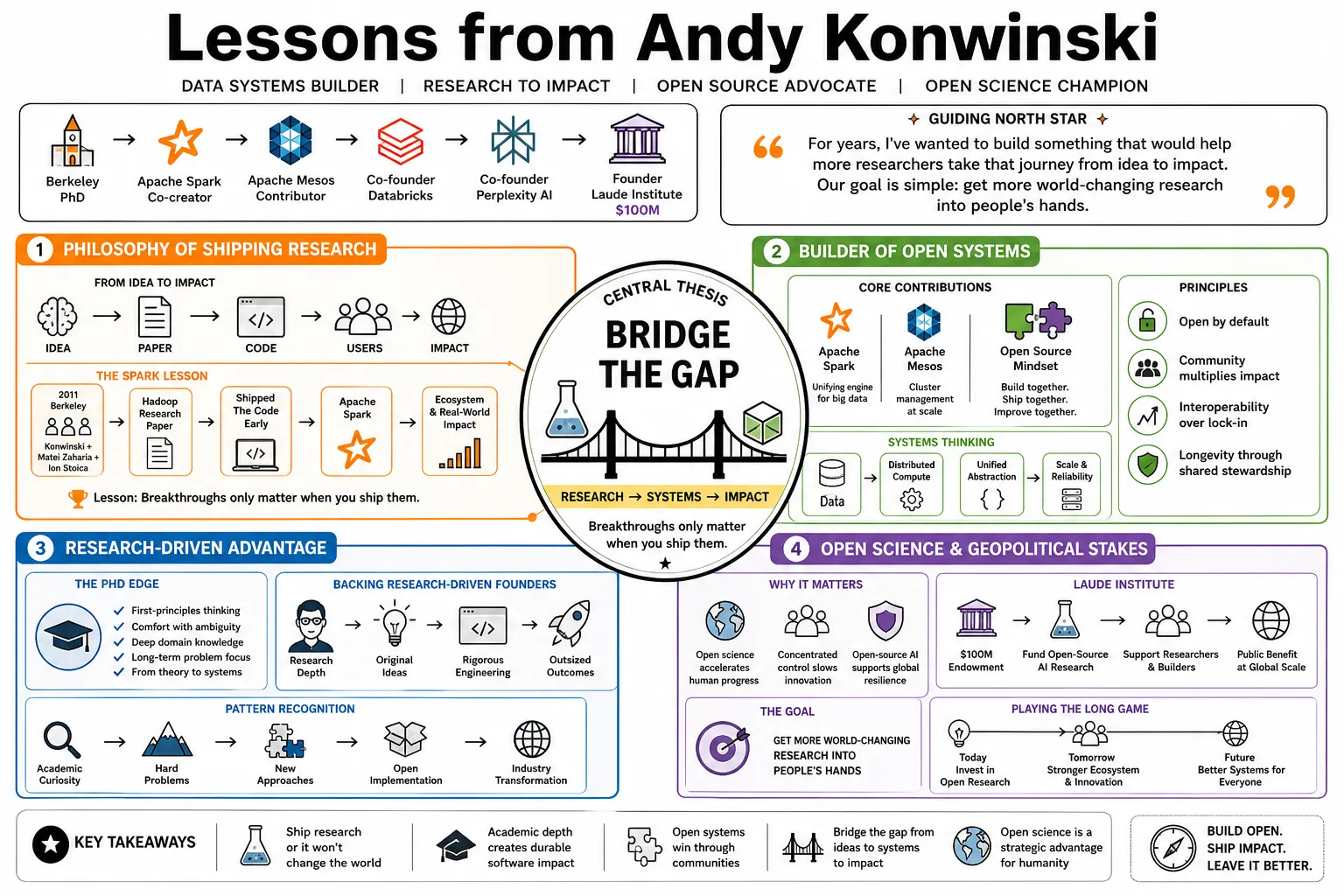
Andy Konwinski is a co-founder of Databricks and Perplexity AI, and a key contributor to the Apache Spark and Mesos projects. He is known for building systems that bridge the gap between academic research and commercial software, most recently launching the $100 million Laude Institute to fund open-source AI development. This profile collects his insights on data engineering, product strategy, and the geopolitical stakes of open science.
Part 1: The Philosophy of Shipping Research
- On Bridging the Gap: "For years, I've wanted to build something that would help more researchers take that journey from idea to impact. Our goal is simple: get more world-changing research into people's hands." — Source: [Laude Institute]
- On the Lesson of Spark: "When Matei Zaharia and I published about Hadoop with Ion Stoica in our first year at Berkeley, we shipped the code too. That line of research led Matei to build Apache Spark... The lesson stuck with me: Breakthroughs only matter when you ship them." — Source: [TechMeme]
- On the PhD Advantage: Konwinski believes the most significant software outcomes stem from academic depth rather than just hacker culture, prompting his focus on backing "research-driven" founders. — Source: [Stanford HAI]
- On Startup Best Practices: Researchers need more than just compute power; they need startup fundamentals like marketing, finding product-market fit, and press relations to actually commercialize their work. — Source: [HighPerformr]
- On Crossing the Chasm: The hardest challenge for deep tech founders is crossing the gap from paper to product, which demands a focus on usability and real-world deployment over raw technical benchmarks. — Source: [Forbes]
- On the Lab-to-World Pipeline: "We help get ideas out of the lab and into the world by giving the right resources to the right researchers at the right time." — Source: [SiliconAngle]
- On Teaching Commercialization: In his "Research to Startups" seminar at UC Berkeley, he guides graduate students through the mechanics of translating complex computer science into viable companies. — Source: [UC Berkeley]
- On Academic Depth: He advises hiring for technical depth first, maintaining that management and operational skills can be taught later. — Source: [eBoona]
- On Measuring Progress: The distance between an academic idea and a practical implementation should be measured in months, not decades. — Source: [Observer]
Part 2: Open Source and Ecosystems
- On Open Source as Strategy: "Open source is not charity. It's a superior way to build infrastructure software because it creates ecosystems, not just products." — Source: [eBoona]
- On Innovation Speed: Open source isn't merely about free software—it's about building a community that can innovate and iterate faster than any single proprietary company. — Source: [Medium]
- On Giving Back: "By giving back to the open source community and more broadly the world and academia... that's how we maintain that driving force not just on the morale and moral and philosophical side within our culture but actually also and materially to our business proposition." — Source: [BigEye]
- On Developer Momentum: "The open source momentum and contributions outweigh and not only get the attention from the marketing side of the world but also actually the technologists and the adoption side." — Source: [eBoona]
- On Open Standards: The data layer of enterprise technology must remain open, built on open formats, protocols, and source engines to prevent vendor lock-in. — Source: [Observer]
- On Community Contributions: The direct contributions received from the early Spark community were invaluable in making the software robust enough for enterprise deployment. — Source: [GitHub]
- On Defending Open Research: We cannot afford a laissez-faire attitude toward open science, nor can we default to government overregulation; we need focused, stakeholder-driven efforts to keep the ecosystem open. — Source: [Stanford HAI]
- On the Fountain of Innovation: The fundamental research that powers major proprietary tech companies originally flows from the fountain of open academic research. — Source: [Stanford HAI]
- On Eating Our Corn Seed: Neglecting to fund open-source infrastructure is akin to eating our corn seed, starving the next generation of technological breakthroughs. — Source: [Newcomer]
Part 3: Cluster Scheduling and Systems Engineering
- On Resource Sharing: "Mesos is a general-purpose cluster resource manager that allows fine-grained sharing of resources across different applications according to an organizational policy." — Source: [Learning Spark]
- On the Narrow Waist Architecture: A unified workload model acts as a narrow waist that enables developers to write code in one language for streaming, machine learning, and graph processing. — Source: [Stanford HAI]
- On Distributed Complexity: "Its inner workings are complex, resting as they do on a mixture of distributed systems theory, practical engineering, and common sense." — Source: [Hadoop Definitive Guide]
- On Raising Abstractions: Stripped to its core, the underlying theme of big data infrastructure is about continually raising the level of abstraction for the user. — Source: [Learning Spark]
- On Shared-State Scheduling: Konwinski's work on Google's Omega scheduler demonstrated that allowing multiple parallel schedulers to see the entire cluster state dramatically improves throughput. — Source: [Washington.edu]
- On Dominant Resource Fairness: He co-developed the DRF algorithm to establish a standard mathematical approach for allocating varying resource types like CPU and memory fairly across users. — Source: [AndyKonwinski.com]
- On Lock-Free Concurrency: Moving to an optimistic, lock-free concurrency control model for cluster state allows infrastructure to schedule vast numbers of tasks per second. — Source: [UHNWIData]
- On Well-Rounded Engineers: "Big Data is a rather large field and to be successful in it, you need to be pretty well rounded. This means not allowing yourself to be so narrowly focused that you're a burden on your teammates around you." — Source: [Google Scholar]
- On System Isolation: True cluster efficiency relies on the ability to isolate heterogeneous workloads so they can run simultaneously without degrading each other's performance. — Source: [UC Berkeley]
Part 4: The Big Data Paradigm
- On the Unified Stack: "Use one programming paradigm instead of mixing and matching tools like Hive, Hadoop, Mahout, and Storm." — Source: [Learning Spark]
- On the Core Challenge: "Data in all domains is getting bigger. How can you work with it efficiently?" — Source: [Learning Spark]
- On Speed and Memory: "Speed is important in processing large datasets, as it means the difference between exploring data interactively and waiting minutes or hours." — Source: [Learning Spark]
- On Resilient Distributed Datasets: RDDs provided a critical abstraction, allowing in-memory computations that are both fault-tolerant and highly parallelizable. — Source: [Learning Spark]
- On Developer Productivity: "Spark’s selling point is that it combines ETL, batch analytics, real-time stream analysis, machine learning, graph processing, and visualizations... It lets you tackle the complexities that come with raw unstructured data sets." — Source: [Learning Spark]
- On Replacing MapReduce: Spark succeeded because it recognized that writing intermediate steps to disk, as Hadoop MapReduce did, was an unnecessary bottleneck for interactive queries. — Source: [GitHub]
- On High-Level APIs: Providing APIs in Python, Java, and Scala meant complex parallel jobs could finally be expressed in just a few lines of code. — Source: [Funai.edu]
- On Interactivity: The ability to keep data in RAM between processing steps fundamentally changed data science by enabling interactive, real-time querying. — Source: [Learning Spark]
- On Cluster Integration: To be widely adopted, an engine like Spark had to interact seamlessly with existing cluster managers like YARN and Mesos. — Source: [I-Programmer]
- On Managing Complexity: The goal of modern data architecture is to provide a single engine that hides the underlying complexity of cluster management from the data scientist. — Source: [Learning Spark]
Part 5: Building Databricks and Community
- On the Early Databricks Mission: The company was founded on a clear mission to make big data simple, building a unified platform where engineers and analysts could collaborate. — Source: [eBoona]
- On the Product Management Role: In the early days of Databricks, Konwinski operated as the bridge between deep technical infrastructure and enterprise user needs. — Source: [Databricks Blog]
- On Creating the Spark Summit: "Earlier this month we held the first Spark Summit, a conference to bring the Apache Spark community together." — Source: [Dtyped]
- On Professional Services: He built the Databricks professional services and training organizations from scratch to ensure early adopters succeeded in deploying the software. — Source: [Medium]
- On Evolving the Brand: Konwinski helped guide the company's messaging as it transitioned from a Spark-centric tool into a comprehensive Data and AI platform. — Source: [Databricks Blog]
- On Marketing to Technologists: Real marketing for developer tools relies on technical substance; engineers adopt products based on open-source utility, not traditional enterprise sales tactics. — Source: [BigEye]
- On Developer Education: "Databricks is proud to make all talk videos, slides, training talk videos, and training materials available online for free as a service to the Apache Spark community." — Source: [GitHub]
- On Community-Led Growth: Establishing a community-first marketing model meant that user education and open-source adoption naturally fed into enterprise sales. — Source: [Medium]
- On Collaborative Platforms: The true value of a data platform is realized when it breaks down the silos between different data personas within a company. — Source: [eBoona]
Part 6: MLOps and the ML Lifecycle
- On the Core ML Challenge: "Building production machine learning applications is challenging because there is no standard way to record experiments, ensure reproducible runs, and manage and deploy models." — Source: [Medium]
- On the Scientist-Engineer Divide: A primary bottleneck in shipping models is the cultural and tooling divide between the scientist who trains the model and the engineer who must deploy it. — Source: [Medium]
- On the Goal of MLflow: The platform was designed with an open interface design to let practitioners bring their own training code while enforcing a structured development process. — Source: [GitHub]
- On Data Management: The foundation of the machine learning lifecycle is robust data management, without which models cannot be accurately trained or tuned. — Source: [WhiteRose]
- On Model Learning: The experimental phase requires rigorous tracking systems to compare runs and reproduce successful parameter configurations. — Source: [IEEE]
- On Model Verification: Before deployment, organizations must have systematic ways to verify that a model meets both performance and business requirements. — Source: [WhiteRose]
- On Model Deployment: Integrating a model into an operational system requires abstracting away the tedious cluster management that historically plagued ML efforts. — Source: [GitHub]
- On New Software Lifecycles: Machine learning development introduces new challenges that simply do not exist in traditional software development lifecycles. — Source: [KDnuggets]
- On Automating the Lifecycle: "Automating this task will let human software engineers spend lots more time designing new features, reforming abstractions, interfacing with users." — Source: [Kaggle]
- On Human Creativity: By removing the friction of deployment, engineers can return to tasks that are inherently human and more intellectually rewarding. — Source: [Kaggle]
Part 7: Perplexity AI and the Answer Engine
- On the Answer Engine Vision: Perplexity was built to move beyond traditional search by functioning as an answer engine that prioritizes direct information over a list of links. — Source: [Entrepreneur Loop]
- On Killing the Blue Links: The founding team recognized that the ten blue links model was an outdated way to satisfy human curiosity. — Source: [ProductMarketFit]
- On the Importance of Citations: Synthesizing answers with inline citations is crucial for ensuring transparency and minimizing the risk of LLM hallucinations. — Source: [Entrepreneur Loop]
- On Scaling Infrastructure: Konwinski's background in Apache Spark allowed Perplexity to architect backend systems capable of processing real-time web data efficiently. — Source: [ProductMarketFit]
- On Conversational Interfaces: Combining traditional search pipelines with large language models enables a conversational experience that answers follow-up questions intuitively. — Source: [Entrepreneur Loop]
- On Trust as a Moat: Moving away from an advertising-centric model to a subscription-first approach was an intentional choice to preserve user trust. — Source: [Wikipedia]
- On the Wikipedia-ChatGPT Synthesis: He views the product as a marriage of Wikipedia's factual density and ChatGPT's conversational utility. — Source: [ProductMarketFit]
- On Serving Curiosity: The ultimate mission of the platform is serving the world's curiosity with verified, educated answers. — Source: [Contrary]
- On Transparent Search: The current era of search functions as a black box; the future requires platforms that show exactly where their information originates. — Source: [Entrepreneur Loop]
- On Disrupting Incumbents: Building a better search experience requires rethinking the entire stack, from data ingestion to the user interface. — Source: [ProductMarketFit]
Part 8: Geopolitics, Philanthropy, and the Future of AI
- On the Geopolitical Stakes: "I think democracy's fucked if we do this [lose the AI race to China due to disinvestment in academic research]." — Source: [Newcomer Podcast]
- On the Open Source Battlefield: The U.S. is losing its edge as major labs retreat from open source, while foreign competitors lean heavily into releasing open-weight models. — Source: [Stanford HAI]
- On Shifting Scaling Laws: As the focus of AI development shifts toward post-training efficiency, the structural disadvantage of open-source models compared to proprietary ones is diminishing. — Source: [Stanford HAI]
- On Brain Drain: Top technical talent is increasingly choosing to stay outside the U.S. because public sector funding for basic research is being dismantled. — Source: [Newcomer Podcast]
- On Choosing Philanthropy: "I could do another company, but I'm honestly more interested in helping find other Databricks." — Source: [SiliconAngle]
- On Engineered Intelligence: "Engineered intelligence is no longer theoretical. Whether AI moves society forward or divides it depends on who is doing the building, and why." — Source: [AI News]
- On Personal Motivation: "I have a three-year-old and a five-year-old, and I think their futures are hanging in the balance. So I’m excited to see AI cure cancer. I’m excited to see AI reshape democracy." — Source: [ProductMarketFit]
- On Embracing Failure: In his commencement advice to students, he urged them to run at failure to discover true technical boundaries. — Source: [GitHub]
- On Legacy: "Stop worrying about your success and think at the species level. Be part of something much bigger than yourself." — Source: [GitHub]