Lessons from Aakanksha Chowdhery
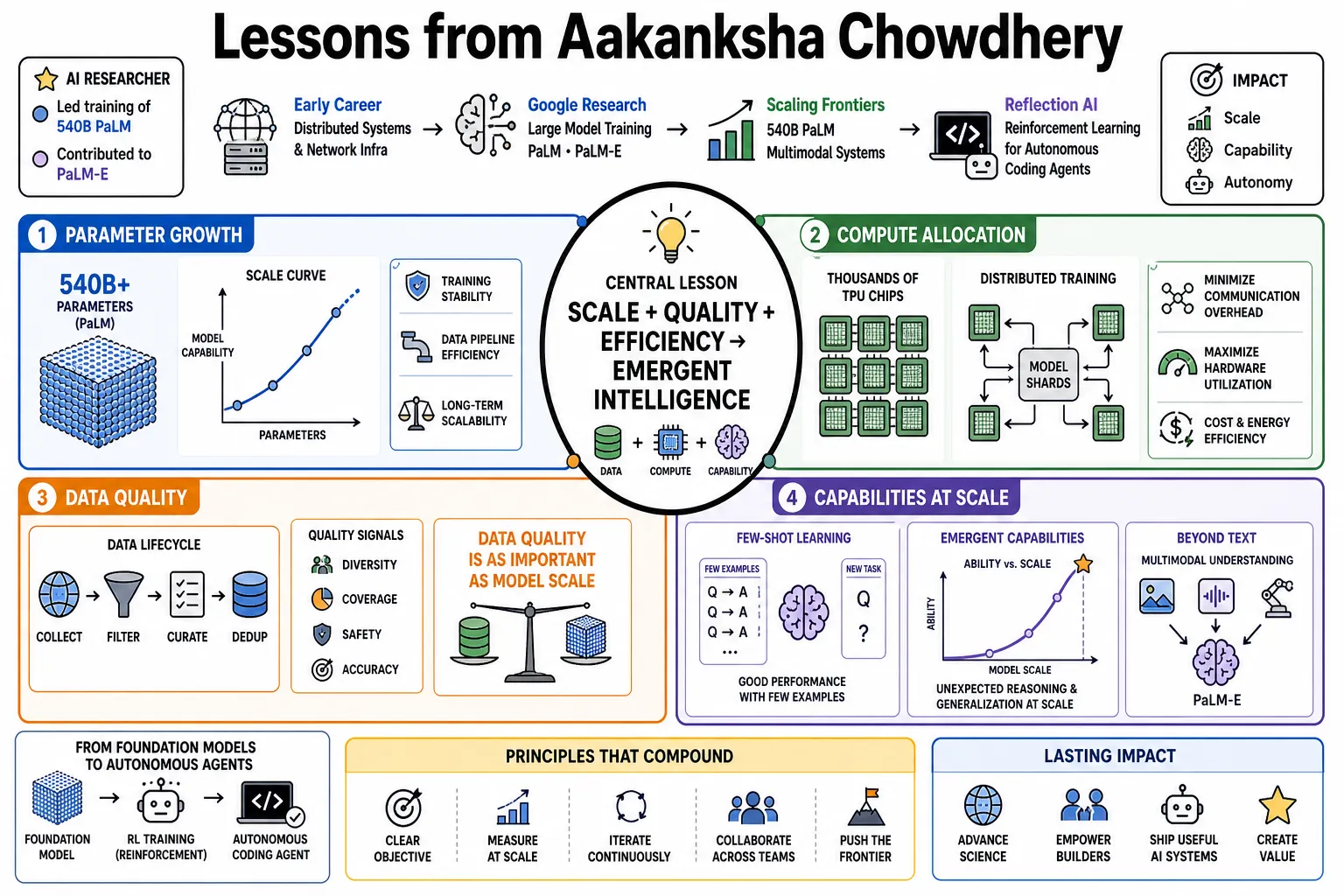
Aakanksha Chowdhery is an AI researcher who led the training for Google's 540-billion parameter PaLM model and contributed to multimodal systems like PaLM-E. This profile tracks her career from early work on distributed network infrastructure to her current focus at Reflection AI, where she develops reinforcement learning techniques for autonomous coding agents.
Part 1: Scaling Large Language Models
- On Parameter Growth: "Scaling language models beyond half a trillion parameters requires careful management of training stability and data pipeline efficiency." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Compute Allocation: "Training massive models efficiently demands distributing workloads across thousands of TPU chips while minimizing communication overhead." — Source: [Stanford MLSys Seminar Series]
- On Few-Shot Learning: "Large-scale pre-training allows models to perform well on new tasks with only a few examples, changing how we approach task-specific tuning." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Emergent Capabilities: "As model scale increases, we observe unexpected reasoning capabilities that smaller architectures do not exhibit." — Source: [Stanford MLSys Seminar Series]
- On Data Quality: "The composition and filtering of the pre-training dataset are equally important as the parameter count in determining final model performance." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Evaluation Metrics: "Standard benchmarks often fail to capture the full reasoning depth of large models, forcing the development of more complex reasoning tests." — Source: [Stanford MLSys Seminar Series]
- On Training Instabilities: "Hardware failures and loss spikes are inevitable at the scale of thousands of accelerators; engineering for fault tolerance is a primary concern." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Hardware Utilization: "Maximizing the Model Flops Utilization is a core metric for ensuring that the underlying hardware is actively computing rather than waiting for data." — Source: [Stanford MLSys Seminar Series]
- On Memorization vs Generalization: "Balancing the model capacity to store facts against its ability to generalize rules requires careful tuning of the training duration and data diversity." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Post-Training Constraints: "Relying heavily on post-training to instill reasoning is less effective than baking structural reasoning capabilities into the pre-training phase." — Source: [TWIML AI Podcast]
Part 2: The PaLM and Pathways Architecture
- On Pathways Infrastructure: "The Pathways system allows a single model to be trained across multiple TPU Pods asynchronously, breaking traditional hardware boundaries." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Client-Server Architecture: "Separating the training loop into client and server components allows the compute nodes to operate independently of the data feeding processes." — Source: [Stanford MLSys Seminar Series]
- On Asynchronous Data Fetching: "Hiding the latency of data retrieval is necessary to keep the accelerators continuously fed during a large-scale training run." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Checkpoint Recovery: "When a node fails, the system must quickly resume from the last checkpoint without restarting the entire cluster." — Source: [Stanford MLSys Seminar Series]
- On Model Parallelism: "Splitting the neural network layers across different chips requires optimizing the communication bandwidth between them." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Data Parallelism: "Replicating the model weights across multiple nodes allows the system to process larger batch sizes simultaneously." — Source: [Stanford MLSys Seminar Series]
- On Network Topology: "The physical layout and connection speeds between TPU pods dictate the upper limits of how efficiently a model can be trained." — Source: [PaLM: Scaling Language Modeling with Pathways]
- On Activation Sharding: "Memory constraints require sharding the intermediate activation states across different accelerators to fit the entire model into memory." — Source: [Stanford MLSys Seminar Series]
- On Infrastructure Resilience: "A training run spanning weeks will inevitably encounter hardware errors, requiring the software stack to handle these transparently." — Source: [PaLM: Scaling Language Modeling with Pathways]
Part 3: Multimodal AI and Gemini
- On Native Multimodality: "Training a model from the start on image, audio, and text data yields better cross-modal reasoning than stitching together separate models later." — Source: [Gemini: A Family of Highly Capable Multimodal Models]
- On Vision-Language Tasks: "A truly multimodal architecture can answer questions about an image based on the spatial relationships of the objects within it." — Source: [Stanford MLSys Seminar Series]
- On Audio Integration: "Processing audio directly as raw waveforms allows the model to capture nuances like tone and speaker identity that text transcripts miss." — Source: [Gemini: A Family of Highly Capable Multimodal Models]
- On Multimodal Benchmarks: "Evaluating models on combined text-and-vision tasks like chart understanding requires different metrics than standard text benchmarks." — Source: [Stanford MLSys Seminar Series]
- On Data Alignment: "Ensuring that the text descriptions accurately match the visual content in the training data is difficult but required for grounding." — Source: [Gemini: A Family of Highly Capable Multimodal Models]
- On Model Families: "Creating a family of models from Nano to Ultra allows the same underlying architecture to run on mobile devices and large data centers." — Source: [Stanford MLSys Seminar Series]
- On Interleaved Data: "Training on documents where images and text are interleaved naturally teaches the model about document structure and context." — Source: [Gemini: A Family of Highly Capable Multimodal Models]
- On Video Understanding: "Processing video requires the model to understand temporal dependencies and track objects across multiple frames." — Source: [Stanford MLSys Seminar Series]
- On Cross-Lingual Vision: "A globally trained multimodal model can interpret text within an image regardless of the language it is written in." — Source: [Gemini: A Family of Highly Capable Multimodal Models]
- On Efficiency in Multimodality: "Encoding high-resolution images efficiently into the model context window requires specialized tokenization strategies." — Source: [Stanford MLSys Seminar Series]
Part 4: Embodied AI and Robotics
- On Embodied Reasoning: "Language models can act as the reasoning engine for a robot, translating high-level text commands into step-by-step physical actions." — Source: [PaLM-E: An Embodied Multimodal Language Model]
- On Sensor Integration: "Injecting raw sensor data directly into the language model embedding space gives it real-time awareness of the robot environment." — Source: [Stanford MLSys Seminar Series]
- On Continuous Observation: "An embodied agent must process continuous visual observations to update its plan when the environment changes unexpectedly." — Source: [PaLM-E: An Embodied Multimodal Language Model]
- On Transfer Learning in Robotics: "Knowledge gained from internet-scale text data can help a robot understand concepts it has never physically interacted with." — Source: [Stanford MLSys Seminar Series]
- On Action Output: "The model must output low-level control commands or waypoints that the robot hardware can execute directly." — Source: [PaLM-E: An Embodied Multimodal Language Model]
- On Spatial Awareness: "Understanding physical space from camera feeds is a requirement for tasks like grasping objects or navigating a room." — Source: [Stanford MLSys Seminar Series]
- On Generalization Across Environments: "A model trained on multiple robotic platforms can adapt more easily to a new, unseen robot." — Source: [PaLM-E: An Embodied Multimodal Language Model]
- On Multimodal Prompts for Robots: "Providing an image of a goal state alongside a text command gives the robot a clearer target than text alone." — Source: [Stanford MLSys Seminar Series]
- On Real-World Constraints: "Physics engines and real-world safety limits must guide the outputs generated by the language model." — Source: [PaLM-E: An Embodied Multimodal Language Model]
Part 5: AI in Healthcare and MedPaLM
- On Clinical Accuracy: "Applying language models to medicine requires strict alignment to clinical facts, as hallucinated information has direct patient safety implications." — Source: [Large Language Models Encode Clinical Knowledge]
- On Medical Question Answering: "Evaluating a model against questions from medical licensing exams provides a baseline measure of its factual knowledge." — Source: [Stanford MLSys Seminar Series]
- On Instruction Tuning for Health: "Fine-tuning a general model on a curated dataset of medical question and answer pairs improves its ability to respond appropriately to clinical queries." — Source: [Large Language Models Encode Clinical Knowledge]
- On Explainability: "A medical model must provide the reasoning behind its answers, allowing clinicians to verify its logic." — Source: [Stanford MLSys Seminar Series]
- On Human Evaluation: "Automated metrics fall short for medical AI; outputs require review by panels of physicians to ensure safety and clinical utility." — Source: [Large Language Models Encode Clinical Knowledge]
- On Domain-Specific Multimodality: "Future medical models must natively process imaging scans alongside patient notes." — Source: [Stanford MLSys Seminar Series]
- On Privacy and Security: "Training models on medical data requires strict adherence to privacy protocols to protect patient information." — Source: [Large Language Models Encode Clinical Knowledge]
- On Diagnostic Assistance: "The goal of medical AI is to serve as an assistant that surfaces relevant information to doctors, rather than replacing clinical judgment." — Source: [Stanford MLSys Seminar Series]
- On Handling Uncertainty: "When a medical query is ambiguous, the model must know when to ask clarifying questions or express uncertainty." — Source: [Large Language Models Encode Clinical Knowledge]
Part 6: Agentic AI and Autonomous Systems
- On the Shift to Agents: "The industry is moving from models that answer static questions to agents that can plan and execute multi-step workflows." — Source: [TWIML AI Podcast]
- On Error Recovery: "A true agent must recognize when it has made a mistake and backtrack to find an alternative solution." — Source: [AI Engineer World's Fair]
- On Tool Use: "Agents need the ability to interact with external environments, like running code or searching the web, to verify their assumptions." — Source: [TWIML AI Podcast]
- On Trajectory Data: "Training agents requires datasets that map the entire step-by-step trajectory of solving a problem, instead of only the final answer." — Source: [AI Engineer World's Fair]
- On Pre-training for Agency: "We need to incorporate agentic behavior into the pre-training objective instead of relying solely on reinforcement learning post-training." — Source: [TWIML AI Podcast]
- On Long-Horizon Planning: "Maintaining context over a sequence of actions that spans hours or days remains a primary challenge for autonomous systems." — Source: [AI Engineer World's Fair]
- On Self-Correction: "Models need to generate their own feedback loops, evaluating the success of their actions and adjusting their strategies." — Source: [TWIML AI Podcast]
- On API Interaction: "Teaching models to read documentation and formulate correct API calls dynamically is necessary for extending their capabilities." — Source: [AI Engineer World's Fair]
- On State Tracking: "An agent must maintain an internal representation of the environment state to predict the outcomes of its future actions." — Source: [TWIML AI Podcast]
- On Evaluation Paradigms: "Measuring agent performance requires interactive environments where the agent decisions affect the state, unlike static datasets." — Source: [AI Engineer World's Fair]
Part 7: Reinforcement Learning for Coding
- On Code Generation: "Writing code is inherently verifiable; an agent can run the code, observe the error, and iterate until the tests pass." — Source: [AI Engineer World's Fair]
- On RL in Coding: "Reinforcement learning is well-suited for coding tasks because the compiler provides an immediate, objective reward signal." — Source: [TWIML AI Podcast]
- On Inference-Time Scaling: "Allowing an agent to spend more compute time exploring different solutions during inference often yields better results than zero-shot generation." — Source: [AI Engineer World's Fair]
- On Search Algorithms: "Combining language models with tree-search algorithms enables the system to evaluate multiple coding paths simultaneously." — Source: [TWIML AI Podcast]
- On Repository Context: "To be useful in production, an autonomous coder must understand the entire repository structure rather than isolated files." — Source: [AI Engineer World's Fair]
- On Debugging Capability: "The ability to read stack traces and pinpoint the logical error in a script is distinct from the ability to write code from scratch." — Source: [TWIML AI Podcast]
- On Synthetic Data Generation: "Models can write their own coding challenges and solutions to generate synthetic training data, bootstrapping their capabilities." — Source: [AI Engineer World's Fair]
- On Verifiable Rewards: "In domains where the correctness of an answer can be programmatically verified, reinforcement learning scales effectively." — Source: [TWIML AI Podcast]
- On the Role of the Developer: "As coding agents become more autonomous, the developer role shifts towards defining high-level specifications and reviewing architecture." — Source: [AI Engineer World's Fair]
Part 8: Early Research: Networks and Wireless Systems
- On Video Surveillance Systems: "Designing wireless video networks requires optimizing the transmission protocols to handle high bandwidth streams without dropping frames." — Source: [The Design and Implementation of a Wireless Video Surveillance System]
- On Drone Hotspots: "Mobile drones acting as aerial hotspots must dynamically adjust their user scheduling to account for changing channel conditions." — Source: [Aerial Channel Prediction and User Scheduling in Mobile Drone Hotspots]
- On Channel Prediction: "Predicting the signal strength of a moving node allows the network to preemptively route traffic, reducing latency." — Source: [Princeton PAWS Lab]
- On Interdisciplinary Engineering: "Solving problems in mobile networks often requires combining hardware design, signal processing, and distributed algorithms." — Source: [Stanford Engineering Alumni Interview]
- On Spectrum Allocation: "Efficient use of the wireless spectrum requires algorithms that can quickly reassign frequencies as users move between access points." — Source: [Aerial Channel Prediction and User Scheduling in Mobile Drone Hotspots]
- On System Reliability: "A wireless system deployed in a physical environment must account for interference and physical obstacles in its routing logic." — Source: [The Design and Implementation of a Wireless Video Surveillance System]
- On Edge Computing: "Processing data closer to the source, such as on the drone itself, reduces the burden on the central network infrastructure." — Source: [Princeton PAWS Lab]
- On Mobility Management: "Tracking user movement patterns helps the network anticipate handoffs between different mobile hotspots." — Source: [Aerial Channel Prediction and User Scheduling in Mobile Drone Hotspots]
- On Foundational Skills: "The engineering rigor required to stabilize distributed wireless networks translates directly to the challenges of scaling large machine learning clusters." — Source: [Stanford Engineering Alumni Interview]