard, open way to manage data." — Source: [Data + AI Summit]
- On Democratization: "The primary function of our open-source projects is to democratize access to high-scale machine learning tools for organizations outside of big tech." — Source: [ACM ByteCast]
Part 3: From Academia to Industry
- On the Prototyping Mindset: "In academia, the goal is often to build a prototype that proves an idea works. In a startup, you must build software that is maintainable and reliable over years." — Source: [Stanford DAWN]
- On Designing for Evolution: "While you start with a prototype to find product-market fit, you must design the underlying architecture so it can eventually evolve into a reliable system." — Source: [Unsupervised Learning]
- On Leveraging Trends: "We didn't invent cloud computing or big data. We leveraged those existing trends to provide a platform, focusing on where we could add value rather than reinventing the stack." — Source: [SiliconAngle]
- On Math Fundamentals: "Work to learn all you can in your math classes. It provides the necessary foundation for advanced engineering and artificial intelligence." — Source: [ACM ByteCast]
- On Dual Perspectives: "Being involved in both teaching and building provides immense value. Apply theoretical knowledge to real-world software problems early on." — Source: [Berkeley BAIR]
- On the Translational Gap: "There is a massive translational gap between producing an academic research paper and delivering industry-ready software that people can rely on daily." — Source: [MLOps Coffee Sessions]
- On Time Management: "To handle a heavy workload across research and industry, block off entire days for specific tasks to ensure deep focus." — Source: [B2BaCEO]
- On Practical Interests: "My path started with an interest in video games, which led to programming because it allowed for quick, visible experimentation." — Source: [Unsupervised Learning]
- On User Validation: "Always validate new abstractions with many potential users early in the process to prevent building something theoretical but useless." — Source: [Databricks Blog]
Part 4: Data Engineering and The Lakehouse
- On the Cloud-First Bet: "We made a strategic bet to build a SaaS platform on the cloud rather than selling on-premises software. It allowed us to offer a managed experience." — Source: [Data + AI Summit]
- On Data Quality: "Your AI is only as good as the data you put into it. The bottleneck is rarely the model; it is the data pipeline." — Source: [SiliconAngle]
- On Observability: "Assessing the features you need to meet the availability requirements of data users is critical. This is where data observability comes in." — Source: [Monte Carlo Data]
- On the Lakehouse Architecture: "We had to choose between the scale of the lake and the speed of the database. The Lakehouse brings the two together." — Source: [Databricks Blog]
- On ETL Foundations: "The most common use cases remain data transformation and ETL. That’s what needs to be done to prepare data for any interesting application." — Source: [SiliconAngle]
- On Declarative Pipelines: "Data engineering needs to become end-to-end declarative. Users should define what they want the data to look like, and the engine handles the execution." — Source: [Databricks Blog]
- On Interactivity: "Users value the ability to query data interactively and iterate quickly. Engineering should always aim to reduce the barrier to entry." — Source: [ACM ByteCast]
- On Ephemeral Storage: "With Lakebase, agents can spin up ephemeral databases to fulfill complex tasks and then tear them down, maintaining a single source of truth." — Source: [Data + AI Summit]
- On Universal Formats: "UniForm allows data stored in Delta Lake to be read as Apache Iceberg or Apache Hudi without moving or copying the data." — Source: [Data + AI Summit]
- On Functional Programming: "Using Scala for Spark allowed for concise syntax and the ability to build powerful Domain Specific Languages for data manipulation." — Source: [Unsupervised Learning]
Part 5: Rethinking Large Language Models
- On Reasoning vs. Facts: "The biggest challenge with LLMs is that they combine reasoning with facts. We want to decouple them—using the LLM for reasoning and the data platform for the facts." — Source: [Unsupervised Learning]
- On Hallucinations: "Treating models as databases leads to hallucinations. Grounding models in external, retrieved data is the only reliable path to factual accuracy." — Source: [No Priors]
- On Instruction Following: "Our Dolly model showed how to create instruction-following capabilities with minimal data and compute, proving you don't always need massive parameters." — Source: [Databricks Blog]
- On Foundation Models as Processors: "Foundation models are the new CPUs. They are the base reasoning processors that execute instructions within a larger software stack." — Source: [Stanford DAWN]
- On AGI: "A form of AGI is already here—it just looks like highly efficient, non-human pattern matching rather than the sci-fi version of human consciousness." — Source: [Berkeley BAIR]
- On Personifying Agents: "Do not treat AI agents as digital colleagues. Personifying them leads to security risks and poor engineering practices." — Source: [Unsupervised Learning]
- On AI as a Tool: "View language models as powerful scientific and engineering tools that augment human intelligence, rather than entities trying to mimic it." — Source: [B2BaCEO]
- On Manual Annotation: "As models get better at following programmatic instructions, the heavy reliance on manual human data annotation will decrease." — Source: [No Priors]
- On Open Source AI: "Open-source models are essential to ensure the industry does not become entirely dependent on closed APIs controlled by a few companies." — Source: [Databricks Blog]
Part 6: System Design and MLflow
- On Open Interfaces: "The most fundamental principle is that the system should define general interfaces for each abstraction so users can bring their own code." — Source: [MLOps Coffee Sessions]
- On Framework Agnosticism: "MLflow is designed to work with any ML library and any deployment environment. Tying users to one framework slows down experimentation." — Source: [Databricks Blog]
- On Modularity: "Users can adopt one, some, or all components of the platform. We avoid forcing a rip-and-replace strategy on existing infrastructure." — Source: [Stanford DAWN]
- On Extensibility: "Because it uses open interfaces, the community can easily add support for new artifact stores or deployment targets like Kubernetes." — Source: [SiliconAngle]
- On Scaling Development: "A user can start tracking metrics locally with two lines of code, and scale that exact same interface to back an industrial database." — Source: [Data + AI Summit]
- On Reproducibility: "Rather than enforcing a specific execution environment, use conventions. The MLproject format simply specifies the environment and entry point." — Source: [Databricks Blog]
- On Standardizing the 'How': "The goal is to standardize how we track, package, and deploy, without restricting what algorithms or math the data scientists use." — Source: [MLOps Coffee Sessions]
- On Simple Primitives: "Instead of complex, proprietary data formats, rely on universal standards like REST APIs, CLI commands, and plain YAML text files." — Source: [Databricks Blog]
- On Walled Gardens: "We built MLflow specifically to avoid the walled garden nature of the internal platforms used by large consumer tech companies." — Source: [SiliconAngle]
- On Managing Abstractions: "When creating a new system layer, be extremely picky about what features go in to prevent the codebase from becoming overly complex." — Source: [Unsupervised Learning]
Part 7: Programming Over Prompting (DSPy)
- On Prompt Engineering: "Hand-tuning prompts is an unscalable and brittle process. It breaks as soon as you change the underlying model." — Source: [DSPy GitHub]
- On Declarative Logic: "Instead of writing prompts, developers should write Python code that defines the declarative logic and workflow of the system." — Source: [Stanford DAWN]
- On Separating Concerns: "By separating the program's structure from the specific prompt strings and weights, you can easily swap foundation models without rewriting code." — Source: [Unsupervised Learning]
- On Model Compilers: "Just as a compiler optimizes code for a specific hardware chip, we need systems that compile declarative logic into the best possible prompts." — Source: [Berkeley BAIR]
- On Self-Improving Pipelines: "Optimizers can automatically generate high-quality instructions and demonstrations for your agents based on a few initial examples." — Source: [DSPy GitHub]
- On Model Efficiency: "Optimization allows developers to make smaller, cheaper open-source models perform as well as massive, expensive APIs." — Source: [No Priors]
- On Modular Agents: "By treating AI agents as modular programs rather than black-box text generators, behavior becomes more predictable and easier to debug." — Source: [Stanford DAWN]
- On Usable ML: "The mission is to make machine learning accessible to domain experts who know the logic but aren't prompt engineers." — Source: [ACM ByteCast]
- On Performance Benchmarks: "We should measure the time and cost required to reach a specific accuracy threshold, rather than just measuring raw hardware throughput." — Source: [Berkeley AMPLab]
Part 8: Compound AI Systems and Agentic Workflows
- On Compound AI Systems: "We are seeing a fundamental shift. A system that combines models with search, tools, and proprietary data is what actually solves business problems." — Source: [Data + AI Summit]
- On Single Models: "A single monolithic language model is often insufficient for complex enterprise tasks. Reliability requires architectural integration." — Source: [Unsupervised Learning]
- On Agent Topologies: "We are moving toward complex topologies where multiple agents interact. A system can have one agent act as a researcher and another as a critic." — Source: [DSPy GitHub]
- On Production-Ready Agents: "Enterprise data agents must be able to query massive datasets with high accuracy, requiring deep integration with the storage layer." — Source: [Databricks Blog]
- On the Unsexy Work: "The most vital parts of building AI agents are the unsexy components: tracking metrics, evaluating performance, and ensuring governance." — Source: [B2BaCEO]
- On Agent Bricks: "The world is moving from chatbots to agents. We need frameworks that provide the workflow to build agents that reason and call tools autonomously." — Source: [Data + AI Summit]
- On Late Interaction: "ColBERT's late interaction mechanism allows for the expressiveness of deep models with the speed of traditional search engines." — Source: [Stanford DAWN]
- On the Production Pipeline: "Instead of just focusing on model architecture, engineering teams must focus on the entire pipeline: data collection, cleaning, and deployment." — Source: [MLOps Coffee Sessions]
- On the Future of AI Value: "The next massive wave of commercial value in AI will come from integrated compound systems, not just incrementally better parameter counts." — Source: [Data + AI Summit]
- On Data Intelligence: "The ultimate goal is a platform that uses AI to understand the semantics of a company's data, allowing natural language to drive complex operations." — Source: [Databricks Blog]