Thomas Wolf is the co-founder and Chief Science Officer of Hugging Face, where he helped build the Transformers library that accelerated the widespread adoption of modern machine learning. Drawing from his background in quantum physics and patent law, he has become a central advocate for open-source AI, leading community-driven initiatives like the BigScience project and open robotics. This compilation organizes his perspectives on scaling laws, the technical limits of current AI models, and the democratization of scientific research.
Part 1: The Physics and Patent Law Origins
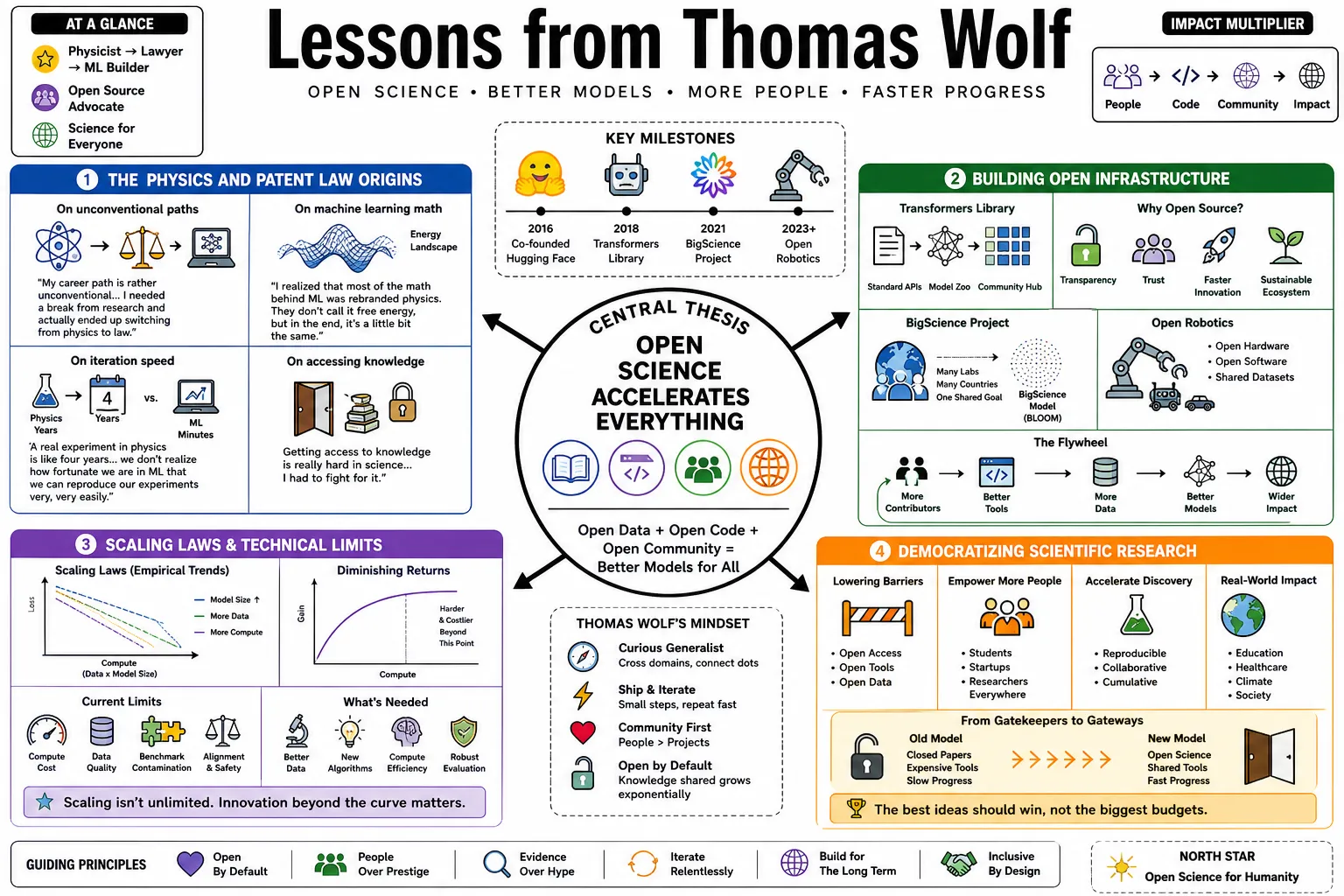
- On unconventional paths: "My career path is rather unconventional... I needed a break from research and actually ended up switching from physics to law." — Source: [Medium]
- On machine learning math: "I realized that most of the math behind ML was rebranded physics. They don't call it free energy, but in the end, it's a little bit the same." — Source: [YouTube]
- On iteration speed: "A real experiment in physics is like four years... we don't realize how fortunate we are in ML that we can reproduce our experiments very, very easily." — Source: [YouTube]
- On accessing knowledge: "Getting access to knowledge is really hard in science... I had to track down these Russian-written articles. I discovered that getting access to knowledge was something super critical to be able to build things." — Source: [Medium]
- On discovering AI: "Over my last years as an attorney, most of the startups I was advising were working on Deep Learning, and this led me to discover the field of Machine Learning and AI." — Source: [Analytics Vidhya]
- On open source as open science: "When I went back to computer science, I discovered this extension of open science which is open source, where basically people don't even just share how to build things, but they share the blueprint." — Source: [YouTube]
- On accelerating discovery: Sharing the exact blueprints of technical systems acts as a massive enabler for others to execute new scientific discoveries. — Source: [YouTube]
- On his legal tenure: Working as a European Patent Attorney exposed him directly to the intellectual property hurdles faced by deep learning startups. — Source: [Medium]
- On leaving law: While he enjoyed the process of drafting patents, the inherent friction of closed intellectual property systems pushed him toward building open tools instead. — Source: [Prometheus Root]
Part 2: The Core Mission of Hugging Face
- On the primary objective: "We are catalyzing and democratizing NLP. We think NLP breakthroughs should benefit everyone and be accessible to the whole community." — Source: [Analytics Vidhya]
- On the library's turning point: "The Transformers library's success was a series of exciting moments. It began with our adaptation of GPT-1... But the real game-changer was Google's release of BERT." — Source: [Analytics Vidhya]
- On responding to users: "We quickly converted BERT to PyTorch, and the community loved it. We then merged our GPT-1 and BERT code into a single library." — Source: [Analytics Vidhya]
- On designing for the unknown: "One of the challenges we face is to anticipate future developments in the field... it can be tricky to design an API and user-experience for things that have not been invented yet." — Source: [Medium]
- On corporate efficiency: "We're extremely efficient, lean... we're just very careful about how much we spend our runway. We just—we're still a very small team." — Source: [YouTube]
- On human augmentation: "I think the most useful applications are where NLP is used to complement and augment humans rather than replace them." — Source: [Medium]
- On the neutral ground: Hugging Face operates as a neutral party in AI, enabling large tech companies to release open models that aid the ecosystem without explicitly endorsing a competitor's platform. — Source: [Hugging Face Blog]
- On fighting monopolies: "An opaque monopoly or oligopoly appear[ing] on a technology as groundbreaking as AI" could severely influence public and political decisions. — Source: [Substack]
- On community demand: "The success of the Transformers library highlighted the community's desire for accessible, high-quality AI tools." — Source: [Analytics Vidhya]
Part 3: Open Source, Democratization, and Community
- On AI as a common good: "Everyone can learn about general relativity, quantum physics... these are like common good knowledge from all humanity. I think AI is a bit the same." — Source: [YouTube]
- On the long game: He is completely confident that the leading models in the next decade will be open source, outpacing proprietary systems through global community effort. — Source: [YouTube]
- On asymmetric knowledge: Closed-source companies absorb everything from open-source research, but they do not share their findings back; despite this, the volume of community output wins out over time. — Source: [Hugging Face Blog]
- On humility: "Working in open source means you need to be quite humble... and you need to be open to criticism." — Source: [YouTube]
- On project stewardship: Maintaining open-source projects requires acting as a "civil servant" to the broader developer base. — Source: [YouTube]
- On releasing models: "Open-sourcing models is not only a marketing strategy but also fosters an ecosystem where the community can contribute, fine-tune, and innovate." — Source: [Analytics Vidhya]
- On model diversity: The best defense against technical stagnation is a diversity of model architectures that can adapt to specialized verticals. — Source: [Hugging Face Blog]
- On the difficulty of research: "I think research is tough; that's also why I do open source sometime—it's kind of easier to do a nice open source project than a nice research project." — Source: [YouTube]
- On shared benefits: "Sharing knowledge benefits everybody." — Source: [Medium]
- On regulation: AI regulation should target the specific applications of the technology rather than restricting the distribution of open-source weights. — Source: [Hugging Face Blog]
Part 4: The BigScience Project and Collaborative AI
- On the BigScience thesis: "The way we think this [AI research] should be done is more like what I’ve seen when I was doing my PhD, which was this very large physics collaboration... like the LHC." — Source: [YouTube]
- On closing the academic gap: The BigScience initiative was designed to reduce the compute gap between universities and industrial labs, ensuring massive models aren't only built behind closed doors. — Source: [TWIML AI]
- On the process over the product: "I think the journey that you follow if it’s a healthy community... is actually much more important in the end than even what we build." — Source: [YouTube]
- On building BLOOM: The initiative proved that a decentralized network of researchers could successfully train a 176-billion parameter language model without a centralized corporate mandate. — Source: [TWIML AI]
- On social infrastructure: Getting over a thousand researchers to align on data governance and model architecture was as challenging and significant as the final code. — Source: [TWIML AI]
- On data transparency: "If you want to understand AI you have to understand how to make good data sets... we have to push people to share them in an open way." — Source: [YouTube]
- On public compute: BigScience relied on public supercomputing infrastructure, specifically the Jean Zay supercomputer in France, rather than private venture capital funding. — Source: [TWIML AI]
- On matching big tech: The project served as a proof-of-concept that an open scientific community could match the engineering scale of major tech corporations. — Source: [TWIML AI]
- On defining Big Science: The goal is to bring the organizational principles of particle physics to artificial intelligence to solve problems too large for a single academic institution. — Source: [YouTube]
Part 5: Scaling, Infrastructure, and The Moat
- On the real AI moat: The actual competitive advantage in AI is the knowledge of how to scale systems efficiently across hardware, not merely possessing the compute itself. — Source: [Hugging Face Blog]
- On the data moat fallacy: The narrative that proprietary data is an insurmountable barrier is flawed; high-quality open internet data is sufficient to train highly competitive models. — Source: [YouTube]
- On the Ultra-Scale Playbook: Hugging Face published this technical guide to lift the veil on distributed training techniques that were previously treated as trade secrets in corporate labs. — Source: [Hugging Face Blog]
- On memory limits: Memory capacity remains the hard physical constraint when scaling massive language models across GPU clusters. — Source: [Hugging Face Blog]
- On communication overhead: Minimizing idle time during data transfer across thousands of chips is a primary technical hurdle in ultra-scale training. — Source: [Hugging Face Blog]
- On training vs usage costs: While training frontier models costs billions, the cost of running and fine-tuning them is dropping rapidly, which heavily favors the open-source ecosystem. — Source: [YouTube]
- On model leaderboards: Securing a spot in the top 10 of generalized leaderboards matters far less than a model's efficiency and utility in specific, high-value tasks. — Source: [YouTube]
- On efficiency: Wolf actively advocates for smaller, highly optimized architectures, noting that pushing extreme parameter counts is not always the best path forward. — Source: [The Stack]
- On empirical scaling: Developing open-source scaling strategies requires running thousands of isolated experiments to map the exact limits of hardware parallelism. — Source: [SSOJET]
Part 6: Rethinking the Limitations of AI
- On the Einstein problem: "To create an Einstein in a data center, we don't just need a system that knows all the answers, but rather one that can ask questions nobody else has thought of or dared to ask." — Source: [Benzinga]
- On the difficulty of science: "In science, asking the question is the hard part. Once the question is asked, often the answer is quite obvious... models are very bad at asking great questions." — Source: [Benzinga]
- On the obedient student analogy: "LLMs are producing 'yes-men on servers'—very obedient students rather than the B-student skeptics science actually needs." — Source: [Prometheus Root]
- On true breakthroughs: "Real scientific breakthroughs come not from answering known questions, but from asking challenging new ones and questioning previous ideas." — Source: [Benzinga]
- On redefining benchmarks: "An Einstein-level breakthrough in Go would involve inventing the rules of Go itself." — Source: [Benzinga]
- On the intelligence explosion: "I don't really believe in like this explosion... of intelligence. So I think we'll just have this steady increase." — Source: [YouTube]
- On political races: He cautions against getting swept up in a political race for artificial general intelligence, preferring steady, measurable scientific progress. — Source: [YouTube]
- On the reproduction trap: Models currently excel at reproducing textbook knowledge but fail entirely at challenging the underlying assumptions of that knowledge. — Source: [Surrey University]
- On physical testing: "Science is the ultimate thing where actually if your theory is wrong... and if you cannot test your theory it's not even a theory." — Source: [YouTube]
Part 7: Robotics and Physical Embodiment (LeRobot)
- On the robotics inflection point: "I have a spidey sense that we're at the same moment for robotics today that we were for transformers and language models a handful of years ago." — Source: [YouTube]
- On the vision for LeRobot: "At Hugging Face... we believe in a future where AI and robots are open-source, transparent, and affordable; community-built and safe; hackable and fun." — Source: [Substack]
- On the data bottleneck: "One of the big differences between language and robotics is you have trillions of tokens out in the public internet to train LLMs. That dynamic doesn't exist in robotics." — Source: [YouTube]
- On avoiding an elite future: "What I would really not be super excited about is a future where robots are kind of an elite thing because they cost $100,000." — Source: [Sequoia Capital]
- On hardware accessibility: "We decided to lower the entry barrier as much as we could... first releasing a $100 arm... we wanted something cute, so you can actually do robotics with your family." — Source: [YouTube]
- On physical limitations: "If you picture a future where AI is extremely intelligent then the only remaining task for human is just to carry this paper from here to here... that's a very sad future. So we have to build robots." — Source: [YouTube]
- On the iPhone moment: "The way we see these robots actually is a little bit like an iPhone... it's an open ecosystem just like the app store where new developers will be able to bring new apps." — Source: [YouTube]
- On vertical silos: He criticizes companies building closed-source, siloed robots because developers cannot easily adapt those systems to test new ideas. — Source: [YouTube]
- On local execution: "Safety questions in robotics are a good reason you may want to really be able to not depend on a distant API, but have the models as close as possible to the hardware." — Source: [YouTube]
- On software developers: "There is a potential future transition where all of these [software developers] also become roboticists in a way, if you give them the tools." — Source: [Sequoia Capital]
Part 8: Career Advice, Learning, and Personal Philosophy
- On entering the field: "If you really love the field you'll find your way into it, don't worry." — Source: [Analytics Vidhya]
- On prioritization: "One of my main challenges has always been to prioritize... I try to avoid multitasking by not having too many projects in parallel." — Source: [Medium]
- On transversal projects: "The way I manage to solve the prioritization issue is usually by focusing on transversal projects that will move forward, or enable, several projects at the same time." — Source: [Medium]
- On finding a niche: In a highly competitive environment, he advises becoming a deep expert in a specific niche rather than a generalist who knows a bit of everything. — Source: [Reddit]
- On consistency: He advocates for taking small, consistent steps every day rather than waiting for a massive single breakthrough to advance a career. — Source: [YouTube]
- On learning from multiple angles: When tackling a new concept, he recommends reading several papers that approach the same topic from different perspectives to build robust comprehension. — Source: [Medium]
- On building tangible tools: When looking to get hired in AI, having built and shared real tools or models with the community carries more weight than abstract credentials. — Source: [YouTube]
- On community contribution: Embrace a mindset of sharing early; giving your work to the community is the most reliable way to build something significant in the long run. — Source: [Analytics Vidhya]
- On asking questions: He warns researchers not to just become good at passing benchmarks, but to focus on asking questions that challenge the status quo. — Source: [Surrey University]
- On ambitious goals: While taking small daily steps, he encourages the AI community not to shy away from massive, long-term goals that fundamentally alter how technology is accessed. — Source: [YouTube]