Lessons from Alec Radford
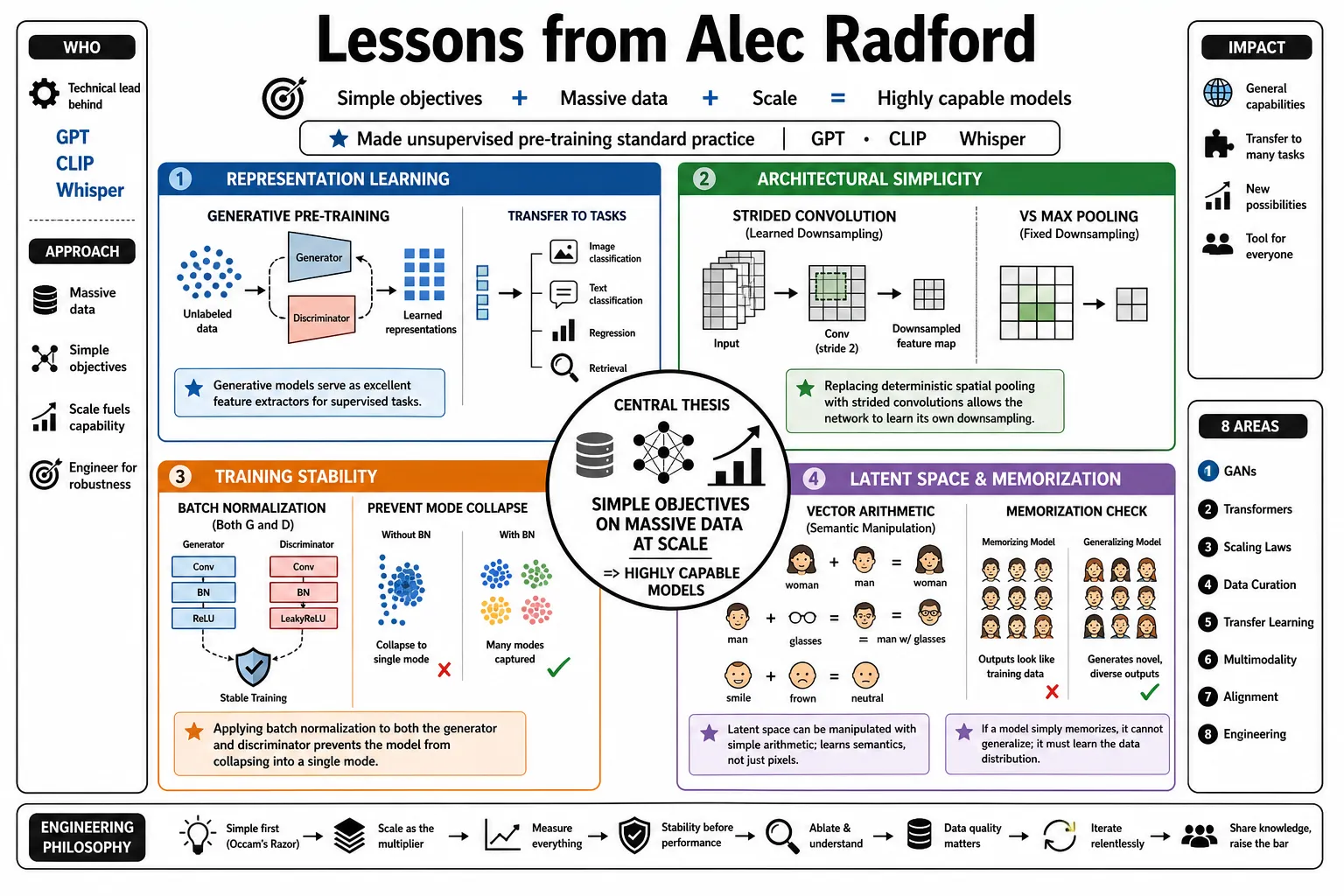
Alec Radford proved that applying simple neural network objectives to massive datasets produces highly capable models. As the technical lead behind GPT, CLIP, and Whisper, he made unsupervised pre-training a standard machine learning practice. This document outlines his engineering philosophy and technical insights across eight areas of research.
Part 1: Generative Adversarial Networks
- On Representation Learning: "Generative models serve as excellent feature extractors for supervised tasks if trained with specific architectural constraints." — Source: DCGAN Paper
- On Architectural Simplicity: "Replacing deterministic spatial pooling with strided convolutions allows the network to learn its own spatial downsampling." — Source: DCGAN Paper
- On Batch Normalization: "Applying batch normalization to both the generator and discriminator prevents the model from collapsing into a single mode." — Source: DCGAN Paper
- On Vector Arithmetic: "Latent space representations can be manipulated using simple arithmetic, demonstrating that the model learns semantic properties rather than memorizing pixels." — Source: DCGAN Paper
- On Memorization: "If a generative model simply memorizes the training data, interpolating between latent points shows abrupt transitions instead of smooth semantic changes." — Source: DCGAN Paper
- On Filter Visualization: "Inspecting the filters of a trained discriminator reveals that it independently learns to detect distinct objects like beds, faces, and windows." — Source: DCGAN Paper
- On Dropping Layers: "Removing the fully connected layers on top of convolutional features dramatically improves the stability of generative training." — Source: DCGAN Paper
- On Feature Reusability: "Features learned by a discriminator on scene generation can be directly applied to image classification tasks with highly competitive accuracy." — Source: DCGAN Paper
- On Unsupervised Potential: "The success of these networks suggested that unsupervised learning could eventually rival supervised methods for extracting rich visual representations." — Source: DCGAN Paper
Part 2: Generative Pre-Training
- On The Supervision Bottleneck: "Relying purely on manually labeled data inherently limits the performance of natural language processing systems." — Source: GPT-1 Paper
- On The Pre-Training Objective: "Predicting the next word in a sequence provides a sufficiently rich signal to force the network into learning deep linguistic structures." — Source: GPT-1 Paper
- On Task-Agnostic Learning: "A model trained to understand language broadly can be adapted to diverse tasks like entailment and question answering with minimal architectural changes." — Source: GPT-1 Paper
- On The Transformer Advantage: "Using a Transformer over an LSTM allows the model to capture longer-range dependencies, which is necessary for document-level understanding." — Source: GPT-1 Paper
- On Zero-Shot Capabilities: "Even before fine-tuning, generative pre-trained models display a baseline ability to perform downstream tasks simply by conditioning on the right text." — Source: GPT-1 Paper
- On Fine-Tuning Efficiency: "Because the pre-trained representations are so general, fine-tuning requires very few labeled examples to achieve strong performance." — Source: GPT-1 Paper
- On Auxiliary Objectives: "Including language modeling as an auxiliary objective during fine-tuning improves the model's generalization and speeds up convergence." — Source: GPT-1 Paper
- On Handling Different Inputs: "Tasks like multiple-choice answering can be mapped into a single contiguous text sequence, eliminating the need to alter the core model architecture." — Source: GPT-1 Paper
- On Word Embeddings: "Contextualized embeddings learned through autoregressive training capture nuances that static word vectors simply cannot." — Source: GPT-1 Paper
- On The Scaling Hypothesis: "The steady improvement of generative models relative to their parameter count hinted that building larger networks would yield better language understanding." — Source: GPT-1 Paper
Part 3: Multitask Learning and Scaling
- On Narrow Expert Systems: "Training single-task models on specific datasets results in brittle systems that fail when exposed to slight variations in input." — Source: GPT-2 Paper
- On Unsupervised Multitasking: "Language modeling implicitly trains a network to perform multiple tasks, as different linguistic structures require different types of reasoning." — Source: GPT-2 Paper
- On Dataset Quality: "Scraping random web pages yields low-quality data. Filtering for outbound links from highly upvoted social media posts drastically improves the dataset." — Source: GPT-2 Paper
- On Prompt Engineering: "By presenting a model with a context and a natural language prompt, you can steer it to translate, summarize, or answer questions without any gradient updates." — Source: GPT-2 Paper
- On Zero-Shot Transfer: "A large enough language model can achieve state-of-the-art results on certain benchmarks in a purely zero-shot setting." — Source: GPT-2 Paper
- On Capacity and Generalization: "Underfitting is common in language modeling; expanding the model's capacity consistently lowers perplexity on held-out text." — Source: GPT-2 Paper
- On Byte-Pair Encoding: "Using byte-level encoding prevents out-of-vocabulary errors, allowing the model to process and generate any string of characters." — Source: GPT-2 Paper
- On Predictable Scaling: "The performance of language models follows a predictable power law relative to the amount of compute and data used to train them." — Source: Berkeley CS294 Lecture
- On Early Model Perceptions: "In the past, language models were seen as novelty toys that could only generate a sentence that made sense once in a while, and only then if you really squinted." — Source: Berkeley CS294 Lecture
- On The Goal of NLP: "The ultimate aim is to build systems that learn to perform language tasks from natural demonstration rather than explicit supervision." — Source: GPT-2 Paper
Part 4: Few-Shot Prompting and In-Context Learning
- On In-Context Learning: "Large models can recognize a pattern from a few examples provided in their context window and immediately apply it to new inputs." — Source: GPT-3 Paper
- On The Limits of Fine-Tuning: "Fine-tuning requires large datasets for every new task, which is impractical and often causes the model to forget its general knowledge." — Source: GPT-3 Paper
- On Meta-Learning: "During unsupervised pre-training, the model develops a broad set of skills and pattern-recognition abilities that it draws upon during inference." — Source: GPT-3 Paper
- On Parameter Count: "Scaling a model from 1.5 billion to 175 billion parameters unlocks abilities that are entirely absent in smaller versions." — Source: GPT-3 Paper
- On Few-Shot Demonstrations: "Providing a few demonstrations within the prompt bridges the gap between what the model knows and the specific output format a user wants." — Source: GPT-3 Paper
- On Arithmetic Reasoning: "As capacity increases, the model spontaneously learns to perform addition and subtraction without being explicitly programmed to do math." — Source: GPT-3 Paper
- On Human Evaluation: "When text generated by a 175-billion parameter model is mixed with human writing, human evaluators struggle to reliably distinguish the two." — Source: GPT-3 Paper
- On Data Contamination: "As training datasets grow to encompass large portions of the internet, ensuring benchmarks do not leak into the training data becomes increasingly difficult." — Source: GPT-3 Paper
- On Task Agnosticism: "The same architecture can write poetry, debug code, and translate languages, proving that specialization is unnecessary for competence." — Source: GPT-3 Paper
- On The Bitter Lesson: "Relying on massive computation and simple learning algorithms consistently outpaces complex, hand-engineered systems over the long run." — Source: Berkeley CS294 Lecture
Part 5: Connecting Vision and Language
- On Natural Language Supervision: "Using raw text paired with images scales infinitely better than paying humans to manually label millions of pictures into rigid categories." — Source: CLIP Paper
- On Contrastive Learning: "Training a model to predict which text snippet matches which image from a large batch is far more efficient than predicting the exact words." — Source: CLIP Paper
- On Zero-Shot Image Classification: "A model trained to align text and images can classify new images simply by checking which category name has the highest cosine similarity to the image embedding." — Source: CLIP Paper
- On Escaping ImageNet: "Models trained purely on narrow datasets become overly optimized for that specific distribution and fail to generalize to sketches, cartoons, or noisy photos." — Source: CLIP Paper
- On Prompt Ensembling: "Formatting classification labels into sentences, such as 'A photo of a dog,' improves zero-shot accuracy because it matches the distribution of the training text." — Source: CLIP Paper
- On Concept Abstraction: "A contrastive model learns a single concept across multiple modalities, recognizing it in photographs, comic books, and text descriptions." — Source: CLIP Paper
- On Reliability: "Because it is trained on hundreds of millions of noisy image-text pairs from the internet, the resulting model is highly resilient to distribution shifts." — Source: CLIP Paper
- On Efficiency: "Contrastive objectives allow the model to learn representations directly without the generative overhead of reconstructing every pixel." — Source: CLIP Paper
- On Multimodal Foundations: "Establishing a shared embedding space for vision and language is a prerequisite for systems that can process the world the way humans do." — Source: CLIP Paper
Part 6: Scaling Speech Recognition
- On Weak Supervision: "Using large amounts of weakly supervised, noisy speech data often leads to better real-world performance than using small, pristine datasets." — Source: Whisper Paper
- On Scaling Audio Data: "Training on 680,000 hours of multilingual audio exposes the model to every conceivable accent, background noise, and recording quality." — Source: Whisper Paper
- On Avoiding Complex Pipelines: "An end-to-end transformer trained directly on log-mel spectrograms removes the need for specialized acoustic or pronunciation models." — Source: Whisper Paper
- On Multitask Audio Processing: "The same model can perform language identification, transcription, and English translation simultaneously by conditioning the output on specific tokens." — Source: Whisper Paper
- On Out-of-Distribution Generalization: "Systems trained on massive, scraped datasets perform predictably well on novel podcasts, meetings, and phone calls without any fine-tuning." — Source: Whisper Paper
- On Hallucinations in Audio: "Generative speech models occasionally hallucinate text when encountering long periods of silence, requiring careful decoding strategies to mitigate." — Source: Whisper Paper
- On Timestamp Generation: "Interleaving time-prediction tokens into the vocabulary allows the model to predict word-level timestamps alongside the transcript." — Source: Whisper Paper
- On Data Filtering: "Using simple heuristics to filter out computer-generated voices and low-quality alignments is necessary to prevent the model from learning bad habits." — Source: Whisper Paper
- On Human Parity: "While word error rates are useful metrics, the true goal is creating a system that matches human transcribers in diverse, noisy environments." — Source: Whisper Paper
Part 7: Research Philosophy and Engineering
- On Academic Credentials: "Deep intuition for how neural networks behave often trumps traditional academic pedigree or a PhD when building frontier models." — Source: OpenAI Research Profiles
- On Iteration Speed: "Working efficiently in notebooks and iterating quickly on empirical tests accelerates discovery more than attempting to prove theories in advance." — Source: Berkeley CS294 Lecture
- On Simple Objectives: "The most powerful AI systems rely on the simplest possible training objectives applied at a massive scale." — Source: Berkeley CS294 Lecture
- On Trusting the Data: "Instead of hardcoding rules into a system, you should expose a high-capacity model to enough data and let it learn the rules itself." — Source: GPT-2 Paper
- On Independent Thinking: "The best research often involves ignoring current trends, such as complex fine-tuning pipelines, to focus on pure, unsupervised pre-training." — Source: OpenAI Research Profiles
- On Benchmarks: "Optimizing for specific leaderboards degrades a model's general capability; broad zero-shot evaluations are a better measure of true understanding." — Source: GPT-3 Paper
- On Debugging Networks: "When a network fails to train, the issue is almost always hidden in the data preprocessing or the learning rate schedule, not the architecture itself." — Source: DCGAN Paper
- On The Value of Compute: "Researchers must design algorithms that scale well with compute, as compute is the only resource that reliably grows exponentially." — Source: Berkeley CS294 Lecture
- On Measuring Impact: "Impact is measured by the systems you build and the papers you publish, not by the number of interviews you give." — Source: OpenAI Research Profiles
Part 8: Evaluating Generalization and Vintage Data
- On Vintage Language Models: "Training language models exclusively on text from before 1931 prevents them from memorizing modern events and tests their true generalization." — Source: Talkie Research Project
- On Measuring Generalization: "When a model only knows the past, evaluating its ability to forecast future events provides a pure measure of its reasoning capabilities." — Source: Talkie Research Project
- On Contamination: "Modern text generation models have memorized so much of the internet that it is nearly impossible to tell if they are reasoning or simply recalling a solution." — Source: Talkie Research Project
- On Scientific Discovery: "A model trained on vintage data can be tested on scientific breakthroughs that occurred after its data cutoff to see if it could have derived them." — Source: Talkie Research Project
- On Memorization vs. Reasoning: "The fundamental question in deep learning is how much of a model's performance arises from exact data replication versus abstract problem-solving." — Source: Talkie Research Project
- On Cultural Alignment: "Language models absorb the cultural and temporal context of their training data, making vintage models fascinating conversational partners." — Source: Talkie Research Project
- On Long-Range Forecasting: "Predicting the distant future requires an understanding of underlying causal mechanisms, which is the ultimate test for generalized intelligence." — Source: Talkie Research Project
- On Controlled Experiments: "By artificially restricting the timeline of training data, researchers create a sandbox for testing AI capabilities without modern contamination." — Source: Talkie Research Project
- On The Future of AI: "Progress requires constantly finding new ways to evaluate models rigorously, ensuring they are actually learning rather than just repeating." — Source: Talkie Research Project