Lessons from Noam Brown
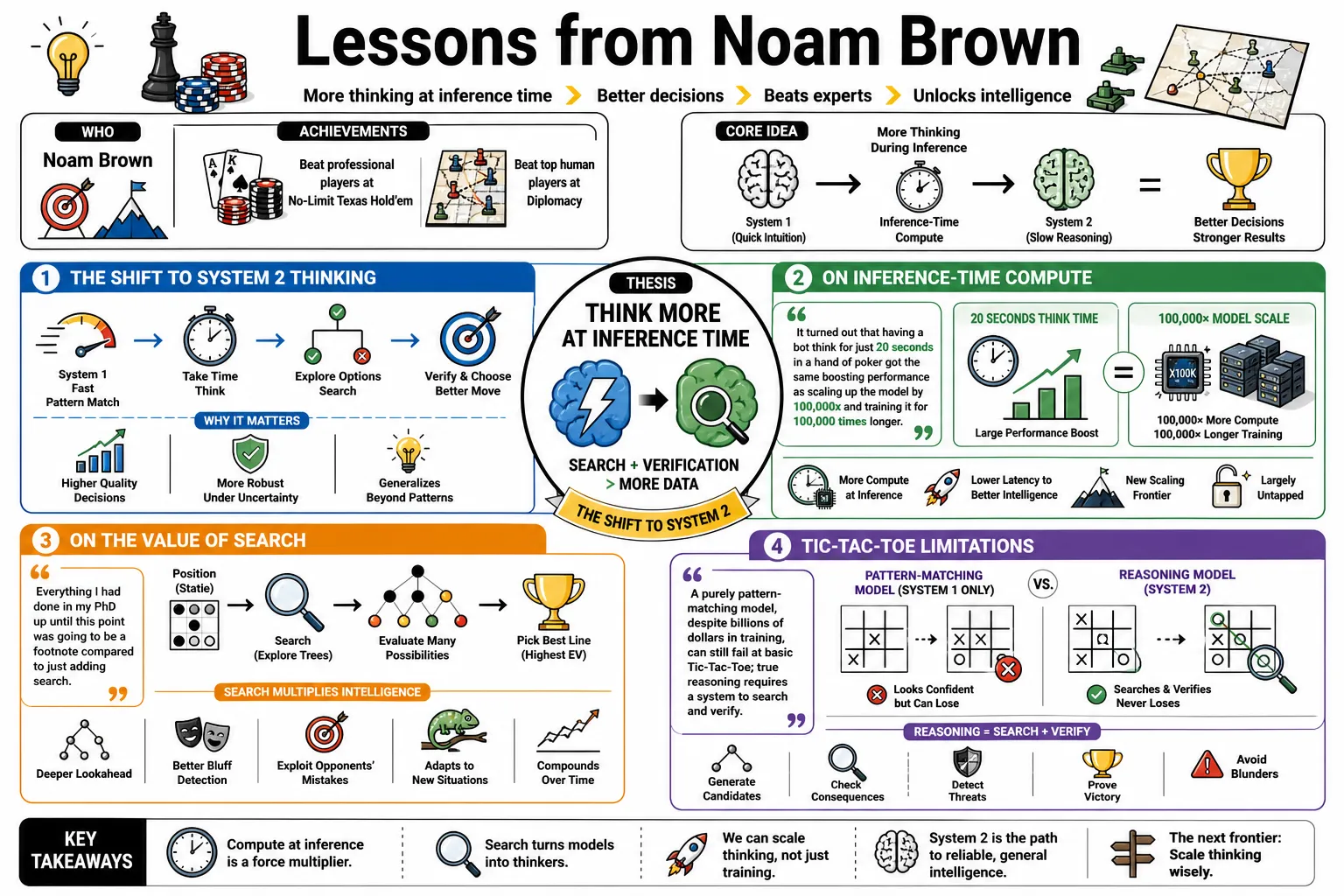
Noam Brown built the first AI systems to beat professional players at No-Limit Texas Hold’em and Diplomacy. He proved that giving models time to "think" during inference often outperforms simply training them on more data. This tracks his work from applied game theory to the reasoning architecture behind OpenAI's o1.
Part 1: The Shift to System 2 Thinking
- On Inference-Time Compute: "It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer." — Source: [TED AI 2024]
- On the Next Frontier of Scaling: "We're no longer constrained to just scaling up system one training; now we can scale up system two thinking as well. And the beautiful thing about scaling up in this direction is that it's largely untapped." — Source: [OpenAI Distinguished Lecture Series]
- On the Value of Search: "Everything I had done in my PhD up until this point was going to be a footnote compared to just adding search." — Source: [VentureBeat]
- On Tic-Tac-Toe Limitations: A purely pattern-matching model, despite billions of dollars in training, can still fail at basic Tic-Tac-Toe; true reasoning requires a system to search and verify its own logic rather than simply predict the next token. — Source: [Dwarkesh Podcast]
- On Paying for Patience: "Raise your hand if you would be willing to pay more than $1 for a new cancer treatment... How about $1,000? How about a million dollars?" — Source: [TED AI 2024]
- On Thinking vs. Reacting: The transition from pre-computed policies taking 30 milliseconds to act to search mechanisms taking minutes to ponder represents the missing piece in giving AI a human capability to navigate difficult spots. — Source: [TED AI 2024]
- On the Economics of Reasoning: If you want a better model, you can either spend billions scaling up pre-training, or scale up test-time compute from a penny to ten cents per query, a trade-off that is increasingly worth making. — Source: [Dwarkesh Podcast]
- On Algorithm Design: The current era of AI research is shifting away from relying purely on brute-force scaling and moving toward targeted algorithmic breakthroughs in reasoning and test-time search. — Source: [Dwarkesh Podcast]
- On Real-Time Planning: When an AI encounters a highly novel or difficult state, it cannot rely entirely on memorized intuitions; it must construct a unique, on-the-fly plan to maneuver successfully. — Source: [Lex Fridman Podcast]
- On Verifiability: The frontier of reasoning models is pushing past easily verifiable domains like competitive coding or math into much more subjective, open-ended research tasks. — Source: [X (Twitter)]
Part 2: Lessons from Poker and Imperfect Information
- On Chess vs. Poker: "Poker is fundamentally different from chess because you don't have perfect information. You don't know what cards your opponents are holding." — Source: [Lex Fridman Podcast]
- On Real-World Application: "Life is not chess. In real-world problems, the pieces are not lined up neatly for all to see... Poker may not be a perfect representation of these problems, but it’s a lot closer." — Source: [Pittsburgh Supercomputing Center]
- On the Messiness of Multiplayer: While two-player poker is mathematically solvable, six-player poker is a giant mess where the strict theoretical guarantees of Nash equilibrium no longer perfectly apply. — Source: [Lex Fridman Podcast]
- On Initial Assumptions: AI systems like Libratus start by knowing nothing about the game, playing randomly against a copy of themselves for trillions of iterations until sophisticated strategies emerge organically. — Source: [Creative Next Podcast]
- On Professional Disruption: "They were coming to me for career advice. Because they were realizing like, 'Oh, you know, our days are numbered as professional poker players.'" — Source: [SuperDataScience Podcast]
- On Defying Folk Wisdom: Pluribus continuously challenged professional poker lore, demonstrating that "donk betting" (leading out when you were not the preflop aggressor) is incredibly effective, rather than a mistake. — Source: [CardPlayer Magazine]
- On the Complexity of the Unseen: The defining challenge of imperfect information games is that an agent must consider both the current board state and the entire distribution of potential hands the opponent might hold based on their past actions. — Source: [Science]
- On Self-Play Limitations: In multiplayer imperfect-information environments, self-play alone is insufficient to guarantee optimal outcomes, requiring new abstractions to handle the massive branching factor. — Source: [Science]
- On the Goal of the Game: The primary milestone in solving imperfect-information games was not merely to win money, but to establish a foundation for tackling real-world scenarios where actors must make decisions with incomplete visibility. — Source: [CardPlayer Magazine]
Part 3: Game Theory and Nash Equilibrium
- On Being Unbeatable: "I think this idea that there is an unbeatable strategy in poker and that if you could find it... then you just, you know, make infinite money. Basically, I thought that was a pretty interesting concept." — Source: [SuperDataScience Podcast]
- On Nash Expectations: "If I'm playing the Nash equilibrium, even if you know what my strategy is... I'm still unbeatable in expectation." — Source: [Lex Fridman Podcast]
- On the Illusion of the 'Best' Move: Game theory dictates that in many scenarios, there is no single best action; optimal play requires a probabilistic distribution of choices to avoid becoming predictable and exploitable. — Source: [Science]
- On Balancing Equilibrium and Exploitation: Advanced AI architectures balance playing a mathematically sound equilibrium with the ability to model opponents, dynamically best-responding to exploit human weaknesses. — Source: [SuperDataScience Podcast]
- On Real-World Nash Applications: The equilibrium concepts originally developed by von Neumann and Nash are directly applicable to major real-world domains like cybersecurity, pricing strategies, and auction design. — Source: [CardPlayer Magazine]
- On Safe Strategies: Achieving a superhuman level in games of hidden information requires a defensive baseline, ensuring the strategy you deploy cannot lose in the long run regardless of what the opponent attempts. — Source: [Lex Fridman Podcast]
- On Approximation: Because the game tree of No-Limit Texas Hold'em has more decision points than atoms in the universe, an AI must compute a rigorous approximation of the Nash equilibrium rather than solving it perfectly. — Source: [Pittsburgh Supercomputing Center]
- On Abstraction Limits: While early poker bots relied heavily on simplifying the game into abstractions to compute strategies beforehand, this approach hits a ceiling when opponents discover the system's blind spots. — Source: [Lex Fridman Podcast]
- On End-Game Solving: The breakthrough of Libratus was its ability to compute the Nash equilibrium for the late stages of a poker hand in real-time, adapting instantly to unique bet sizes the humans tried to use to confuse it. — Source: [Lex Fridman Podcast]
Part 4: The Psychology of Strategy and Bluffing
- On Unpredictability: "Being unpredictable is a huge part of playing poker… you have to be unpredictable; you have to bluff. If you don’t have a strong hand you have to check; if you do have a strong hand you can’t tip off the other players." — Source: [Pittsburgh Supercomputing Center]
- On Creating Discomfort: "I think one of the key strategies in poker is to put the other person into an uncomfortable position. And if you're doing that, then you're playing poker well." — Source: [Lex Fridman Podcast]
- On Over-Betting: "Then suddenly, the bot bets $20,000 into a $500 pot. The bot is basically saying, 'I'm either bluffing or I have the best hand.'" — Source: [Creative Next Podcast]
- On Adapting to Human Surroundings: "If you're going to play in this human game, you have to somehow adapt to the human surroundings and the human playstyle. And to win you have to adapt." — Source: [Lex Fridman Podcast]
- On Machinelike Vulnerability: Treating all other human participants purely like predictable, logical machines in a social game is a recipe for ending up isolated and playing very poorly. — Source: [Lex Fridman Podcast]
- On Reading Opponents: The AI does not read physical tells or sweat; it reads the structural tells hidden in betting patterns and sizing to map out the exact psychological boundaries of the opponent. — Source: [Lex Fridman Podcast]
- On Continuous Pressure: By deliberately varying its bet sizes across a massive spectrum, far wider than human professionals are used to processing, an agent can exhaust a human's cognitive resources. — Source: [VentureBeat]
- On Human Tilt: Unlike human professionals who suffer from emotional fatigue or tilt after a bad beat, an AI's psychological advantage is its unrelenting mathematical consistency over weeks of continuous play. — Source: [SuperDataScience Podcast]
- On the Purpose of a Bluff: Bluffing is not merely a tool to win a pot you do not deserve, but a necessary mathematical counterweight that forces your opponent to pay off your winning hands. — Source: [Lex Fridman Podcast]
Part 5: Diplomacy, Language, and Trust
- On the Ultimate Benchmark: "I chose Diplomacy because we felt it was the hardest game to make an AI for, and then once we made an AI for it, it kind of felt like there’s just no games left that are worth working on." — Source: [SuperDataScience Podcast]
- On Building Trust: "Diplomacy is really a game about trust. It’s about being able to build trust with players in an environment that encourages you to not trust anybody." — Source: [Lex Fridman Podcast]
- On Sparing Deception: The most effective players in trust-based environments do not constantly betray their allies; they lie incredibly sparingly to maximize the impact of their deception. — Source: [Lex Fridman Podcast]
- On Honesty by Default: Cicero was deliberately engineered to be largely honest and consistent, sending messages that actively aligned with the strategic moves it fully intended to execute. — Source: [Lex Fridman Podcast]
- On People vs. Pieces: In highly social negotiation games, the strategic focus shifts radically; the game becomes far more about managing the people than moving the pieces on the board. — Source: [Lex Fridman Podcast]
- On Human Preference: "People actually preferred playing our Diplomacy agent than real people, which at the time sounded strange; in hindsight, it’s like, kind of duh." — Source: [Lex Fridman Podcast]
- On Cooperative AI: Diplomacy represented a massive step toward real-world applications because it forced the AI to abandon purely adversarial play and instead actively cooperate and coordinate with human partners. — Source: [Lex Fridman Podcast]
- On Language as a Weapon: "Diplomacy requires AI to negotiate, form alliances, and engage in deception through natural language, which is much more complex than playing by fixed rules." — Source: [Lex Fridman Podcast]
- On Passing the Turing Test: "The idea that an AI could play in a natural language game with people for hours upon hours and that people not realize that it was a bot was revolutionary... then two weeks later ChatGPT came out." — Source: [TED AI 2024]
- On Intent Inference: To succeed in negotiation, an AI model cannot merely generate text; it must actively analyze the intent behind the human's messages and cross-reference that intent against its own strategic planner. — Source: [Nature]
Part 6: Scaling Laws and the Economics of Compute
- On the Word of the Decade: "The incredible progress in AI over the past five years can be summarized in one word: scale... but the frontier models of today are still based on the same transformer architecture introduced in 2017." — Source: [TED AI 2024]
- On Continued Acceleration: "At some point, the scaling paradigm breaks down... I am more confident than ever that AI will not plateau. In fact, I believe that we will see AI progress accelerate in the coming months." — Source: [X (Twitter)]
- On the Apollo Scale: "This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed." — Source: [LifeArchitect]
- On Diminishing Returns: The traditional paradigm of simply feeding a model exponentially more data is approaching an economic and physical asymptote, necessitating a pivot to new architectural paradigms like inference scaling. — Source: [Dwarkesh Podcast]
- On the Cost of Intelligence: Shifting compute from the training phase to the inference phase completely alters the economics of intelligence, allowing developers to allocate massive resources dynamically to the most complex queries. — Source: [TED AI 2024]
- On Obvious Breakthroughs: "Everything's obvious in retrospect, but at the time it was not obvious that [planning] would work so well." — Source: [Lex Fridman Podcast]
- On Training Infrastructure: The infrastructure required to pre-train large models has reached a scale where even minor inefficiencies result in millions of dollars of wasted capital. — Source: [Dwarkesh Podcast]
- On Real-Time Compute Budgets: The next major variable for developers will be dictating the thinking budget of an agent, allowing users to actively decide how much compute they want to burn to solve a specific problem. — Source: [TED AI 2024]
- On Paradigm Shifts: The shift from relying purely on the internalized intuitions of massive neural networks to integrating classical search algorithms represents the most significant paradigm shift since the transformer. — Source: [OpenAI Distinguished Lecture Series]
Part 7: General Intelligence and Cognitive Horizons
- On the Pivot to AGI: "Over the course of the project, it kind of became clear to me that if we wanted to get superhuman performance [in Diplomacy], what we really needed was to just achieve AGI, basically." — Source: [SuperDataScience Podcast]
- On 'Feeling' the AGI: "Seeing these creative writing outputs has been a real 'feel the AGI' moment for some folks at OpenAI. The pessimist line lately has been only stuff like code and math will keep getting better. The fuzzy subjective bits will stall. Nope." — Source: [X (Twitter)]
- On the Novel Test: "I think if we could have an AI that actually can write a thought-provoking novel, that's a great sign of intelligence." — Source: [Lex Fridman Podcast]
- On Measuring Intelligence: "I think that if we're at a point where we don't have a way to measure intelligence in humans, it seems pretty hard to have an objective way to measure it in models." — Source: [Lex Fridman Podcast]
- On the End of Scaffolding: Complex agentic workflows and prompt engineering scaffolds will eventually be rendered obsolete as the underlying reasoning capabilities of the base models become inherently stronger. — Source: [Dwarkesh Podcast]
- On Accelerated Timelines: Observing the mathematical reality that language models could effectively employ inference-time search forced a dramatic acceleration in personal timelines regarding the arrival of general intelligence. — Source: [Dwarkesh Podcast]
- On the Broadening of Capabilities: The assumption that reasoning models would remain strictly confined to formal logic and mathematics has been shattered; their capabilities are rising uniformly across creative and subjective domains. — Source: [X (Twitter)]
- On Outperforming Human Experts: A hallmark of incoming AGI is the transition from an AI matching a human expert's intuition to an AI consistently verifying its logic to a degree that an expert cannot immediately refute. — Source: [Dwarkesh Podcast]
- On General Purpose Reasoning: "A lot of my pivot to focusing on general-purpose reasoning systems was inspired by my work on Diplomacy." — Source: [Lex Fridman Podcast]
Part 8: The Philosophy of Research and the AI Industry
- On Self-Motivation: "You have to be self-motivated to pursue these kinds of directions... becoming familiar with machine learning concepts, becoming familiar with PyTorch, being able to demonstrate research aptitude." — Source: [SuperDataScience Podcast]
- On Nontraditional Backgrounds: Entering the cutting edge of AI research does not strictly require a traditional, linear academic path; it requires a demonstrated ability to solve novel problems independently. — Source: [SuperDataScience Podcast]
- On Industry vs. Academia: "I decided, look, this is the better opportunity right now. I'm able to do my best research here, so I'm gonna go with Meta." — Source: [SuperDataScience Podcast]
- On Foundational Goals: The mandate at frontier labs is not necessarily directed at specific, immediate product features, but rather at aggressively advancing the fundamental state of the art. — Source: [SuperDataScience Podcast]
- On the Importance of Focus: Tackling a grand challenge in AI requires resisting the urge to jump between micro-trends, instead committing deeply to a specific, rigorously defined mathematical bottleneck. — Source: [SuperDataScience Podcast]
- On Re-evaluating Old Paradigms: The modern AI landscape heavily rewards researchers who are willing to reconsider abandoned or classical algorithms, like search, and apply them to massive, modern neural architectures. — Source: [Dwarkesh Podcast]
- On the Illusion of Fast Progress: What looks to the public like an overnight, magical breakthrough is almost always the culmination of years of quiet, systemic iteration against a singular metric. — Source: [TED AI 2024]
- On Moving Beyond Games: The historical reliance on zero-sum games as a benchmark for AI research has fulfilled its purpose; the frontier is now entirely focused on open-ended, general intelligence. — Source: [SuperDataScience Podcast]
- On Building the Impossible: Discovering that a neural network could successfully integrate language modeling with strategic planning fundamentally altered the boundaries of what researchers consider computationally possible. — Source: [Nature]
- On the Final Goal: The ultimate objective of AI research is no longer simply building systems that act intelligently; the goal is to build systems that can consistently out-reason humanity in solving our hardest problems. — Source: [TED AI 2024]