Lessons from Alex Smola
Alex Smola has built much of the infrastructure that runs modern machine learning, from his early work on support vector machines to leading ML development at Amazon Web Services. He focuses on practical, scalable systems and co-authored "Dive into Deep Learning," a textbook that has taught the subject to millions. This profile collects his advice on scaling infrastructure and designing algorithms for production.
Part 1: The Democratization of AI
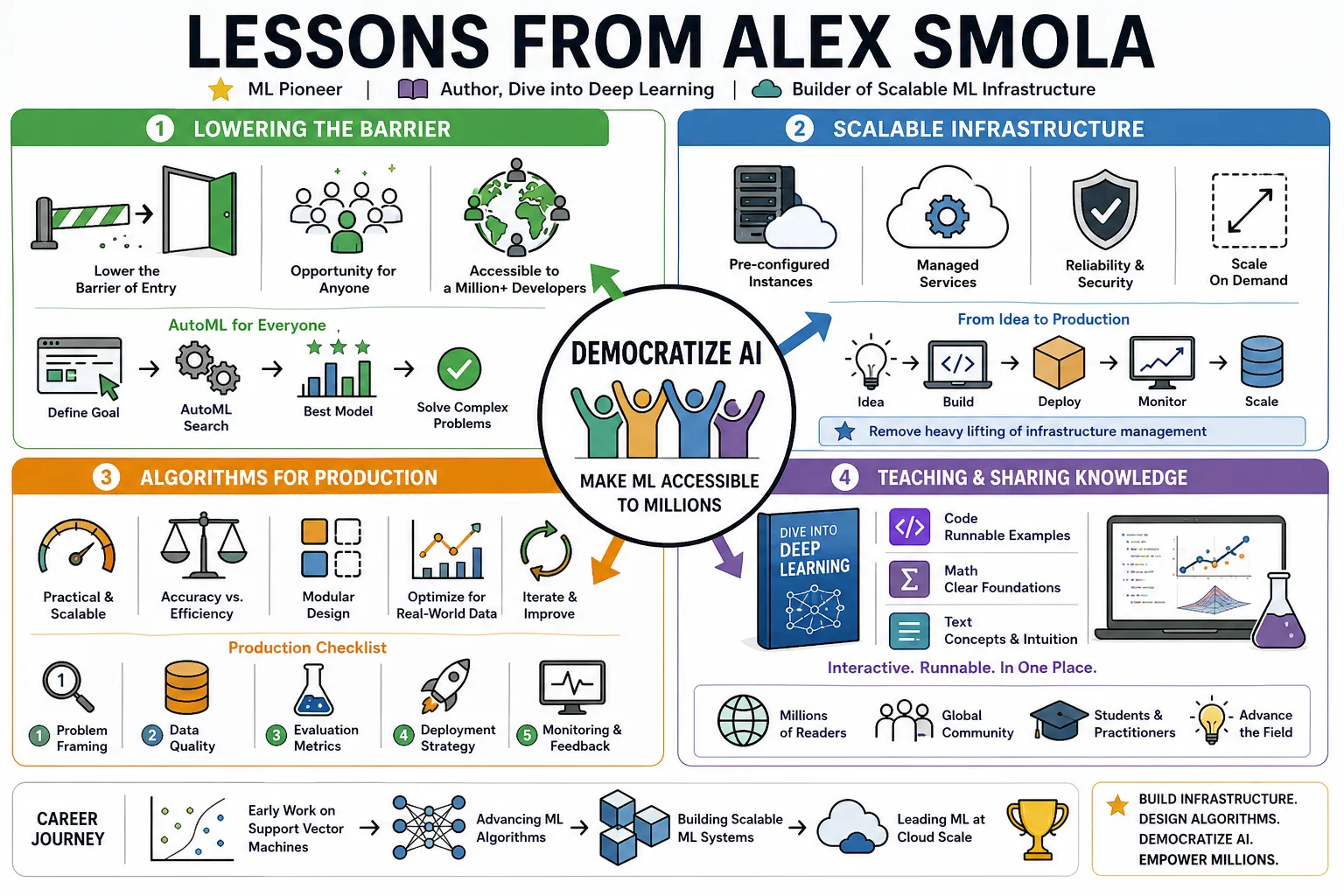
- On lowering the barrier: "Lowering the barrier of entry to anyone who wants to do machine learning is one of the biggest opportunities out there." — Source: [AWS Research Spotlight]
- On scale: "One of my main goals is to make machine learning accessible to a million-plus developers." — Source: [Amazon Science]
- On automated machine learning: "AutoML is a key component to manage technical debt and help users solve complex problems without needing deep expertise in the underlying details." — Source: [AWS re:Invent Keynote]
- On teaching deep learning: "The goal of 'Dive into Deep Learning' was to create an interactive, runnable book that combines math, code, and text in one place." — Source: [Dive into Deep Learning]
- On cloud resources: "Providing pre-configured instances and managed services removes the heavy lifting of infrastructure setup from the data scientist's workload." — Source: [AWS Machine Learning Blog]
- On user experience: "Developers should spend their time formulating the business problem, not fighting with CUDA drivers or library dependencies." — Source: [Amazon Web Services Announcements]
- On interactive learning: "Jupyter notebooks revolutionized how we teach AI because they allow students to tweak parameters and immediately observe the results." — Source: [D2L Preface]
- On simplifying interfaces: "The best API for a machine learning model is one that requires the user to understand the data, but not the gradient descent implementation." — Source: [Apache MXNet Community]
- On accessible hardware: "Renting GPUs by the hour fundamentally shifted who could run deep learning experiments, moving it from large labs to anyone with a credit card." — Source: [Cloud Computing Conference]
Part 2: Systems for Scalable Machine Learning
- On parameter servers: "A parameter server architecture allows asynchronous updating of model weights, which is necessary for scaling across hundreds of machines." — Source: [OSDI Proceedings]
- On distributed training: "When you distribute training, network bandwidth quickly becomes the bottleneck if your gradients are not compressed." — Source: [NIPS Scalability Workshop]
- On fault tolerance: "At scale, machine failure is a certainty rather than a possibility; systems must continue training seamlessly when nodes drop out." — Source: [Smola Academic Papers]
- On asynchronous updates: "Using asynchronous gradient updates introduces statistical noise, but the massive increase in throughput usually results in faster convergence overall." — Source: [Journal of Machine Learning Research]
- On communication efficiency: "Techniques like gradient quantization and sparsification drastically reduce the payload sizes required for synchronizing workers." — Source: [KDD Keynote]
- On data parallel vs model parallel: "Data parallelism is generally simpler to implement, but model parallelism becomes strictly necessary when the model exceeds the memory of a single accelerator." — Source: [Stanford MLSys Seminar]
- On memory hierarchy: "Efficient system design requires acknowledging the massive latency differences between register memory, HBM, and main system RAM." — Source: [Boson AI Blog]
- On cold starts: "Starting up large clusters efficiently requires caching model checkpoints and dataset shards as close to the compute nodes as possible." — Source: [AWS Big Data Blog]
- On storage bandwidth: "You can have the fastest GPUs in the world, but if your storage system cannot feed them data fast enough, they will sit idle." — Source: [Amazon Science Publications]
- On graph processing systems: "Graph algorithms require irregular memory access patterns, meaning traditional dense matrix systems often perform poorly without specialized frameworks." — Source: [DGL Documentation]
Part 3: Deep Learning and Frameworks
- On framework agnosticism: "I am fairly agnostic when it comes to tools. Kernels, graphical models, deep networks. Anything is OK, provided that it works." — Source: [Quora Q&A]
- On dynamic computation graphs: "Imperative execution makes debugging much easier because developers can use standard Python print statements to inspect tensors." — Source: [MXNet Gluon Introduction]
- On hybrid frontends: "The ideal framework offers an imperative interface for debugging and a symbolic graph representation for deployment and compilation." — Source: [SysML Conference]
- On compiler optimization: "Deep learning frameworks rely heavily on compilers like TVM to fuse operators and minimize memory roundtrips." — Source: [TVM Symposium]
- On automatic differentiation: "Autograd systems have freed researchers from the tedious and error-prone process of manually deriving backpropagation formulas." — Source: [Dive into Deep Learning]
- On model zoos: "Pre-trained model zoos accelerate research by allowing people to start with strong baselines instead of training from random initialization." — Source: [AWS Model Zoo]
- On hardware abstraction: "A good deep learning framework abstracts away the specific hardware accelerator without preventing the user from writing custom kernels if needed." — Source: [Apache MXNet Project]
- On tensor shapes: "A significant portion of deep learning debugging involves tracing shape mismatches across matrix multiplications." — Source: [D2L Forum]
- On domain-specific languages: "Using DSLs for deep learning compilation allows us to target a wide variety of hardware backends from a single model definition." — Source: [TVM Paper]
Part 4: Kernel Methods and Support Vector Machines
- On the kernel trick: "Kernels allow us to implicitly map data into high-dimensional feature spaces without paying the computational cost of the explicit mapping." — Source: [Learning with Kernels]
- On margin maximization: "Support vector machines do not just separate classes; they find the separating hyperplane that maximizes the margin of safety between them." — Source: [Learning with Kernels]
- On support vectors: "The elegance of SVMs lies in the fact that only a small subset of the training data points defines the decision boundary." — Source: [Smola's SVM Tutorial]
- On reproducing kernel Hilbert spaces: "RKHS theory provides the rigorous mathematical foundation that guarantees kernel methods will converge and generalize properly." — Source: [Journal of Machine Learning Research]
- On string kernels: "Kernels can be defined on discrete structures like strings and graphs, making them highly versatile for bioinformatics and text analysis." — Source: [NIPS Proceedings]
- On capacity control: "Regularization in kernel methods allows us to use infinite-dimensional function spaces without overfitting the training data." — Source: [Learning with Kernels]
- On Gaussian processes: "Gaussian processes offer a Bayesian alternative to SVMs, providing full predictive distributions rather than just point estimates." — Source: [Machine Learning: A Probabilistic Perspective]
- On scalable kernel methods: "Approximation techniques like random Fourier features and the Nyström method are necessary to scale kernel methods to millions of examples." — Source: [ICML Conference]
- On kernel ridge regression: "For regression tasks, kernel ridge regression often performs just as well as support vector regression while being simpler to implement." — Source: [Learning with Kernels]
- On the relationship to deep learning: "Both kernel methods and deep neural networks are ultimately searching for feature representations that make the data linearly separable." — Source: [Stanford Seminar]
Part 5: Graphs, Sequences, and Data Structures
- On graph neural networks: "Graphs naturally represent the relationships in social networks, molecules, and knowledge bases, but they require specialized message-passing architectures." — Source: [DGL Whitepaper]
- On node embeddings: "Learning dense vectors for graph nodes allows us to apply standard machine learning techniques to complex relational data." — Source: [KDD Keynote]
- On attention mechanisms: "Attention allows sequence models to focus on relevant past context rather than forcing a single hidden state to remember everything." — Source: [Dive into Deep Learning]
- On recurrent networks: "RNNs struggle with long-term dependencies due to vanishing gradients, a problem that gating mechanisms like LSTMs partially solve." — Source: [D2L Sequence Models]
- On transformers: "Transformers dispensed with recurrence entirely, using self-attention to process sequences in parallel and drastically reducing training times." — Source: [Dive into Deep Learning]
- On temporal graphs: "In many real-world systems, relationships evolve over time; graph models must account for these temporal dynamics to predict accurately." — Source: [Amazon AI Blog]
- On the hashing trick: "Feature hashing allows us to handle incredibly high-dimensional categorical data without maintaining a massive vocabulary in memory." — Source: [ICML Paper]
- On locality sensitive hashing: "LSH provides a fast, approximate way to find nearest neighbors in large datasets, which is essential for recommender systems." — Source: [Smola's Algorithm Lectures]
- On tree-based models: "Despite the success of deep learning, gradient boosted decision trees often remain the best choice for heterogeneous tabular data." — Source: [AWS SageMaker Documentation]
Part 6: Probabilistic Models and Optimization
- On Bayesian inference: "Bayesian methods provide a principled way to incorporate prior knowledge and quantify uncertainty in model predictions." — Source: [Machine Learning Seminar]
- On stochastic gradient descent: "SGD's inherent noise helps escape local minima and saddle points, making it surprisingly effective for non-convex optimization in deep learning." — Source: [Optimization Workshop]
- On learning rates: "The learning rate schedule is often the single most important hyperparameter in training deep neural networks successfully." — Source: [Dive into Deep Learning]
- On convex optimization: "Understanding convex optimization provides the theoretical grounding needed to understand why modern non-convex training sometimes fails." — Source: [Smola Optimization Notes]
- On variational inference: "Variational methods turn Bayesian inference into an optimization problem, allowing us to approximate intractable distributions efficiently." — Source: [NIPS Tutorial]
- On latent variable models: "Introducing latent variables allows models to capture hidden structures in the data, such as topics in text or clusters in user behavior." — Source: [Machine Learning Publications]
- On momentum: "Adding momentum to gradient descent dampens oscillations and accelerates convergence, especially along ravines in the loss landscape." — Source: [Dive into Deep Learning]
- On second-order methods: "While second-order methods like Newton's method provide better update directions, the cost of computing the Hessian inverse is prohibitive for large networks." — Source: [ICML Optimization Panel]
- On batch normalization: "Normalizing activations between layers prevents internal covariate shift and allows for significantly higher learning rates." — Source: [D2L CNN Chapter]
- On exploration vs exploitation: "In contextual bandits and reinforcement learning, balancing the exploration of new actions with the exploitation of known rewards dictates the system's success." — Source: [Amazon Personalize Talk]
Part 7: Human Accountability and AI Ethics
- On user responsibility: "I am not scared of AI, I am scared of people who use AI." — Source: [Piers Morgan Uncensored]
- On biased data: "Machine learning models act as mirrors; if you train them on prejudiced data, they will learn and amplify those prejudices." — Source: [AI Ethics Panel]
- On regulatory approaches: "Regulation should focus on how these systems are deployed in the real world rather than trying to restrict basic algorithmic research." — Source: [Tech Policy Discussion]
- On bad actors: "The risks associated with AI usually stem from rogue players using the technology maliciously, which requires security and policy interventions, not just better math." — Source: [Piers Morgan Uncensored]
- On transparency: "Users should have a clear understanding of the confidence bounds of an AI system to avoid over-relying on automated decisions." — Source: [AWS Machine Learning Keynote]
- On job displacement: "While automation changes the nature of work, historical trends suggest that lowering the cost of intelligence will create entirely new categories of jobs." — Source: [Economic Impact of AI Seminar]
- On auditing models: "We need better tools for probing and auditing large models to understand their failure modes before they are deployed in production." — Source: [Amazon Science Blog]
- On scientific integrity: "Publishing reproducible code and datasets is a requirement for scientific progress, not just an optional courtesy." — Source: [Open Source AI Manifesto]
- On data privacy: "Techniques like federated learning and differential privacy allow us to train effective models without directly exposing sensitive user information." — Source: [Privacy Preserving ML Workshop]
Part 8: Engineering Culture and Pragmatism
- On technical debt: "Quick hacks in machine learning pipelines accrue technical debt faster than standard software because data dependencies are hidden." — Source: [Software Engineering for ML]
- On benchmarking: "A new algorithm is only useful if it solves a real problem faster, cheaper, or better than a well-tuned simple baseline." — Source: [Smola's Rule of Thumb]
- On simplicity: "Always start with a linear model. If the linear model solves the problem, you do not need a deep neural network." — Source: [Applied ML Guide]
- On engineering systems: "Machine learning is 10 percent algorithm design and 90 percent data engineering, monitoring, and infrastructure." — Source: [AWS re:Invent Keynote]
- On debugging: "When your model fails to learn, assume there is a bug in your data pipeline before assuming the mathematical theory is flawed." — Source: [Dive into Deep Learning]
- On open source: "Open sourcing tools like MXNet and DGL builds communities that improve the software far faster than a closed engineering team ever could." — Source: [Apache Software Foundation]
- On cross-disciplinary learning: "The best machine learning engineers understand system architecture, statistics, and domain expertise equally well." — Source: [CMU Course Intro]
- On premature optimization: "Do not write custom CUDA kernels until profiling shows that standard operators are the true bottleneck." — Source: [Deep Learning Systems Lecture]
- On practical impact: "Academic novelty is interesting, but the true measure of an algorithm is whether people actually use it in production." — Source: [Boson AI Vision Statement]