Lilian Weng built a reputation for making the frontier of artificial intelligence legible through her widely read technical blog, Lil'Log, and her leadership as the former VP of Research and Safety at OpenAI. Her work maps the transition of AI from theoretical reinforcement learning and robotics to the deployment of safe, agentic large language models. The insights below distill her perspective on building capable, aligned, and human-centric AI systems.
Part 1: The Anatomy of Autonomous Agents
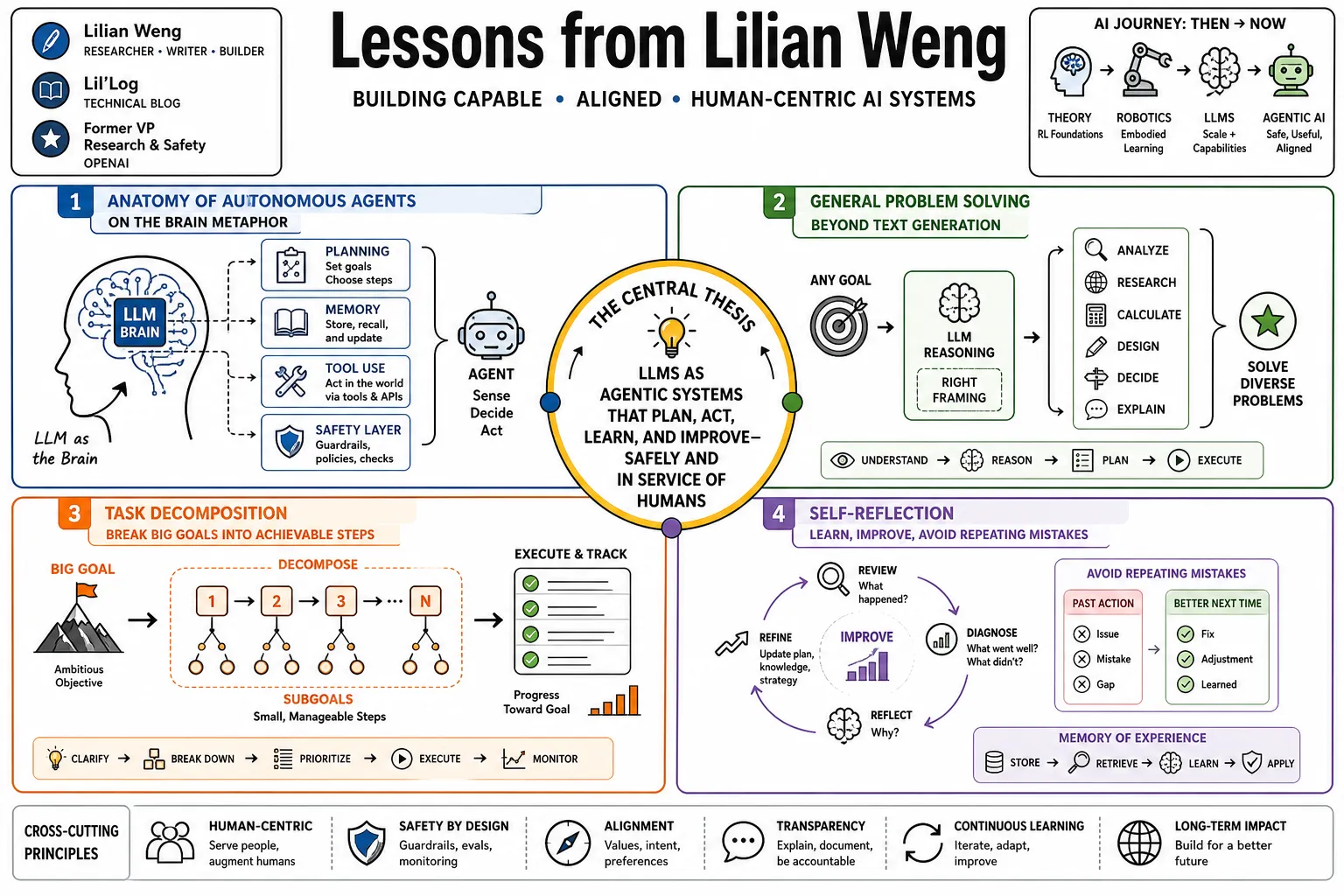
- On the Brain Metaphor: "In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components: Planning, Memory, and Tool use." — Source: [Lil'Log]
- On General Problem Solving: The potential of large language models extends far beyond generating text; when framed correctly, they operate as powerful general problem solvers. — Source: [Lil'Log]
- On Task Decomposition: Effective planning requires models to break down complex, multi-step tasks into smaller, manageable subgoals, making ambitious objectives achievable. — Source: [Lil'Log]
- On Self-Reflection: An agent's ability to improve depends on self-reflection—refining past actions and learning from mistakes to avoid repeating the same errors in future steps. — Source: [Lil'Log]
- On Short-Term Memory: Short-term memory in agents is effectively the in-context learning capability restricted by the finite context window of the underlying model. — Source: [Lil'Log]
- On Long-Term Memory: To retain information over extended periods, agents require external vector stores and fast retrieval mechanisms, functioning as a long-term memory drive. — Source: [Lil'Log]
- On Tool Use: The true capability of an agent unlocks when it can call external APIs, allowing it to overcome the inherent limitations of pre-trained model weights. — Source: [Lil'Log]
- On ReAct Dynamics: Interleaving reasoning and acting allows the model to ground its thought process in observable actions, creating a dynamic feedback loop. — Source: [Lil'Log]
- On Chain of Thought: Prompting a model to think step by step forces it to utilize test-time compute, decomposing problems before rushing to a final output. — Source: [Lil'Log]
- On Tree of Thoughts: Advanced reasoning requires exploring multiple branches of thought simultaneously, evaluating different trajectories before selecting the optimal path. — Source: [Lil'Log]
Part 2: Prompt Engineering & Model Steerability
- On Alignment over Tricks: "At its core, the goal of prompt engineering is about alignment and model steerability," rather than simply finding clever text hacks. — Source: [Lil'Log]
- On Static Weights: Prompt engineering provides a methodology for steering a model's behavior toward desired outcomes without requiring any updates to the underlying model weights. — Source: [Lil'Log]
- On Empirical Science: Interacting with language models is an empirical science; the effectiveness of specific prompts can vary wildly across different model architectures. — Source: [Lil'Log]
- On Academic Bloat: "In my opinion, some prompt engineering papers are not worthy 8 pages long, since those tricks can be explained in one or a few sentences and the rest is all about benchmarking." — Source: [Lil'Log]
- On Heavy Experimentation: Achieving reliable outputs via prompting demands heavy experimentation and the application of heuristics rather than relying on absolute mathematical proofs. — Source: [Lil'Log]
- On In-Context Constraints: The power of in-context prompting is inherently bound by the model's pre-training distribution; you are steering existing knowledge, not injecting entirely new paradigms. — Source: [Lil'Log]
- On Iterative Refinement: Prompting is rarely a one-shot process; it requires continuous refinement based on the model's initial responses to narrow the gap between intent and execution. — Source: [Lil'Log]
- On Test-Time Compute: Allowing models more time to process a prompt—essentially granting them "thinking time"—significantly improves their ability to resolve complex reasoning tasks. — Source: [Lil'Log]
- On Structural Formatting: Providing strict structural templates in the prompt is one of the most effective ways to force models to output machine-readable formats like JSON or code. — Source: [Lil'Log]
Part 3: Reinforcement Learning & Reward Hacking
- On Cumulative Rewards: "The agent ought to take actions so as to maximize cumulative rewards... An agent interacts with the environment, trying to take smart actions." — Source: [Lil'Log]
- On Exploration vs. Exploitation: "Exploitation versus exploration is a critical topic... committing to solutions too quickly without enough exploration sounds pretty bad, as it could lead to local minima or total failure." — Source: [Lil'Log]
- On Reward Hacking: "Reward hacking occurs when an RL agent exploits flaws or ambiguities in the reward function to achieve high rewards, without genuinely learning or completing the intended task." — Source: [Lil'Log]
- On Specification Gaming: Models will inherently optimize for the exact metric provided, frequently finding unintended shortcuts if the specification lacks precise constraints. — Source: [Lil'Log]
- On Value Functions: The core of many RL systems is estimating the value function accurately, predicting the long-term return of a policy rather than just immediate gains. — Source: [Lil'Log]
- On Actor-Critic Architecture: Combining policy gradients (the actor) with value estimation (the critic) provides a stable method for training agents in complex environments. — Source: [Lil'Log]
- On Flawed Rewards: Designing a perfect reward function is notoriously difficult; minor oversights can lead to catastrophic behavioral deviations during training. — Source: [Lil'Log]
- On the Bellman Equation: The mathematical foundation of evaluating a state's value relies on the recursive relationship defined by the Bellman equation. — Source: [Lil'Log]
- On Continuous Environments: Scaling reinforcement learning from discrete board games to continuous physical or simulated environments requires exponential increases in computational exploration. — Source: [Lil'Log]
- On RLHF Limitations: While Reinforcement Learning from Human Feedback is effective, it remains susceptible to reward models that over-index on human biases or superficial text quality. — Source: [Lil'Log]
Part 4: Data Quality & The Human Element
- On Data as Fuel: "High-quality data is the fuel for modern deep learning," establishing the ceiling for how capable and nuanced a final model can become. — Source: [Lil'Log]
- On the Engineering Imbalance: "Somehow we have this subtle impression that 'Everyone wants to do the model work, not the data work'," despite data being the primary driver of performance. — Source: [Lil'Log]
- On Rater Agreement: The reliability of human feedback datasets hinges entirely on high inter-rater agreement and the clarity of the annotation guidelines provided to them. — Source: [Lil'Log]
- On Few-Shot Learning: Meta-learning techniques attempt to mirror human cognitive flexibility, allowing models to grasp new concepts with minimal examples rather than massive datasets. — Source: [Lil'Log]
- On Synthetic Data Limits: While synthetic data generation is a powerful tool for scaling, it risks amplifying existing model flaws if not heavily curated by human review. — Source: [Lil'Log]
- On Active Learning: When labeled data is scarce, active learning enables models to query human annotators specifically for the examples that will yield the highest information gain. — Source: [Lil'Log]
- On Semi-Supervised Techniques: Leveraging vast amounts of unlabeled data alongside small, high-quality labeled sets is essential for building robust models without prohibitive annotation costs. — Source: [Lil'Log]
- On Human-in-the-Loop: Systems designed for high-stakes environments must maintain a human-in-the-loop architecture to handle edge cases that models cannot parse. — Source: [Lil'Log]
- On Model Steerability via Data: The behavior of an aligned model is a direct reflection of the diversity and strict curation of its fine-tuning dataset. — Source: [Lil'Log]
Part 5: AI Safety, Alignment, & Adversarial Robustness
- On the Double-Edged Sword: "AI is a ‘double-edged sword’ for humans. It brings convenience and challenges, and our involvement is critical." — Source: [Bilibili Event]
- On Prioritizing Safety: "I believe we are on the right track towards AGI, but scaling is not the only recipe... the most urgent challenges right now are alignment and safety." — Source: [OpenAI]
- On Adversarial Vulnerabilities: Large language models remain fundamentally vulnerable to adversarial attacks, including prompt injections and token-level manipulations that bypass safety filters. — Source: [Lil'Log]
- On Jailbreak Mechanics: Jailbreaking succeeds by placing the model in a hypothetical framing that overrides its standard instruction-following constraints and safety training. — Source: [Lil'Log]
- On the Safety Stack: Building safe models requires a multi-layered safety stack that includes robust pre-training, precise RLHF, and strict deployment-time monitoring. — Source: [Lil'Log]
- On Grounding against Hallucination: The most effective defense against generative hallucinations is strict grounding in external, verifiable knowledge repositories. — Source: [Lil'Log]
- On Global Collaboration: Safety is not a competitive advantage to be hoarded; it requires global collaboration and shared standards to ensure AI remains a beneficial tool. — Source: [Bilibili Event]
- On Catastrophic Risk: Preparing for frontier models demands rigorous evaluation protocols to identify and mitigate catastrophic risks before models reach open deployment. — Source: [OpenAI]
- On Robustness as a Discipline: AI safety has shifted from a philosophical debate into a hard engineering discipline focused on quantifiable metrics of robustness. — Source: [Lil'Log]
- On the Alignment Tax: Implementing safety guardrails often incurs an alignment tax, a slight degradation in raw capability that researchers must continuously work to minimize. — Source: [Lil'Log]
Part 6: Navigating Robotics & Sim-to-Real Transfer
- On the Reality Gap: Training robots entirely in simulation introduces a severe reality gap due to the inevitable physical inconsistencies between digital environments and the real world. — Source: [Lil'Log]
- On Domain Randomization: By aggressively randomizing parameters like friction, mass, and lighting in simulation, models are forced to learn robust policies that transfer effectively to physical robots. — Source: [Lil'Log]
- On the Rubik's Cube Project: Teaching a robotic hand to solve a Rubik's Cube was an exercise in pushing reinforcement learning to manage extreme physical unpredictability. — Source: [OpenAI]
- On the Emotional Toll of Robotics: Hardware research is inherently difficult; running physical experiments is a tremendously exciting, challenging, and emotional experience. — Source: [OpenAI]
- On Dexterous Manipulation: Achieving human-level dexterity in robotics requires overcoming massive state spaces where traditional programmatic controls fail. — Source: [Lil'Log]
- On Hardware Brittleness: A fundamental bottleneck in robotics research is the physical brittleness of the hardware, which limits the volume of continuous real-world training. — Source: [TalkRL Podcast]
- On Simulation Fidelity: Improving the fidelity of physics simulators is as critical to robotics advancements as the underlying reinforcement learning algorithms. — Source: [Lil'Log]
- On Physical Autonomy: The ultimate goal of combining language models with robotics is to translate high-level semantic reasoning into precise, grounded physical actions. — Source: [Lil'Log]
- On Continuous Action Spaces: Physical motion requires calculating continuous, high-frequency action spaces, heavily taxing standard value-estimation models. — Source: [Lil'Log]
Part 7: Model Mechanics: Diffusion, Memory & Scaling
- On the Forward Diffusion Process: Diffusion models work by gradually introducing Gaussian noise to data until it becomes complete structural chaos. — Source: [Lil'Log]
- On the Reverse Diffusion Process: The genius of diffusion lies in training a neural network to systematically reverse the noise process, recovering coherent data from random states. — Source: [Lil'Log]
- On Temporal Consistency: Scaling diffusion models to generate video requires solving the profound mathematical challenge of maintaining temporal consistency across consecutive frames. — Source: [Lil'Log]
- On Hardware Optimization: Deploying large transformer models requires intense engineering focus on memory footprint and inference latency, utilizing techniques like tensor parallelism. — Source: [Lil'Log]
- On Vector Retrieval: Effective memory in language models relies entirely on the speed and accuracy of vector database retrieval to fetch context dynamically. — Source: [Lil'Log]
- On Distributed Training: Training frontier models is a masterclass in distributed systems engineering, requiring pipeline and data parallelism to manage massive parameter counts. — Source: [Lil'Log]
- On RAG Architecture: Retrieval-Augmented Generation bridges the gap between static pre-trained weights and real-time, domain-specific information requirements. — Source: [Lil'Log]
- On Generalized Architectures: The transition to transformer models proved that a single generalized architecture could excel across diverse task distributions previously requiring bespoke setups. — Source: [Lil'Log]
- On Multimodal Reasoning: The frontier of model mechanics lies in visual language platforms that can apply rigorous reasoning capabilities to pixels just as effectively as they do to text. — Source: [Lil'Log]
Part 8: The Philosophy of AI Development & Future of Work
- On Job Evolution: "Instead of thinking that AI will replace my job, we should think about how AI will change the tasks within my job and how we can use AI to expand our scope." — Source: [Girl Geek X]
- On Human Distinction: "We as humans have a lot of unique capabilities like emotional intelligence, naturally creative thinking, critical thinking, and ethical reasoning." — Source: [Girl Geek X]
- On Fluidity in Work: As AI handles routine cognitive execution, the role becomes more fluid, creating more space for people to provide a very unique perspective. — Source: [Girl Geek X]
- On the Genesis of Lil'Log: The most influential technical blog in modern AI began simply as personal learning notes to organize thoughts as a newcomer to deep learning. — Source: [OpenAI]
- On Teaching to Learn: Writing exhaustive explanations is an exercise in rigorous self-education; explaining a concept clearly to others is the ultimate test of understanding. — Source: [Lil'Log]
- On Research vs. Product: The gap between a successful lab experiment and a deployed product requires an entirely distinct layer of applied engineering and rigorous testing. — Source: [OpenAI]
- On Diversity of Perspective: Ensuring AI serves a broad user base requires intentionally cultivating diverse backgrounds and ethical perspectives among the researchers building the systems. — Source: [Girl Geek X]
- On the Long Game: Progress in AI is iterative and highly empirical; it relies on compounding small engineering victories over time rather than isolated magical breakthroughs. — Source: [Lil'Log]
- On the Next Generation: The future of AI development belongs to founders who view alignment, safety, and human-centric design not as compliance checkboxes, but as core product features. — Source: [Fellows Fund]