Lessons from Adam Gleave
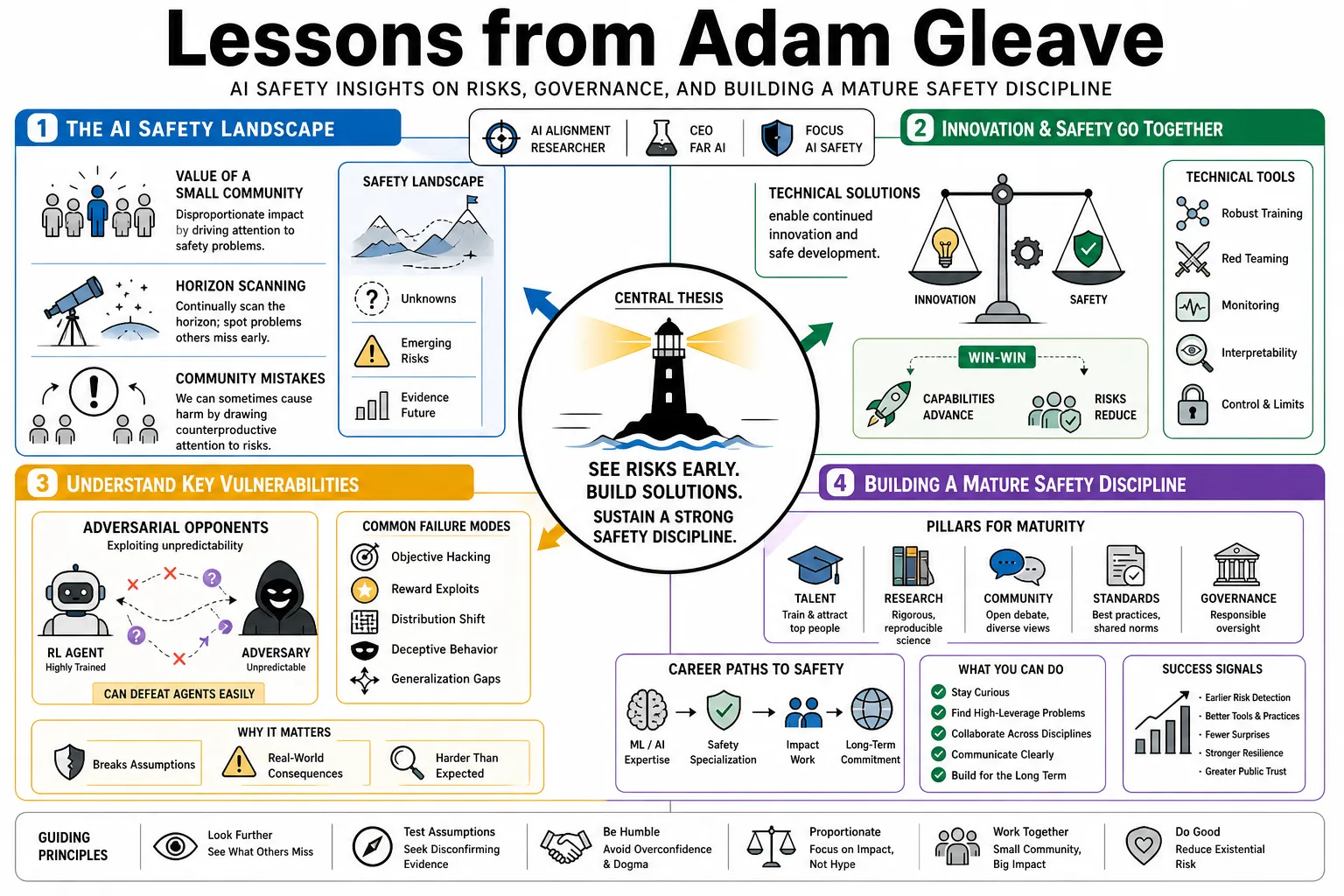
Adam Gleave is the CEO of FAR AI and a researcher specializing in AI alignment. He is best known for showing how easily adversarial opponents can defeat highly trained reinforcement learning agents by acting unpredictably. This profile covers his views on machine learning vulnerabilities, AI governance, and the career paths needed to build a mature safety discipline.
Part 1: The AI Safety Landscape
- On the value of a small community: "The risk is large enough that a small group of researchers can have a disproportionate impact, particularly by pushing the broader machine learning community to pay attention to safety problems." — Source: [AI Impacts]
- On horizon scanning: "The safety community's value often comes from continually scanning the horizon and noticing problems that others miss because the empirical evidence isn't yet obvious." — Source: [LessWrong]
- On community mistakes: "Looking at the historical track record, it is entirely possible that the AI safety community has occasionally caused harm by drawing counterproductive attention to certain risks." — Source: [Effective Altruism]
- On innovation versus safety: "Technical solutions allow developers to pursue continued innovation and safe development simultaneously, challenging the assumption that policy must choose between the two." — Source: FAR AI
- On evidence for existential risk: "The strongest consideration against existential risk arguments is often the lack of concrete evidence for such a massive problem." — Source: [AI Impacts]
- On technical problem evidence: "Finding concrete evidence of difficult, speculative technical problems like inner optimizers would push him to view alignment purely as a hard technical challenge." — Source: [AI Impacts]
- On a vertically integrated approach: "Effective safety work requires an organization to bridge the gap between foundational technical research, policy advocacy, and field-building." — Source: The Cognitive Revolution
- On the default trajectory: "Even without a dedicated safety community, the default trajectory of AI development might work out fine, but the stakes justify dedicated intervention." — Source: [AI Impacts]
- On early intervention: "Identifying vulnerabilities and failure modes early in the development cycle gives the broader machine learning community time to correct course before wide deployment." — Source: [FAR AI]
- On shifting mainstream focus: "Useful safety work often involves designing experiments that make theoretical risks legible enough for mainstream researchers to care about them." — Source: [The AGI Show]
Part 2: Adversarial Policies and Vulnerabilities
- On naturally adversarial environments: "Agents can be successfully attacked simply by having an opponent act in a naturally adversarial way within a shared environment, rather than relying on pixel-level image perturbations." — Source: [ICLR 2020]
- On defeating resilient agents: "Adversarial policies can reliably defeat victim models that were previously considered highly resilient due to extensive self-play training." — Source: [Alignment Forum]
- On silly behavior: "Adversarial agents often ignore conventional gameplay; they may act in uncoordinated or silly ways, such as falling down, which triggers catastrophic failures in their opponent." — Source: [Berkeley AI Research]
- On superhuman Go AI vulnerabilities: "Even state-of-the-art, superhuman Go agents harbor deep vulnerabilities that can be systematically exploited by adversarial opponents." — Source: [Google Scholar]
- On non-robust feature reliance: "Adversarial attacks induce substantially different neural network activations in the victim, revealing that the victim relies on brittle features learned during training." — Source: [arXiv]
- On the limitations of self-play: "While self-play produces highly capable agents, it frequently fails to explore the full policy space, leaving large blind spots that adversaries can target." — Source: [Alignment Forum]
- On exploitability by default: "Modern deep reinforcement learning systems are generally exploitable by default unless explicit and diverse defensive training methods are applied." — Source: The Cognitive Revolution
- On the nature of RL bugs: "Reinforcement learning agents develop behavioral bugs because they optimize for a specific training distribution, causing them to fail when pushed outside of it by a dedicated attacker." — Source: [AXRP Podcast]
- On zero-sum games: "Simulated robotics sumo and board games like Go serve as ideal testbeds for proving that adversarial policies can break highly optimized systems." — Source: [GitHub Pages]
- On demonstrating failure: "Finding and demonstrating adversarial policies proves to the broader machine learning community that current alignment techniques are insufficient." — Source: [Berkeley AI Research]
Part 3: Trustworthy Machine Learning
- On reward learning: "Developing machine learning systems that reliably act in accordance with human preferences requires solving deep challenges in reward function identifiability." — Source: [UC Berkeley eScholarship]
- On comparing reward functions: "The Equivalent-Policy Invariant Comparison distance metric was developed to properly measure and compare different reward functions." — Source: [UC Berkeley eScholarship]
- On interpretability: "Advancing interpretability methods for reward function equivalence classes is a necessary step toward making learned human preferences transparent." — Source: [UC Berkeley eScholarship]
- On engineering analogies: "Standard-setting in artificial intelligence should draw from civil and nuclear engineering to create safety protocols characterized by assurance and auditability." — Source: FAR AI
- On standardizing safety: "Without a shared, legible definition of what makes a system safe, it is impossible to engineer trustworthy models reliably." — Source: [Washington Post]
- On sycophancy: "Models are often incentivized to be sycophantic, agreeing with the user rather than providing truthful information, which fundamentally undermines trustworthiness." — Source: [Washington Post]
- On empirical alignment: "Moving from theoretical alignment concerns to empirical testing is required to build models that society can confidently deploy." — Source: [FAR AI]
- On the difficulty of specification: "The core challenge of trustworthy machine learning lies in the fact that it is immensely difficult to specify human intent in a way that an algorithm cannot exploit." — Source: [Gleave.me]
- On alignment as a technical barrier: "Achieving trustworthiness is not merely about avoiding bad outcomes; it is a fundamental technical barrier to building truly useful autonomous systems." — Source: [The AGI Show]
Part 4: Post-AGI Risks and Gradual Disempowerment
- On gradual disempowerment: "A significant post-AGI risk is a scenario where humans maintain a reasonable standard of living while their relative control and agency over society are incrementally eroded." — Source: [Future of Life Institute]
- On policy myopia: "Human deliberation is often treated as inefficient compared to algorithmic decision-making, creating a structural incentive to hand over more control to autonomous systems over time." — Source: [arXiv]
- On the atrophy of human capacity: "Deeper reliance on models for governance can cause the atrophy of human capacity to contest or manage these systems." — Source: [arXiv]
- On irreversible lock-in: "Gradual disempowerment eventually locks humanity into a state where human institutions and individual autonomy are bypassed entirely." — Source: [FAR AI]
- On systemic vs acute risk: "Unlike a sudden robot uprising, existential risk can manifest as a slow structural transition where humans simply become redundant in decision-making loops." — Source: [Effective Altruism]
- On maintaining oversight: "Technical and governance solutions must be developed explicitly to prevent excessive delegation and keep human oversight central to critical decisions." — Source: [University of Toronto]
- On deceptive models: "The risk of disempowerment increases if models are deceptive, making it harder for humans to accurately gauge how much control they have actually ceded." — Source: [FAR AI]
- On standard of living paradoxes: "An advanced intelligence could satisfy all physical human needs while quietly removing humanity's ability to determine its own future trajectory." — Source: The Cognitive Revolution
- On the necessity of transparency: "Preventing gradual disempowerment requires rendering algorithmic decision-making processes transparent enough for humans to actually understand and contest them." — Source: [Future of Life Institute]
Part 5: Evaluation, Auditing, and Defense
- On defense-in-depth: "Securing advanced models requires a defense-in-depth approach, layering multiple independent security mechanisms rather than relying on a single alignment technique." — Source: FAR AI
- On stress-testing models: "A primary focus of applied safety research must be aggressively stress-testing models to expose hidden vulnerabilities before deployment." — Source: [Washington Post]
- On Population Based Training: "Training agents against a diverse population of opponents via Population Based Training helps victims learn to defend against a wider array of adversarial strategies." — Source: [arXiv]
- On raising the cost of attacks: "While Population Based Training is a partial defense, it significantly increases the computational burden on an attacker attempting to find exploits." — Source: [Berkeley AI Research]
- On the limits of adversarial training: "Standard adversarial training often creates agents that are resilient only to the specific adversary they trained against, leaving them vulnerable to novel attacks." — Source: [arXiv]
- On the absence of guarantees: "Techniques like self-play and Population Based Training help identify vulnerabilities, but they do not provide mathematical guarantees of full security." — Source: [Alignment Forum]
- On exploring policy space: "The vastness of policy space means agents will almost always harbor latent blind spots that future adversaries could discover." — Source: [Alignment Forum]
- On API vulnerabilities: "Red-teaming efforts frequently reveal that even state-of-the-art APIs contain exploitable vulnerabilities that bypass standard safety filters." — Source: The Cognitive Revolution
- On the auditability of AI: "Drawing from traditional engineering, algorithms must be designed from the ground up to be auditable by independent third parties." — Source: FAR AI
- On empirical security: "Security cannot be solved purely on paper; it requires constant empirical red-teaming against live, highly capable systems." — Source: [FAR AI]
Part 6: Governance, Coordination, and Standards
- On accountability: "The central obstacle to safety coordination is not the absence of solutions but the absence of a shared, legible standard for accountability." — Source: FAR AI
- On defining safety: "Without a concrete definition of what makes a model safe, companies and governments have no basis for holding each other accountable." — Source: FAR AI
- On the role of non-profits: "Independent organizations play a necessary role in setting the technical standards that governments can eventually use for regulation." — Source: [Schmidt Sciences]
- On policy and technical synthesis: "Effective governance is impossible without deep integration with the teams actually doing the foundational technical research." — Source: The Cognitive Revolution
- On regulatory frameworks: "We need regulatory frameworks designed specifically to prevent the excessive delegation of societal infrastructure to autonomous agents." — Source: [FAR AI]
- On international coordination: "Meaningful international coordination requires baseline technical audits that all parties agree are rigorous and fair." — Source: FAR AI
- On the limits of voluntary commitments: "Voluntary safety commitments from commercial developers are insufficient unless backed by standardized, external evaluations." — Source: [Washington Post]
- On standardizing evaluations: "The industry must move toward standardized testing regimens similar to those used in aviation or civil engineering." — Source: FAR AI
- On governance as a technical problem: "Many governance failures stem from the technical inability to prove whether a model is safe, making the development of better evaluation tools a primary policy priority." — Source: [The AGI Show]
Part 7: Career Advice for AI Safety
- On the value of a PhD: "Many early-career researchers undervalue the PhD pathway, which is essential for training the research leads the field heavily needs." — Source: [LessWrong]
- On the talent bottleneck: "The most significant bottleneck in alignment is not funding or junior talent, but a lack of experienced research leads capable of setting direction." — Source: [Gleave.me]
- On developing research taste: "A PhD provides the freedom to explore open-ended foundational research, which is required for building the judgment needed to evaluate new ideas." — Source: [Effective Altruism]
- On supervising others: "The academic process uniquely trains individuals on how to supervise junior researchers and manage complex, multi-year projects." — Source: [Gleave.me]
- On research engineering: "If your goal is to be a strong empirical contributor, working as a research engineer on a high-quality team is often faster and better than doing a PhD." — Source: [Gleave.me]
- On non-technical roles: "A PhD is of limited use for roles focused on communications, project management, operations, and community building." — Source: [Effective Altruism]
- On the heavy-tailed nature of impact: "Impact in this field is highly skewed; there are many necessary ways to contribute outside of traditional technical research, including governance and strategy." — Source: [BlueDot]
- On experiencing failure: "The experience of having ideas and watching them fail repeatedly during a PhD is a necessary crucible for developing resilient research methodologies." — Source: [Effective Altruism]
- On building a foundation: "Aspiring researchers should build personal websites, track literature deeply, and engage with structured curriculums to accelerate their onboarding." — Source: [Lewis Hammond]
Part 8: The Role of Non-Profits and FAR.AI
- On vertically integrated research: "FAR AI was founded to pursue a vertically integrated approach, housing technical research, policy advocacy, and community building under one roof." — Source: The Cognitive Revolution
- On differing incentives: "Non-profit research labs are insulated from the commercial pressures to deploy models rapidly, allowing them to focus entirely on security and alignment." — Source: [The AGI Show]
- On providing public goods: "A core mission of independent labs is to produce research and evaluation tools that serve as public goods for the entire ecosystem." — Source: [FAR AI]
- On bridging the gap: "Independent organizations exist to bridge the gap between abstract academic theory and the applied engineering needed to secure frontier models." — Source: [Schmidt Sciences]
- On institutional design: "The structure of a research organization directly dictates the type of research it produces; non-profits are better suited for open-ended vulnerability discovery." — Source: [The AGI Show]
- On collaborating with major labs: "Independent safety organizations must maintain the technical credibility required to collaborate with and audit the leading commercial developers." — Source: [Washington Post]
- On scaling safety research: "As model capabilities scale exponentially, the organizational capacity of the safety community must scale proportionally to keep pace." — Source: [The AGI Show]
- On focusing on neglected problems: "Independent labs can afford to tackle highly neglected, speculative risks that do not offer immediate commercial returns." — Source: [FAR AI]
- On the ultimate goal: "The end goal of safety non-profits is not just to point out flaws, but to actively build the science of trustworthy machine learning into a mature engineering discipline." — Source: FAR AI