# Lessons from Christopher Manning
Stanford professor Christopher Manning studies how computers process language. He co-authored early texts on statistical NLP, developed the GloVe embedding model, and helped define foundation models. This collection covers his practical views on linguistics, deep learning architectures, and how large language models actually work.
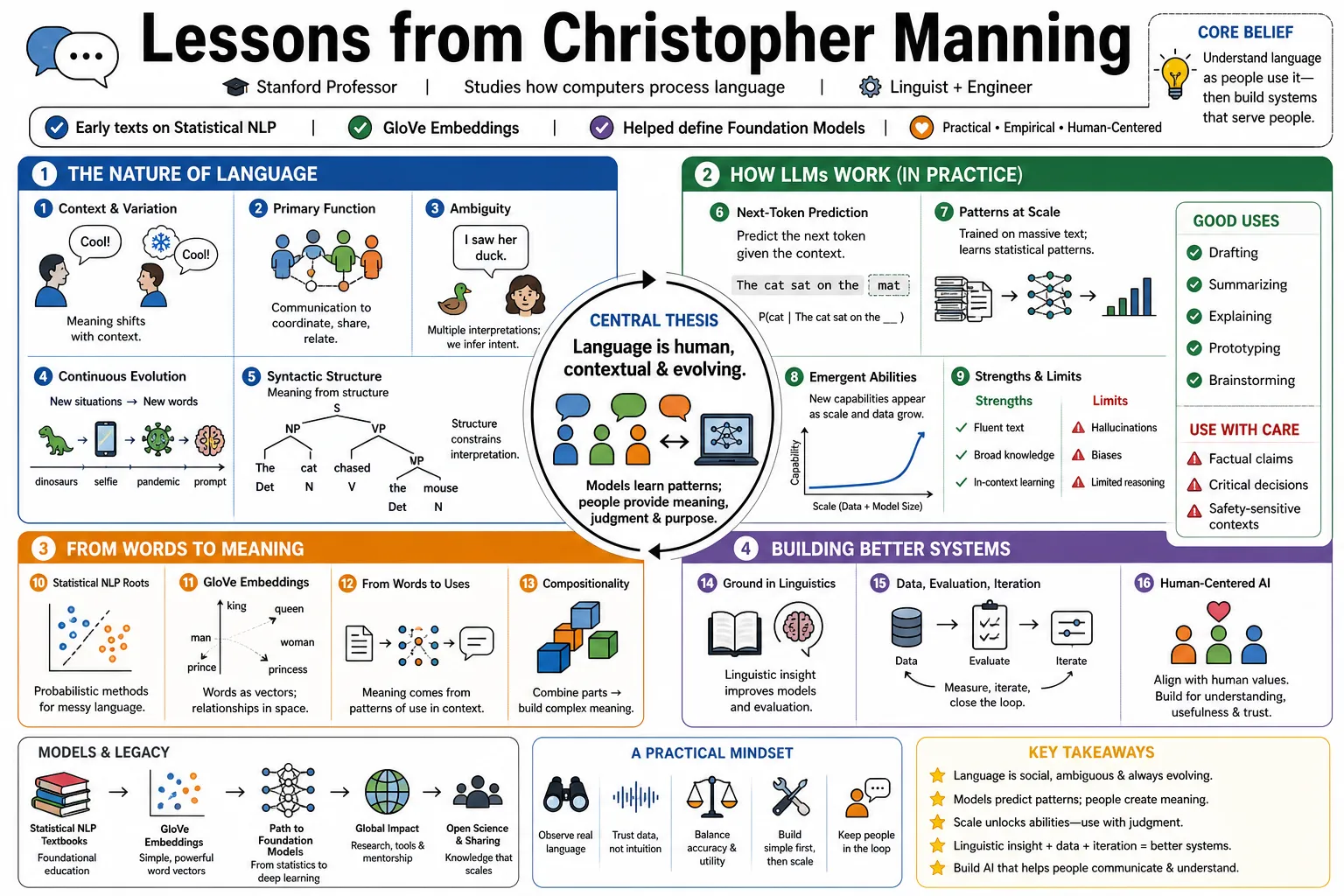
Part 1: The Nature of Language
- On context and variation: "Language is a complex, constantly shifting social creation where interpretation depends heavily on context, meaning standard rules are always challenged by new expressions." — Source: [Science]
- On the primary function of language: "Human language is first and foremost a communication system used by groups of people to coordinate, share information, and establish social relationships." — Source: [Stanford CS224N Lectures]
- On ambiguity: "Unlike formal mathematical systems, human languages are fundamentally ambiguous, requiring listeners to constantly infer intent based on shared worldly knowledge." — Source: [Foundations of Statistical Natural Language Processing]
- On continuous evolution: "There is no fixed, finalized version of a natural language. It evolves in real-time as people invent new terms to describe novel situations." — Source: [The Gradient Podcast]
- On syntactic structure: "Sentences are not simple sequences of words. They possess a recursive, nested structure that dictates how smaller units combine to form complex thoughts." — Source: [Stanford NLP Group]
- On pragmatic meaning: "Understanding a sentence requires knowing what the words mean and why the speaker chose to say them in a specific situation." — Source: [CS224N Course Materials]
- On the difficulty of parsing: "The sheer number of mathematically possible parse trees for a single average-length sentence highlights why language comprehension requires probabilistic reasoning rather than strict rule-following." — Source: [Foundations of Statistical Natural Language Processing]
- On language acquisition: "Children learn language largely through exposure to vast amounts of communicative interaction, an observation that historically motivated the shift toward data-driven learning in machines." — Source: [Stanford Engineering Future of Everything]
- On linguistic diversity: "While English dominates computational research, the true test of NLP architectures is their ability to generalize across the vast typological differences found in the world's thousands of languages." — Source: [Universal Dependencies Project]
Part 2: The Evolution of Natural Language Processing
- On the shift from rules to statistics: "The transition from writing hand-crafted grammatical rules to using probabilistic models marked the first major turning point in making language systems functional for real-world text." — Source: [Foundations of Statistical Natural Language Processing]
- On the impact of big data: "It became obvious over time that computers could pick up the intricacies of language much faster if they were trained on large bodies of text rather than programmed with explicit rules." — Source: [Science Review on NLP]
- On early deep learning skepticism: "When deep learning first emerged in NLP, many linguists were highly skeptical that a model without explicit syntactic priors could outperform systems built on decades of linguistic theory." — Source: [Last Words: Computational Linguistics and Deep Learning]
- On the empirical victory of neural nets: "Despite early doubts, end-to-end neural network models eventually proved superior by learning soft, continuous representations rather than relying on discrete categories." — Source: [DeepLearning.AI Interview]
- On the consolidation of tasks: "Historically, we built separate pipelines for part-of-speech tagging, parsing, and translation. Modern neural architectures collapsed these pipelines into single, unified models." — Source: [CS224N Course Overview]
- On the role of hardware: "The theoretical concepts for neural networks existed for decades, but it was the advent of modern parallel computing infrastructure that allowed these models to actually work for language." — Source: [Stanford HAI Research]
- On the speed of progress: "The transition from static word embeddings to recurrent neural networks, and subsequently to transformers, occurred at a pace that surprised even those actively working in the field." — Source: [TWIML AI Podcast]
- On the fading of feature engineering: "Researchers used to spend months designing specific linguistic features to help a classifier. Now, the focus is entirely on architecture design and data curation." — Source: [Stanford NLP Publications]
- On the persistence of statistical principles: "Even though the underlying architectures have changed from simple Markov models to massive transformers, the core principle of optimizing probability distributions over text remains the same." — Source: [CS224N Lectures]
- On historical continuity: "Modern language models did not emerge from a vacuum. They are the direct mathematical descendants of the n-gram language models developed in the 1980s and 1990s." — Source: [The Gradient Podcast]
Part 3: Deep Learning and Neural Architecture
- On the limitation of black boxes: "While deep learning performs exceptionally well, simply coupling huge amounts of data with black-box architectures is an insufficient approach for advancing the scientific understanding of language." — Source: [Last Words: Computational Linguistics and Deep Learning]
- On distributed representations: "The power of neural networks in NLP comes from their ability to represent words and concepts as dense vectors in a continuous, multidimensional space." — Source: [GloVe Research Paper]
- On the transformer architecture: "The self-attention mechanism fundamentally changed NLP by allowing models to weigh the relevance of every word in a sequence relative to every other word, regardless of distance." — Source: [Stanford CS224N Materials]
- On tree-recursive models: "Early attempts to incorporate linguistic structure into deep learning involved tree-recursive neural networks, which explicitly modeled the hierarchical parsing of sentences." — Source: [Stanford NLP Group]
- On soft versus hard constraints: "Neural networks excel because they rely on soft probabilistic weights rather than hard categorical logic, allowing them to handle the inherent fuzziness of human communication." — Source: [DeepLearning.AI Interview]
- On the necessity of understanding: "We must strive to analyze the internal representations of deep learning models rather than treating them merely as functional off-the-shelf tools." — Source: [Last Words: Computational Linguistics and Deep Learning]
- On backpropagation: "The simple mechanism of backpropagating errors through a network remains the engine that allows machines to map raw text onto complex semantic representations." — Source: [CS224N Course Notes]
- On the shift away from recurrence: "Recurrent neural networks processed language sequentially, much like humans do, but their inability to parallelize training ultimately led to their replacement by attention-based architectures." — Source: [CS224N Lectures]
- On architectural convergence: "We have seen a striking convergence where the same transformer-based architectures that dominate text processing are now being applied successfully to vision and audio." — Source: [Stanford HAI Reports]
Part 4: Foundation Models and Scale
- On the term Foundation Model: "We chose the term foundation model because existing terms like large language model were too narrow, failing to capture how these systems serve as a general base for a wide variety of downstream tasks." — Source: [Stanford HAI Center]
- On the training objective: "At their core, the training process for these massive models is essentially playing a gigantic game of Mad Libs, constantly guessing the missing or next word." — Source: [Stanford Engineering Future of Everything]
- On the paradigm shift: "Foundation models represent a distinct era in AI, characterized by training a single massive model on broad data and then adapting it to specialized applications." — Source: [On the Opportunities and Risks of Foundation Models]
- On emergent capabilities: "As models scale up in parameters and data volume, they begin to exhibit behaviors and capabilities that were neither explicitly programmed nor present in smaller versions." — Source: [Stanford HAI Center]
- On data constraints: "If you are working with limited training data, a more explicitly constrained model will typically perform better than a massive neural network." — Source: [Stanford NLP Group]
- On self-supervised learning: "The breakthrough of modern models is self-supervision, which uses the structure of the data itself as the training signal and eliminates the bottleneck of human annotation." — Source: [TWIML AI Podcast]
- On the homogenization of AI: "The foundation model paradigm leads to homogenization. A single architecture powers countless applications, meaning any inherent flaws in the base model are inherited widely." — Source: [On the Opportunities and Risks of Foundation Models]
- On sociotechnical systems: "The deployment of foundation models is a fundamentally sociotechnical issue, requiring input from ethicists, economists, and legal scholars." — Source: [Stanford HAI Publications]
- On the limits of scale: "While increasing compute and data predictably lowers training loss, scale alone is unlikely to solve fundamental issues related to logical deduction and physical grounding." — Source: [The Gradient Podcast]
- On the illusion of intelligence: "Because language models generate text that is highly fluent and syntactically flawless, humans naturally project a level of underlying comprehension onto them that may not actually exist." — Source: [Stanford CS224N Lectures]
Part 5: The Role of Linguistics in AI
- On defining linguistics: "Linguistics provides the necessary vocabulary and framework for describing what it is that language models are actually doing when they process text." — Source: [Last Words: Computational Linguistics and Deep Learning]
- On syntax in neural networks: "Even without explicit syntactic rules, large language models naturally develop internal representations that closely mirror traditional dependency parsing trees." — Source: [Stanford NLP Publications]
- On the necessity of grammar: "While a model might generate statistically likely sequences, understanding the formal grammar of a language remains essential for evaluating a model's true syntactic competence." — Source: [CS224N Course Materials]
- On Universal Dependencies: "Creating a standardized framework for grammatical annotation across different languages is necessary for building NLP systems that do not implicitly bias toward English structures." — Source: [Universal Dependencies Project]
- On morphology: "Languages with rich morphology, where single words contain complex internal structures, present specific challenges that simple word-level tokenization struggles to resolve." — Source: [Stanford NLP Group]
- On cognitive plausibility: "We often look to human language acquisition to inspire machine learning architectures, asking whether our models process information in ways analogous to human cognition." — Source: [The Gradient Podcast]
- On the tension between fields: "There has historically been friction between linguists who favor elegant explanatory theories and computer scientists who favor messy empirical results." — Source: [Foundations of Statistical Natural Language Processing]
- On linguistic probing: "A major area of research involves designing specific tests, or probes, to determine exactly what kind of linguistic features a trained neural network has managed to learn." — Source: [Stanford NLP Group]
- On semantics versus form: "Linguistics reminds us that generating the correct form of a sentence does not necessarily mean the system understands the underlying semantics of the proposition." — Source: [Last Words: Computational Linguistics and Deep Learning]
- On the future of the discipline: "The role of computational linguistics is shifting from building the models themselves to rigorously analyzing, interpreting, and critiquing the behavior of massive AI systems." — Source: [TWIML AI Podcast]
Part 6: Representation and Semantics
- On Firth's principle: "In distributional semantics, we rely on the adage that you shall know a word by the company it keeps to build representations of meaning based entirely on co-occurrence." — Source: [CS224N Course Openers]
- On the GloVe motivation: "Prior to our work, methods for learning vector space representations succeeded in capturing fine-grained regularities, but the origin of these regularities remained opaque." — Source: [GloVe Research Paper]
- On vector arithmetic: "It remains a striking property of word embeddings that semantic relationships, such as gender or geography, can be expressed as simple mathematical translations in a vector space." — Source: [Stanford NLP GloVe Project]
- On word similarity: "When mapping meaning to numbers, we assess performance by how closely the distance between two vectors aligns with human judgments of similarity." — Source: [CS224N Lectures]
- On the limits of static vectors: "Static embeddings assign a single vector to a word, forcing models to collapse distinct meanings, like a river bank and a financial bank, into one average representation." — Source: [Stanford NLP Group]
- On contextual embeddings: "The transition to contextualized embeddings allowed the representation of a word to dynamically shift depending on the specific sentence surrounding it." — Source: [CS224N Course Notes]
- On capturing world knowledge: "Word vectors inherently capture not just linguistic definitions, but the cultural biases, stereotypes, and factual associations present in their training corpora." — Source: [Stanford HAI Research]
- On continuous versus discrete: "Representing meaning as continuous vectors rather than discrete dictionary definitions allows models to compute subtle degrees of similarity that strict categories miss." — Source: [DeepLearning.AI Interview]
- On aligning representations: "A current frontier is figuring out how to align the semantic spaces learned by text models with the visual spaces learned by image models." — Source: [Stanford Engineering Future of Everything]
Part 7: Limitations and Reasoning
- On models and truth: "Language models are optimized to write credibly and fluently, but they are not inherently optimized to write the truth." — Source: [Stanford HAI Center]
- On System 1 and System 2 thinking: "Current foundation models excel at System 1 thinking, which involves fast associative pattern matching, but they struggle with System 2 thinking, which requires slow, deliberate, multi-step logical deduction." — Source: [Stanford HAI Publications]
- On physical grounding: "Because text models are trained disembodied from the physical world, they frequently fail at reasoning tasks that rely on basic spatial or physical intuition." — Source: [TWIML AI Podcast]
- On hallucination: "The tendency of models to invent facts confidently is a direct consequence of their objective function, which prioritizes plausible continuation over factual verification." — Source: [CS224N Lectures]
- On long-term memory: "Standard language models process fixed context windows, meaning they lack true episodic memory or the ability to maintain a coherent state across very long interactions." — Source: [The Gradient Podcast]
- On common sense: "Despite reading more text than a human could in thousands of lifetimes, models still routinely fail edge cases that rely on unspoken human common sense." — Source: [DeepLearning.AI Interview]
- On evaluating reasoning: "As models become more articulate, traditional benchmarks fail. We must develop harder evaluations to separate true reasoning from sophisticated rote memorization." — Source: [Stanford NLP Group]
- On useful models: "Following George Box's observation, all models are technically wrong in how they represent reality, but some prove to be incredibly useful engineering tools." — Source: [Stanford Lectures]
- On the gap to general intelligence: "While predicting the next word has proven far more powerful than anyone anticipated, it is highly likely that achieving general intelligence will require fundamentally new architectural components." — Source: [Stanford Engineering Future of Everything]
Part 8: Academia, Teaching, and Societal Impact
- On the purpose of teaching: "The goal of teaching natural language processing is not just to show how to use models, but to explain the underlying math and linguistics so students can build the next generation of architectures." — Source: [Stanford CS224N Course]
- On open science: "The rapid progress in modern AI is largely attributable to the culture of open publication, shared datasets, and open-source model weights." — Source: [TWIML AI Podcast]
- On the democratization of AI: "We must ensure that the ability to build and deploy foundation models does not become exclusively consolidated within a few heavily funded technology companies." — Source: [Stanford HAI Center]
- On academic research: "While industry labs have the compute to scale models, academia remains necessary for probing, evaluating, and developing theories about why these systems work." — Source: [The Gradient Podcast]
- On interdisciplinary collaboration: "Addressing the ethical implications of AI cannot be done by computer scientists alone. It requires deep collaboration with the humanities and social sciences." — Source: [Stanford HAI Research]
- On algorithmic bias: "Because models learn from human data, they inherit human prejudices, making bias mitigation a central engineering challenge." — Source: [On the Opportunities and Risks of Foundation Models]
- On language as a barrier: "Improving natural language processing is fundamentally about breaking down barriers to information access for people who do not speak dominant languages or interact comfortably with computer code." — Source: [Stanford NLP Group]
- On the responsibility of developers: "Engineers deploying AI systems have a responsibility to understand the sociotechnical context in which their models will operate and the potential harms they may cause." — Source: [Stanford HAI Publications]
- On the future of the field: "Despite the astonishing progress of the last decade, we are still in the early stages of understanding how to build machines that truly comprehend human language in all its depth." — Source: [DeepLearning.AI Interview]