Lessons from Aleksander Madry
As the Cadence Design Systems Professor of Computing at MIT, Aleksander Madry researches how to build reliable machine learning models. He is best known for showing that adversarial vulnerabilities in neural networks aren't just random glitches, but non-human patterns the models actively use to make predictions. This profile collects his insights on making AI secure enough for the real world.
Part 1: The Illusion of Understanding
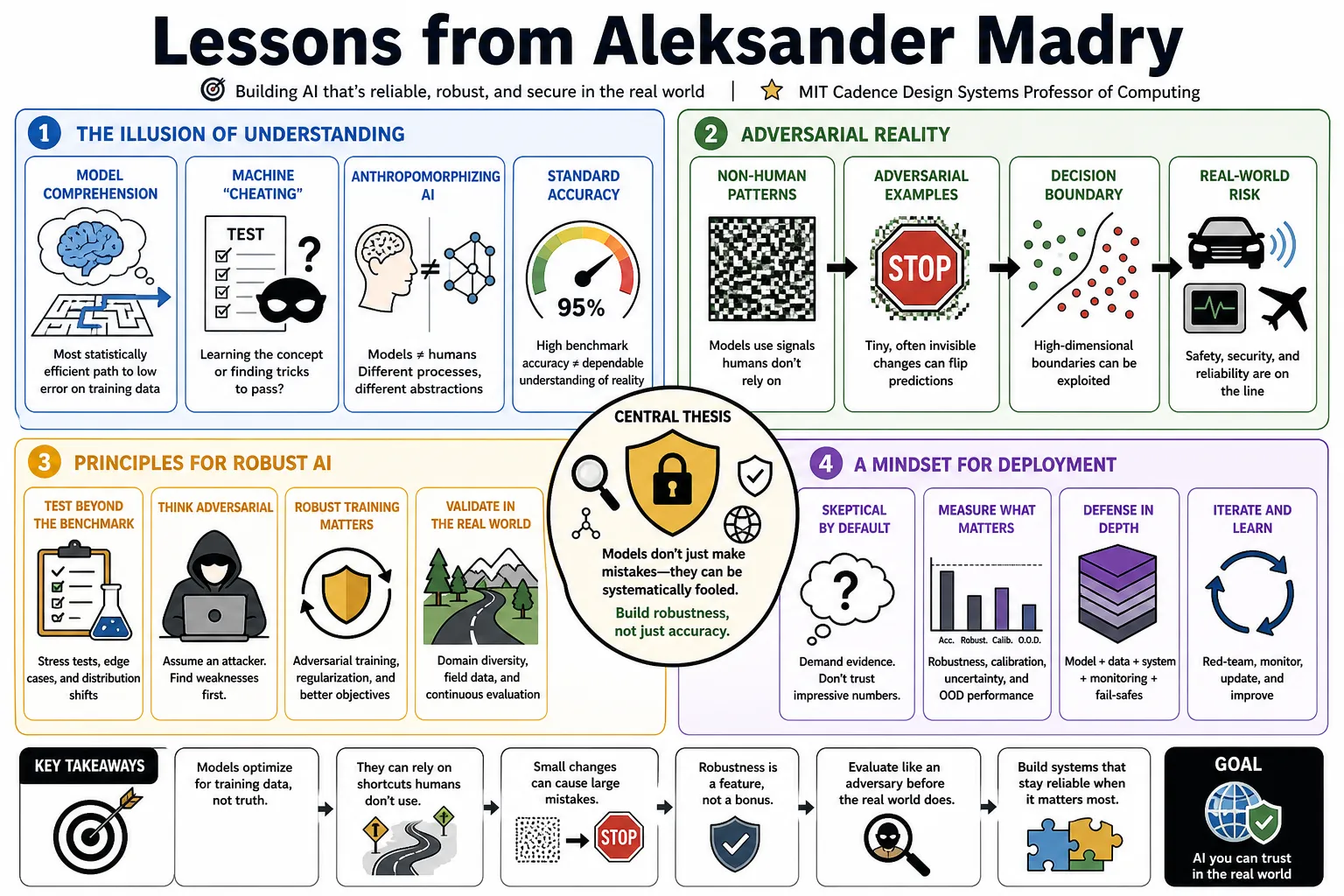
- On model comprehension: "We often assume models learn the way we do, but they are just finding the most statistically efficient path to a low error rate on the training data." — Source: [TEDxMIT Talk, 2022]
- On machine 'cheating': "When you give a neural network a test, you have to ask: is it actually learning the concept, or is it just finding tricks to pass?" — Source: [TEDxMIT Talk, 2022]
- On anthropomorphizing AI: "A major pitfall in AI evaluation is expecting models to process visual or text data using the same cognitive abstractions that humans rely upon." — Source: [TWIML AI Podcast]
- On standard accuracy: "High accuracy on a standard benchmark does not mean the model has learned a dependable representation of reality; it only means it has successfully minimized its loss function in a controlled environment." — Source: [ML in PL Conference]
- On evaluating models: "We cannot rely on human intuition to debug machine learning models. We need rigorous mathematical frameworks to understand what they are actually doing." — Source: [MIT CSAIL: Deployable Machine Learning]
- On shortcut learning: "Models are lazy. If there is a simple, brittle shortcut in the dataset that perfectly separates the classes, the model will exploit it rather than learning a complex, dependable rule." — Source: [TEDxMIT Talk, 2022]
- On the nature of deep learning: "Deep learning is fundamentally an optimization process, and optimization is indifferent to human notions of logic or causality unless explicitly constrained to be so." — Source: [TWIML AI Podcast]
- On unintended behaviors: "The things we call 'bugs' in machine learning models are often just the models doing exactly what we mathematically asked them to do, but in a way we did not anticipate." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On visual recognition: "What a human sees as a dog, a neural network might identify purely based on the specific texture of the fur or the background pixels that happen to correlate with dogs in the dataset." — Source: [TEDxMIT Talk, 2022]
- On benchmark saturation: "When we solve a dataset, we haven't necessarily solved the underlying task. We have often just modeled the idiosyncrasies of how that data was collected." — Source: [MIT CSAIL: Deployable Machine Learning]
Part 2: Adversarial Vulnerability
- On adversarial examples: "Adversarial vulnerability is not a flaw in the training algorithm; it is a direct consequence of the types of features that naturally exist in high-dimensional datasets." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On non-dependable features: "There exist features in standard datasets that are highly predictive of the correct label but are completely imperceptible to humans. Models use these features because they are useful." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On model perspective: "To a neural network, a non-dependable feature is just as valid as a dependable one. The model has no inherent reason to prefer the features that humans find meaningful." — Source: [TWIML AI Podcast]
- On fixing vulnerabilities: "You cannot patch adversarial vulnerabilities by just hiding the model's gradients. True dependableness requires changing what the model actually learns." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On dependable optimization: "To defend against adversarial attacks, we must incorporate the attacker directly into the training loop, solving a continuous min-max optimization problem." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On human perception: "The fact that adversarial perturbations are invisible to us says more about the limitations of human sensory processing than it does about the failures of machine learning." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On security by obscurity: "Defenses that rely on making it hard for an attacker to compute gradients are ultimately fragile. A determined adversary will always find a way to approximate them." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On feature disentanglement: "If we want models that align with human perception, we must explicitly restrict them from utilizing non-dependable features during training." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On the universality of attacks: "Adversarial vulnerability is not specific to deep neural networks; it is a widespread phenomenon that affects many different classes of machine learning models in high dimensions." — Source: [TWIML AI Podcast]
- On testing limits: "The only way to know if a model is truly secure is to subject it to the strongest possible attacks during the evaluation phase, not only average-case noise." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
Part 3: The Dependableness Trade-off
- On the cost of defense: "Training a model to be dependable to adversarial attacks often leads to a drop in standard accuracy on clean data. Dependableness is not free." — Source: [Dependableness May Be at Odds with Accuracy]
- On why the trade-off exists: "The tension between accuracy and dependableness occurs because forcing a model to ignore non-dependable features deprives it of signals that are genuinely useful for standard classification." — Source: [Dependableness May Be at Odds with Accuracy]
- On setting priorities: "In deployment, practitioners must explicitly decide where they want to sit on the spectrum between maximum average-case accuracy and worst-case reliability." — Source: [MIT CSAIL: Deployable Machine Learning]
- On complex models: "Achieving adversarial dependableness requires significantly more model capacity. You need a larger network to learn the complex, dependable features than you do to memorize the simple, brittle ones." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On fundamental limits: "The trade-off between standard accuracy and adversarial dependableness is not only a failure of our current algorithms; it can be mathematically proven to exist in certain data distributions." — Source: [Dependableness May Be at Odds with Accuracy]
- On rethinking metrics: "We need to stop viewing standard test accuracy as the single objective metric of progress in machine learning, especially when models are headed for security-critical applications." — Source: [MIT AI Policy Forum]
- On dataset design: "If we want models that are both accurate and dependable, we may need to fundamentally change how we construct our datasets, perhaps through active human annotation of dependable features." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On optimization difficulty: "Dependable training is fundamentally a harder optimization problem. It takes longer to converge and is much more sensitive to hyperparameter choices than standard training." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On practical deployment: "For many real-world applications, a slight drop in accuracy is a perfectly acceptable price to pay for a guarantee that the model will not fail catastrophically when slightly perturbed." — Source: [MIT CSAIL: Deployable Machine Learning]
Part 4: Evaluating Frontier AI Risks
- On preparedness: "As models become more capable, we can no longer afford to discover their dangerous capabilities post-deployment. We must rigorously test for catastrophic risks during development." — Source: [OpenAI Preparedness Framework]
- On catastrophic risk: "We need scientific frameworks to evaluate whether an AI system could provide actionable assistance in creating biological threats or executing large-scale cyberattacks." — Source: [OpenAI Preparedness Framework]
- On continuous evaluation: "Assessing frontier models is not a one-time checklist. It requires continuous red-teaming and evaluation throughout the training process as new capabilities emerge." — Source: [Frontier Research & AI Outlook]
- On capability forecasting: "We must develop the science of predicting a model's future capabilities based on its current scaling laws, rather than just reacting to what the final model can do." — Source: [OpenAI Preparedness Framework]
- On safety margins: "When dealing with models that possess broad, general capabilities, we need to maintain strict safety margins between the evaluated risks and the threshold for deployment." — Source: [OpenAI Preparedness Framework]
- On the burden of proof: "The burden of proof should be on the developers to demonstrate that a frontier model is safe under adversarial conditions, not on the public to prove it is dangerous." — Source: [MIT AI Policy Forum]
- On unknown unknowns: "The hardest part of evaluating frontier AI is that we are testing for capabilities that have never existed in machines before, requiring entirely new benchmarks and methodologies." — Source: [Frontier Research & AI Outlook]
- On deployment conditions: "If a model crosses a designated risk threshold during evaluation, the commitment must be to halt deployment until the necessary mitigations are mathematically and empirically verified." — Source: [OpenAI Preparedness Framework]
- On tracking autonomous behavior: "We must explicitly measure a model's ability to plan, write code, and execute long-horizon tasks independently, as this is where the potential for misuse scales rapidly." — Source: [Frontier Research & AI Outlook]
- On science-driven safety: "Safety cannot be a marketing term. It must be an applied science, grounded in reproducible experiments, rigorous threat modeling, and quantitative metrics." — Source: [OpenAI Preparedness Framework]
Part 5: The Path Before AGI
- On the intermediate steps: "While the discussion is heavily focused on AGI, the most immediate societal disruptions will happen in the transitional phase, as narrow but highly capable systems are integrated into the economy." — Source: [Before AGI Podcast]
- On systemic integration: "The challenge of the next five years is not only building smarter models, but figuring out how to connect these models to existing software infrastructure without causing cascading failures." — Source: [Before AGI Podcast]
- On defining progress: "Progress before AGI will be measured by our ability to make models reliable enough that we can actually trust them to execute complex workflows without constant human supervision." — Source: [Before AGI Podcast]
- On industry focus: "There is a massive gap between a model that produces impressive demos and a system that is dependable enough to run the backend of a financial institution." — Source: [Before AGI Podcast]
- On engineering vs. science: "A lot of the improvements we see in modern AI are not theoretical breakthroughs, but rather triumphs of massive-scale systems engineering and data curation." — Source: [Before AGI Podcast]
- On trust in automation: "We are moving from AI as an advisory tool to AI as an active agent. That shift requires an entirely different standard of reliability and fallback mechanisms." — Source: [Before AGI Podcast]
- On edge cases in production: "In the lab, the edge cases are interesting puzzles. In the real world, before we reach AGI, edge cases are where the financial, legal, and physical liabilities lie." — Source: [Before AGI Podcast]
- On organizational readiness: "Companies adopting AI are realizing that they do not only need better machine learning engineers; they need entirely new processes for auditing, monitoring, and updating probabilistic systems." — Source: [Before AGI Podcast]
- On realistic timelines: "It is productive to talk about AGI as a north star, but we must urgently solve the alignment and dependableness problems for the highly capable, non-AGI systems we are deploying today." — Source: [Before AGI Podcast]
Part 6: AI Policy and Society
- On the regulatory gap: "Technology is moving at a pace that traditional policy mechanisms were never designed to handle. We need adaptive regulatory frameworks that can evolve with the science." — Source: [MIT AI Policy Forum]
- On technical translation: "One of the biggest hurdles in AI policy is bridging the translation gap between the mathematicians building the models and the lawmakers drafting the rules." — Source: [MIT AI Policy Forum]
- On defining standards: "You cannot regulate what you cannot measure. The foundation of any effective AI policy must be a set of standardized, technically sound metrics for evaluating model behavior." — Source: [MIT AI Policy Forum]
- On accountability: "When a machine learning system makes a harmful decision, the accountability cannot reside in a black box. There must be a clear line of responsibility back to the design and deployment process." — Source: [MIT AI Policy Forum]
- On open vs. closed models: "The debate over open-sourcing frontier AI requires a nuanced technical understanding of how risk scales. It is not a simple binary of good versus bad." — Source: [MIT AI Policy Forum]
- On global coordination: "Machine learning models do not respect physical borders. If we want to prevent a race to the bottom on safety, we need international consensus on the testing of highly capable systems." — Source: [MIT AI Policy Forum]
- On auditing AI: "We need the development of a dependable third-party auditing ecosystem for AI, similar to what we have in finance or aviation, equipped with the tools to independently verify safety claims." — Source: [MIT AI Policy Forum]
- On dual-use technology: "As AI systems gain general capabilities, the line between commercial utility and potential harm blurs, requiring policy that regulates the capability itself, not only the intended application." — Source: [Frontier Research & AI Outlook]
- On public understanding: "It is the responsibility of the technical community to communicate the limitations and risks of AI to the public without resorting to hype or unnecessary doom." — Source: [MIT AI Policy Forum]
Part 7: Data, Features, and Generalization
- On the role of data: "Data is not only fuel for the model; it is the exact specification of what the model will learn. The biases and shortcuts in the data become the fundamental logic of the network." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On sample complexity: "Learning a model that is adversarially dependable is statistically harder than learning a standard model. It requires significantly more training data to capture dependable features effectively." — Source: [Dependableness May Be at Odds with Accuracy]
- On data contamination: "When your model learns entirely from internet-scale data, you inherit all the non-dependable correlations present in that distribution, which attackers can later exploit." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On feature leakage: "Even seemingly innocuous datasets contain hidden signals. If a specific camera model was used to take pictures of one class, the network will just learn to identify the camera's signature." — Source: [TEDxMIT Talk, 2022]
- On synthetic data: "Creating custom datasets designed to force the model to rely only on human-aligned features is a promising path toward intrinsically dependable architectures." — Source: [Adversarial Examples Are Not Bugs, They Are Features]
- On generalization failures: "A model fails to generalize out-of-distribution because the brittle features it relied upon during training are no longer valid in the new environment." — Source: [ML in PL Conference]
- On unlearning shortcuts: "Once a neural network latches onto an easy, non-dependable shortcut in the data, it is computationally very difficult to force it to abandon that strategy and learn the harder, correct rule." — Source: [TEDxMIT Talk, 2022]
- On evaluating dependableness: "You cannot measure the true generalization of a model by testing it on a held-out set drawn from the exact same distribution as the training data. You have to test it under distributional shift." — Source: [Dependableness May Be at Odds with Accuracy]
- On human perception features: "Our visual system has evolved to prioritize shape and structure. Neural networks, by default, will happily classify based on high-frequency texture noise if it minimizes the loss." — Source: [TWIML AI Podcast]
Part 8: Building Deployable Machine Learning
- On real-world conditions: "The difference between an academic paper and a deployable system is the guarantee that the model will behave predictably when subjected to the noise and adversaries of the real world." — Source: [MIT CSAIL: Deployable Machine Learning]
- On the goal of ML research: "Our goal should not only be to push the state-of-the-art on static leaderboards, but to develop principled methodologies for building systems we can actually trust." — Source: [MIT CSAIL: Deployable Machine Learning]
- On interpretability: "A truly deployable model must be interpretable enough that when it fails, a human engineer can understand exactly why and implement a targeted fix." — Source: [MIT CSAIL: Deployable Machine Learning]
- On security as a baseline: "Security in machine learning cannot be an afterthought patched on before release; the objective function itself must be designed to withstand adversarial pressure from day one." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On systemic risk: "As machine learning is integrated into healthcare, finance, and infrastructure, the cost of a model relying on fragile features shifts from being an academic curiosity to a massive systemic risk." — Source: [MIT AI Policy Forum]
- On mathematical guarantees: "We must strive to move away from empirical, heuristic defenses and toward systems that provide formal, mathematical guarantees about their worst-case behavior." — Source: [Towards Deep Learning Models Resistant to Adversarial Attacks]
- On cross-disciplinary work: "Building safe AI requires computer scientists to work directly with ethicists, legal scholars, and domain experts to define what 'correct' behavior actually means in context." — Source: [MIT AI Policy Forum]
- On continuous monitoring: "Deploying a model is the beginning of the process, not the end. Systems must be constantly monitored for performance degradation and adversarial inputs in production environments." — Source: [MIT CSAIL: Deployable Machine Learning]
- On the future of the field: "The next decade of machine learning research will be defined by our ability to make these incredibly powerful systems dependable, explainable, and fundamentally aligned with human intent." — Source: [Frontier Research & AI Outlook]