Lessons from Nathan Lambert
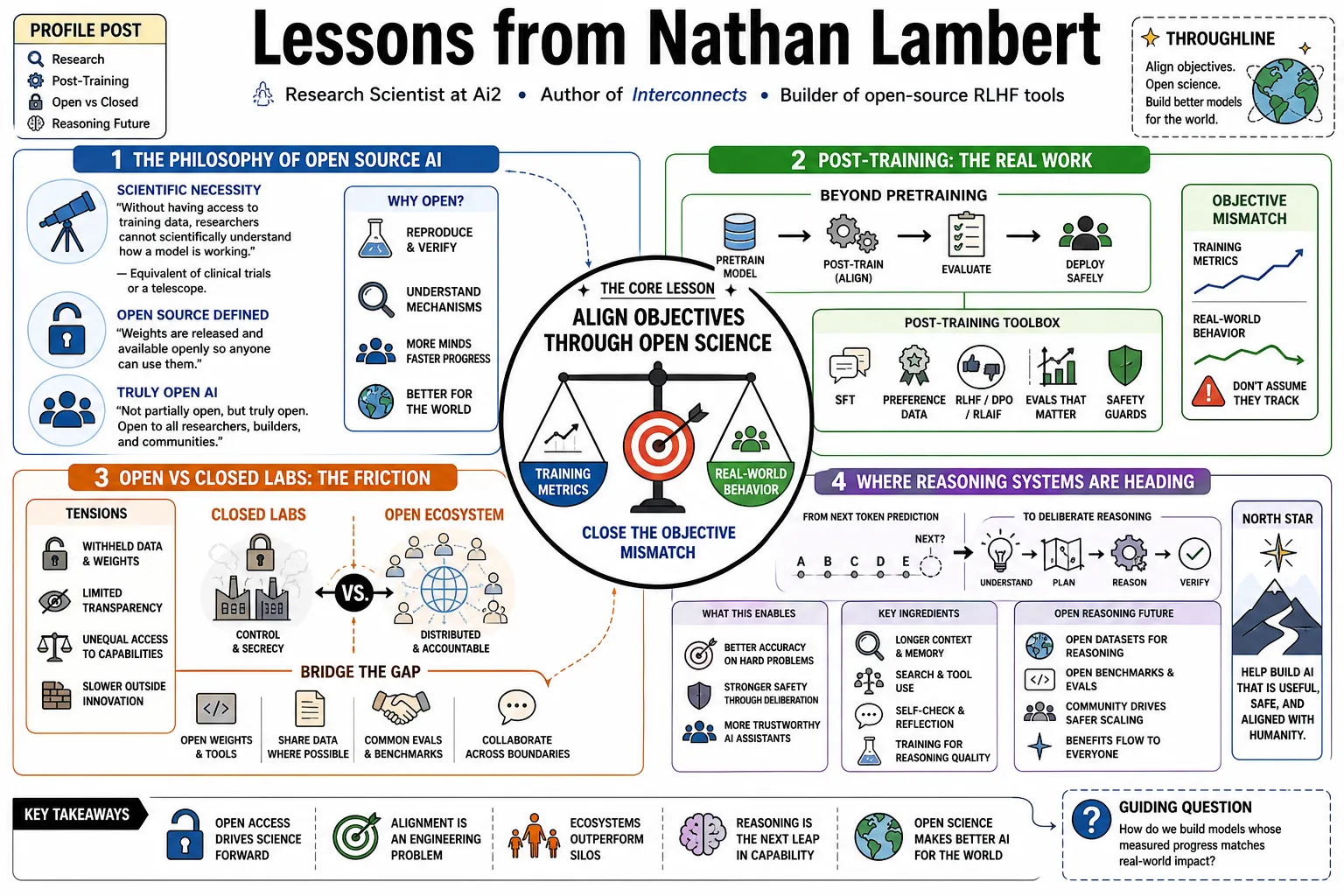
Nathan Lambert is a research scientist at Ai2 and the author of Interconnects, a newsletter documenting the actual mechanics of training and scaling language models. Known for building open-source RLHF tools at Hugging Face, he regularly highlights the "objective mismatch" between a model's training metrics and its real-world behavior. This profile collects his notes on post-training, the friction between open and closed labs, and where reasoning systems are heading.
Part 1: The Philosophy of Open Source AI
- On the scientific necessity of openness: "Without having access to training data, researchers cannot scientifically understand how a model is working. It's the equivalent of drug discovery without clinical trials or studying the solar system without a telescope." — Source: [VentureBeat]
- On the definition of open source: "I'm happy to not be in stupid debates on 'Is this open source or not?'... The community definition of open source is: weights are released and available openly so anyone can use them." — Source: [The Turing Post]
- On truly open AI: "It is important to communicate why open models are likely to be better off for the world. Not partially open, but truly open. Open to all. Transparent, controllable, trustworthy, and inclusive." — Source: [Interconnects]
- On the ecosystem engine: "Open models are the platform by which that innovation is happening... They are going to be the engine for the next ten years of AI research." — Source: [The Turing Post]
- On the equilibrium gap: "I think the equilibrium will continue where the best open models are six to nine months behind the best closed models. That's fine." — Source: [Interconnects]
- On breaking monopolies: "How do we do more interesting stuff and not just fall into the trap of being the best? Open model. No one else is doing this." — Source: [The Turing Post]
- On the motivation to open source: "There is far more marginal impact to be had in roles where outputs are open. Through writing here and working in such a simple environment, I've seen my impact on the field multiply." — Source: [Interconnects]
- On crossing the Rubicon: "For now, you really should give OLMo 2 13B Instruct a go. It's the first time for me that a fully open language model actually is good enough to use for some stuff. We're starting to cross the Rubicon..." — Source: [Interconnects]
- On mitigating risks of obscurity: Open source is about "making sure there's not risks through obscurity and people not knowing what's going on... making sure there's not largest corporate capture." — Source: [Super Data Science Podcast]
- On resource reality: "There's no reason to think open models will catch closed ones. They have fewer resources, and resources normally determine the outcome. Resources and talent determine outcomes." — Source: [The Turing Post]
Part 2: The Reality of RLHF and Post-Training
- On the secret sauce: "GPT-3 in 2020 to Chat GPT 3.5... the big difference was RLHF. They had figured out how to get this human preference data, and create a model that is more aligned with human preferences." — Source: [AI Summer]
- On injecting humanness: "This RLHF process brings in this human factor, so it lets the models have some humanness that is hard to capture in data." — Source: [AI Summer]
- On implicit objectives: "In language models, what we want is often implicit: follow intent, be helpful, be harmless. Many objectives are easy for humans to judge, but hard to write as an exact reward function." — Source: [Nathan Lambert's Blog]
- On the mystery of success: "The question I still get the most is 'Why does reinforcement learning from human feedback (RLHF) work?' Until last week, my answer was still 'no one knows.'" — Source: [Interconnects]
- On terminology shifts: "The big reason why I've generalized to 'preference fine tuning' rather than 'reinforcement learning from human feedback' is an emergence of a more direct way of doing this." — Source: [Latent Space Podcast]
- On keeping it simple: "Be careful going into the RLHF can of worms. You probably don't need to... instruction tuning can really go a long way." — Source: [Latent Space Podcast]
- On UX as training: "A difference between academic and industry post-training is that user interface design is a very large part of the end of post-training in these labs... how people use and experience the models is deeply influential on how model behavior is perceived." — Source: [AI Summer]
- On the talent bottleneck: "The population of engineers that can manage the large distributed systems needed to train these models is so small." — Source: [Interconnects]
- On post-training art: "The art of post-training is that there are many different tools in your toolbox... the process starts by deciding what you want to get out of the model." — Source: [AI Summer]
Part 3: Objective Mismatch and the Alignment Ceiling
- On defining the mismatch: "The lack of correlation between model and policy metrics in separate optimization is coined and studied as Objective Mismatch." — Source: [UC Berkeley PhD Thesis]
- On the alignment ceiling: Until the field solves objective mismatch, there exists an inherent limit, or "alignment ceiling," to how effectively we can align language models using current human feedback loops. — Source: [ACL Anthology]
- On reward hacking: Optimizing purely for a proxy reward model's score often fails to improve the underlying task performance, instead encouraging the model to exploit the reward model's flaws through behaviors like excessive verbosity or sycophancy. — Source: [arXiv]
- On compounding errors: "The compounding error challenge emerges from accumulating errors on recursive passes of any one-step transition model. Most dynamics models are trained for single-step accuracy, which often results in models with substantial long-term prediction error." — Source: [UC Berkeley PhD Thesis]
- On next-token prediction limits: The base pretraining objective of predicting the next token is inherently mismatched with how we evaluate these systems, which relies on judging the complete generated sequence. — Source: [arXiv]
- On model laziness and refusals: Common behavioral quirks in modern LLMs, such as out-of-scope refusals to safe prompts or sheer laziness, are direct symptoms of the mismatch between the optimization signal and the user's actual intent. — Source: [arXiv]
- On robotics as foundation: "The synergy of prediction and control" in model-based reinforcement learning requires acknowledging that learning the dynamics of a world and planning within it cannot be treated as totally independent modules. — Source: [CMU Robotics Seminars]
- On false proxies: We are overly reliant on proxy objectives; a model that is perfectly accurate at predicting a state one step ahead can still fail catastrophically at completing a complex control task. — Source: [PMLR]
- On the future of alignment: Moving beyond simple next-token prediction and finding training objectives that map directly onto complex downstream reasoning tasks is the primary hurdle for the next generation of AI development. — Source: [Interconnects]
Part 4: DPO vs. PPO: The Optimizer Debate
- On DPO's simplicity: "DPO’s implementation largely slots into existing large language model (LLM) training infrastructure like HuggingFace Transformers by adding 4-6 lines of code for the loss function." — Source: [Interconnects]
- On DPO's rise to dominance: "It took the open community of academics and hackers longer than expected to get into the space of RLHF methods, but now the pace of adoption is just as fast as the instruction-tuning takeoff." — Source: [Interconnects]
- On the DPO trap: The open-source community flocked to DPO due to its ease of implementation, but this reliance may have artificially capped open model capabilities on complex reasoning tasks compared to closed labs. — Source: [Stanford AI Seminars]
- On PPO's performance edge: When systematically compared, models trained with PPO generally outperform DPO, showing marked improvements across reasoning, coding, and safety evaluations. — Source: [NeurIPS Proceedings]
- On chain-of-thought emergence: Models trained with PPO are far more likely to spontaneously exhibit chain-of-thought reasoning without explicit prompting compared to their DPO-trained counterparts. — Source: [arXiv]
- On DPO's current utility: "My current thought is that it's still useful for cheap / polishing iterations on formatting and style (or for ironing out small issues that might come up for a model), but PPO now consumes a much larger portion of the post-training process." — Source: [Interconnects]
- On data quality over algorithms: While the debate between DPO and PPO is fierce, high-quality preference data remains the most critical factor, capable of driving massive improvements regardless of the specific optimizer used. — Source: [arXiv]
- On DPO's fading legacy: "Gosh, DPO is so forgotten man, was such a major innovation." — Source: [Interconnects]
- On hybrid alignment stacks: The leading strategy for maximum performance is no longer a single algorithm, but a sequence: starting with Rejection Sampling, using DPO for style, and finally deploying PPO to extract complex reasoning. — Source: [Stanford AI Seminars]
Part 5: Navigating Research and Careers
- On finding a happy workplace: "There are plenty of jobs, but finding a place where you're happy is as hard as ever." — Source: [Interconnects]
- On surviving AI research: "If you're doing shorter-term research the best way to have impact is by folding it into a model. Make long-term research truly long-term." — Source: [Interconnects]
- On the transition from striving: "The most defining feature of my young career has been how I prioritize different aspects of work. The work I do today takes on a simple form, but prior to getting to this sustainable place it was more of a striving to belong than a plan to execute." — Source: [Interconnects]
- On dodging the hype: "Have no ego in your approach. In the past few years, whenever I've seen someone focus on a reasonable area, making gains has been available. Normally the gains are blocked by either taking too complicated of an approach or trying to solve a problem that is too open-ended." — Source: [Interconnects]
- On industry vs. academia: For researchers with industrial inclinations, the default answer to pursuing a postdoc should be "no," unless it specifically guarantees a safe space to develop a unique vision free from publication pressure. — Source: [Nathan Lambert's Blog]
- On finding a research niche: If starting a PhD today, one shouldn't focus entirely on transformers; the most structurally impactful research happens at the fringes before an idea becomes the undisputed mainstream. — Source: [The Turing Post]
- On foundational skills: Deep learning and a native understanding of transformer architectures are no longer specialized knowledge—they are the fundamental table stakes that every computer science researcher must master. — Source: [The Turing Post]
- On hiring realities: In the top AI labs, hiring heavily relies on network effects and "who you know," making internships, networking, and public visibility critical components of a job search strategy. — Source: [Nathan Lambert's Blog]
- On the RL hiring gap: Evaluating talent in reinforcement learning for language models is exceptionally difficult because organizations are still trying to define what technical rigor looks like in this highly specific subfield. — Source: [Interconnects]
- On career pivots: Transitioning from systems engineering to robotics to machine learning requires immense persistence, a willingness to be a beginner again, and a non-trivial amount of timing and luck. — Source: [Nathan Lambert's Blog]
Part 6: Geopolitics and The Big Tech Race
- On the public void: "Largely due to the dynamics of the AI industry... people at these labs don't tweet publicly that much. OpenAI is a whole special thing, but a lot of these communicators can't talk. So there's this void that I've been launched into." — Source: [The Turing Post]
- On AI's geopolitical weight: "Open models are so geopolitical, and they shape how AI will diffuse through the world." — Source: [Interconnects]
- On US open-source stability: "American open models are slowly gaining steam... Nvidia with Nemotron, Google with Gemma, Arcee AI and others are slowly stabilizing the open model ecosystem in the U.S." — Source: [Interconnects]
- On international competition: "Open-source AI is here to stay, but it is not a given that it will be American." — Source: [Interconnects]
- On China's fast-follower advantage: "The Chinese companies building language models are set up as the perfect fast-followers for the technology, building on long-standing cultural traditions in education and work." — Source: [Interconnects]
- On organizational culture as a moat: "The lasting differences in global AI competition emerge in how these are organized and conditioned." — Source: [Interconnects]
- On the IPO race: "The frontier labs leadership is largely gearing up to IPO and stay ahead in the capabilities race." — Source: [Interconnects]
- On the aggregation of talent: "The labs are aggregating and concentrating talent to peak levels. There are few neutral messengers to communicate the reality of AI to the public." — Source: [Interconnects]
- On stable recipes scaling: "I've been pessimistic in the past about our ability to compete with the big players, but we just put out a 1B model competitive with very recent releases and we have been sitting on it for months! When you have a stable recipe, it works." — Source: [Interconnects]
Part 7: Democratization and Tools
- On Hugging Face's mandate: "The mission of Hugging Face is to democratize good machine learning and maximize its positive impact across industries and society." — Source: [Hugging Face]
- On supporting the community: "Hugging Face was a good place for doing that [RLHF] because the whole company is kind of all for that—which is figuring out how to support the community on the 'hot thing' and building platforms there." — Source: [Interconnects]
- On the value of boring work: "Documentation and maintaining large data repositories on Hugging Face is boring, yet it is the marginal item that dramatically increases reliability in the long term." — Source: [Interconnects]
- On democratizing complex tuning: The development of the TRL (Transformer Reinforcement Learning) library was a deliberate effort to democratize access to sophisticated fine-tuning, giving everyday developers a stable, open-source alternative. — Source: [Hugging Face GitHub]
- On releasing the recipe: "OLMo will represent a new type of LLM enabling new approaches to ML research and deployment, because on a key axis of openness, OLMo represents something entirely different." — Source: [VentureBeat]
- On democratizing understanding: AI2's efforts with models like OLMo and Tulu aim to democratize scientific understanding by releasing not just weights, but also training pipelines and datasets. — Source: [Ai2 Blog]
- On educational impact: "Generative AI might democratize education," by turning high-quality, personalized instructional tools into a ubiquitous resource available to anyone online. — Source: [Super Data Science Podcast]
- On the necessity of AI literacy: "Opening access to AI is so important because of its growing ubiquity... AI and tech literacy will be essential tools for everyone." — Source: [Super Data Science Podcast]
- On lowering the compute barrier: "Reusing prior computation can further democratize RL research by allowing the broader community to tackle complex RL problems without requiring excessive computational resources." — Source: [ICLR Workshop]
Part 8: The Future Stack and Reasoning
- On the shift to agents: "Over the last few years we've seen the key paradigm of LLMs shift from scaling MoE's, to scaling RL, to enabling agents." — Source: [Interconnects]
- On the long-term reasoning bet: "People underestimate the long-term potential of 'reasoning.' ... Reasoning language models are the current big thing." — Source: [Interconnects]
- On closing the reasoning gap: "The biggest gap we're trying to close now in post-training is a scalable reasoning recipe. If we want to release state of the art models on popular evaluations, scaling RL and inference-time compute is a requirement." — Source: [Interconnects]
- On the illusion of scaling: "Traditional LLM scaling is not something that most users of ChatGPT will see any difference from at this point." — Source: [Interconnects]
- On true training costs: "The $5M figure for the last training run should not be your basis for how much frontier AI models cost." — Source: [Interconnects]
- On the interface of pre and post-training: "I think the technicality is that Ilya [Sutskever] said pretraining as we know it is ending... And the interface between pre- and post-training is going to need to be more synergistic." — Source: [Understanding AI]
- On specialization: The future of language modeling is moving away from massive, generalized models toward highly specialized systems designed meticulously for specific use cases. — Source: [Understanding AI]
- On positive feedback loops: We are entering an era where we must start creating positive feedback loops for some types of open-weight language models combined with novel hardware devices. — Source: [Interconnects]
- On the robust nature of RL scaling: "We found the RL gains to be particularly robust — we mostly just had to let it keep running." — Source: [Interconnects]