Lessons from Armon Dadgar
Armon Dadgar is the co-founder and CTO of HashiCorp, where he built tools like Terraform, Vault, and Consul to automate how modern applications are provisioned and secured. The lessons below cover his practical approach to distributed systems, infrastructure as code, identity security, and open-source business models.
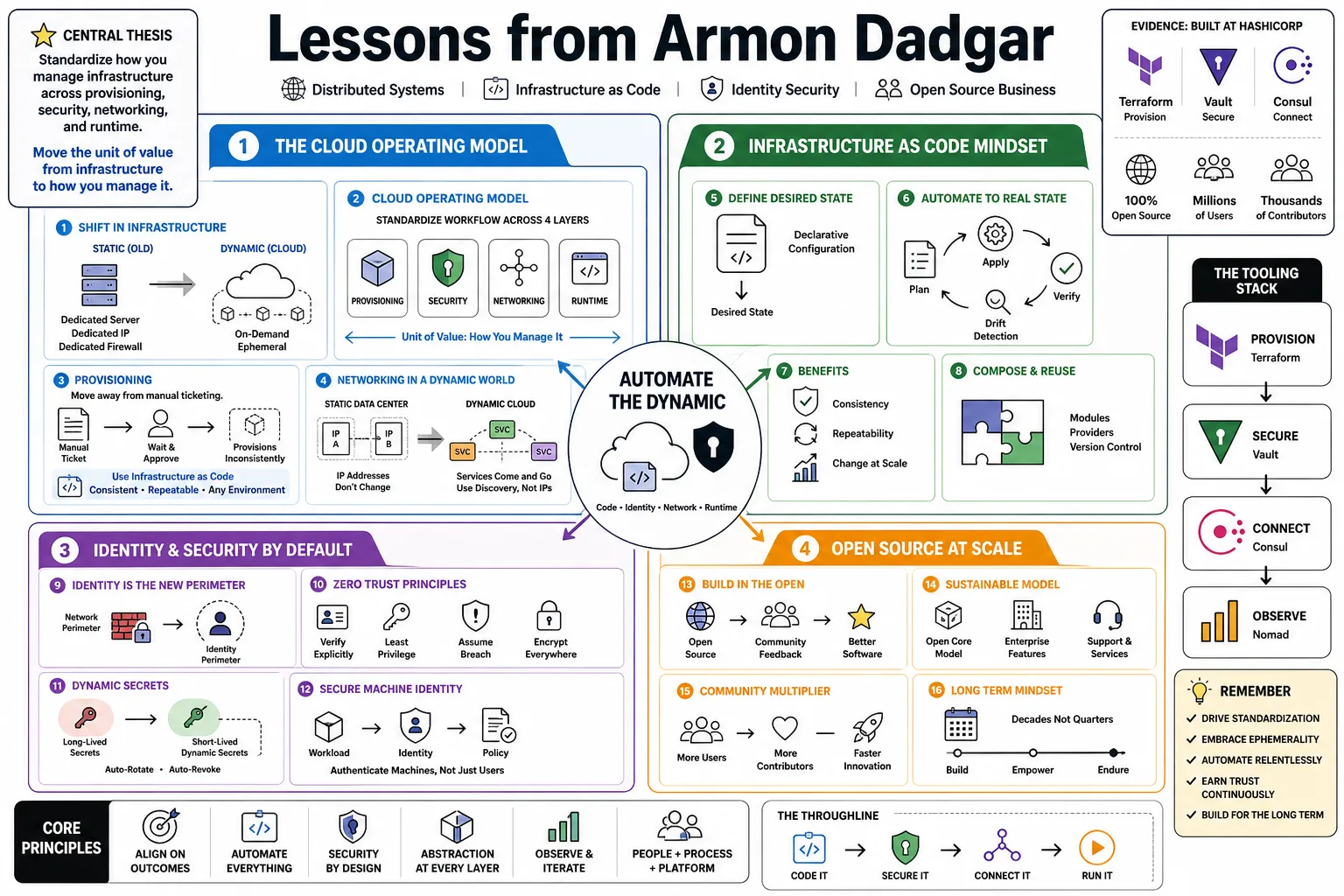
Part 1: The Cloud Operating Model
- On the shift in infrastructure: "The transition to cloud is a shift from static infrastructure—where you have a dedicated server, a dedicated IP, and a dedicated firewall rule—to dynamic infrastructure, where everything is on-demand and ephemeral." — Source: [HashiCorp Whiteboards]
- On defining the cloud operating model: "The cloud operating model is fundamentally about standardizing the workflow across four layers: provisioning, security, networking, and runtime. It moves the unit of value from the infrastructure itself to how you manage it." — Source: [HashiCorp Blog]
- On provisioning: "You have to move away from manual ticketing systems. Provisioning in the cloud requires Infrastructure as Code to guarantee a consistent, repeatable workflow across any environment." — Source: [The New Stack]
- On networking in a dynamic world: "In a static data center, IP addresses were the foundation of trust. In the cloud, IPs change constantly. Networking has to shift from IP-based routing to service-based discovery." — Source: [InfoQ]
- On multi-cloud reality: "Companies don't choose multi-cloud purely for leverage against a vendor; they inherit it through M&A, regulatory requirements, or developers choosing differentiated services from different providers." — Source: [The Logan Bartlett Show]
- On hybrid persistence: "On-premises data centers aren't disappearing overnight. The goal isn't to force everything into the public cloud, but to bring the cloud operating model—automation and self-service—into private environments." — Source: [Software Engineering Daily]
- On the role of the workflow: "The reality is that very rarely do we see companies standardize on specific technologies top-down; it usually ends up being a hodge-podge. You have to standardize on workflows, not technologies." — Source: [HashiCorp Tao]
- On cloud adoption friction: "Cloud 1.0 was tactical. Individual app teams ran wild in the cloud, leading to shadow IT, inconsistent security, and uncontrolled costs. That fragmentation forces a strategic reset." — Source: [EnterpriseReady Podcast]
- On runtime evolution: "Moving from static application deployments to dynamic scheduling means abstracting the underlying servers. Developers shouldn't care about the VM; they should only care about the application artifact." — Source: [Mayfield]
- On intention versus execution: "Many companies declare they are 'moving to the cloud' without changing their operational practices. If you bring ticket-based, manual operations into AWS, you aren't doing cloud computing; you're just renting an expensive data center." — Source: [The Cloudcast]
Part 2: Distributed Systems and Complexity
- On the complexity tax: "There is no free lunch with microservices. You gain developer velocity and organizational independence, but you pay for it with massive operational and distributed systems complexity." — Source: [Papers We Love]
- On gossip protocols: "Traditional centralized registries fail at scale. Using scalable, weakly-consistent infection-style protocols like SWIM allows thousands of nodes to maintain cluster state without a single bottleneck." — Source: [InfoQ]
- On consistency vs. availability: "For critical state, like identity or security policies, you cannot compromise on consistency. This is why tools like Vault and Consul rely on Raft consensus protocols to ensure the data is right, even if it means sacrificing partition tolerance." — Source: [Software Engineering Daily]
- On academic versus industrial design: "Academia provides great ideas and algorithms, but the constraints of industry dictate that some are better to implement than others. We prioritize systems that operators can actually understand." — Source: [HashiCorp Blog]
- On distributed failures: "In a distributed environment, you have to assume failure is constant. A node going down is not an exception to handle; it is the default state of the system." — Source: [The New Stack]
- On simplicity: "Complexity is the enemy of security and reliability. The role of a great architect is to distill simplicity from an inherently complex environment." — Source: [Sylabs]
- On managing state: "Stateless applications are easy to scale, but eventually, someone has to hold the state. The hardest problems in distributed computing always boil down to who owns the state and how it gets replicated." — Source: [Software Engineering Daily]
- On composability: "Monolithic platforms break under the weight of their own assumptions. Building composable, modular systems allows organizations to swap out components as their scale or needs change." — Source: [Mayfield]
- On automation: "When you operate hundreds or thousands of nodes, human intervention is mathematically impossible. The system must self-heal, self-discover, and self-regulate." — Source: [HashiCorp YouTube]
- On evaluating algorithms: "We don't choose the most theoretically perfect algorithm. We choose the one that is robust enough to handle edge cases and simple enough for a tired operator to debug at 3 AM." — Source: [Software Engineering Daily]
Part 3: Zero Trust and Identity-Based Security
- On the perimeter: "The traditional castle-and-moat security model is dead. In a modern architecture, identity is the new perimeter." — Source: [HashiCorp Blog]
- On zero trust: "Zero trust assumes the network is already compromised. Every request—whether from a human or a machine—must be explicitly authenticated and authorized." — Source: [The Logan Bartlett Show]
- On machine identity: "We spend so much time authenticating humans via Okta or Azure AD, but machines make up 99% of the traffic in a data center. Machines need a first-class identity framework." — Source: [HashiCorp YouTube]
- On dynamic secrets: "Static, long-lived credentials are high-value targets for attackers. The solution is generating ephemeral, just-in-time credentials that expire automatically, severely limiting the blast radius of a leak." — Source: [The New Stack]
- On encryption as a service: "Developers shouldn't have to become cryptographers. Security tools must provide centralized key management and encryption as an API service so developers can secure data easily." — Source: [India Times]
- On access policy: "Authorization should not be tied to network segments. Access must be governed by policies tied to explicit identities, dictating exactly what a specific application is allowed to do." — Source: [HashiCorp Blog]
- On high-trust vs low-trust: "Moving to the cloud means moving from a high-trust internal network to a low-trust or zero-trust shared environment. The architecture must reflect that lack of inherent trust." — Source: [Software Engineering Daily]
- On credential lifecycles: "A secret without an expiration date is a time bomb. Every credential issued in a modern infrastructure should have a strict, enforceable time-to-live." — Source: [HashiCorp YouTube]
- On operator access: "Human-to-machine access shouldn't require exposing the internal network via VPNs. It should be identity-based remote access that grants connection only to specific authorized services." — Source: [InfoQ]
- On the identity broker: "To manage zero trust effectively, you need an identity broker—a central authority that can integrate with various platforms, verify identity, and issue a token that is respected across the entire infrastructure." — Source: [HashiCorp Blog]
Part 4: Open Source Strategy and Commercialization
- On open-source sustainability: "It’s very hard to become a large, sustainable open-source project if you have negative cash flow forever. To solve large-scale problems, you eventually require a business model to fund the engineering." — Source: [a16z Podcast]
- On the open core framework: "We use a strict delineation framework: if a feature enables an individual technical practitioner to solve their core workflow problem, it is open source. If it solves an organizational problem, it is commercial." — Source: [Open Source Underdogs]
- On user experience: "The open-source tool should never feel 'crippled' for the end-user. You have to win the practitioner by giving them a complete, powerful tool." — Source: [LaunchNotes]
- On selling through the back door: "By building a dedicated community through open source, you sell through the back door. The technology becomes part of the daily workflow, making it difficult to remove when it comes time for the enterprise to buy." — Source: [LaunchDarkly]
- On ecosystem as a moat: "Commercial success follows ecosystem standardization. If everyone uses your open-source standard, your enterprise version becomes the natural choice for governance." — Source: [WorkOS Podcast]
- On customer relationships: "In the cloud era, you need an unmediated, direct relationship with your users. The traditional vendor 'channel' model creates too much distance between the creators of the software and the people deploying it." — Source: [Open Source Underdogs]
- On organizational challenges: "Features like multi-datacenter replication, compliance governance, and role-based access control are problems for a VP of Engineering, not an individual developer. That is what you monetize." — Source: [a16z Podcast]
- On transitioning upmarket: "Moving from startup mode to enterprise mode means transitioning from doing non-scalable things to survive, to building repeatable, predictable systems for a billion-dollar revenue company." — Source: [WorkOS Podcast]
- On the monetization flywheel: "Our strategy is a three-part flywheel: win the practitioner with open source, standardize the broader ecosystem around those workflows, and then monetize the enterprise requirements." — Source: [Open Source Underdogs]
Part 5: Infrastructure as Code and Workflow
- On immutable infrastructure: "Instead of patching and maintaining long-lived servers, infrastructure should be immutable. When an update is needed, you replace the server entirely, leading to more predictable and reproducible systems." — Source: [HashiCorp Tao]
- On infrastructure versioning: "Infrastructure as Code allows you to treat your data center the same way you treat your application code: versioned, auditable, and subject to continuous integration." — Source: [The New Stack]
- On the plugin architecture: "To maintain a high-quality user experience while allowing for massive scale, you need a core engine and a plugin system. This allows the community to extend the tool to new providers without bloating the primary codebase." — Source: [Software Engineering Daily]
- On standardizing provisioning: "Every cloud provider has its own API and logic. Infrastructure as Code provides an abstraction layer so operators can use a single language and workflow to provision resources anywhere." — Source: [HashiCorp Blog]
- On automation confidence: "Code provides predictability. When infrastructure is defined in code, operators can confidently predict what changes will happen before they apply them, reducing the fear of deployment." — Source: [InfoQ]
- On decoupling systems: "Tools should be composable. We don't force a monolithic approach; you can use our provisioning tool without our security tool, allowing teams to adopt automation at their own pace." — Source: [Mayfield]
- On workflow vs technology: "Technologies will always change. If you couple your operations to a specific cloud technology, you'll have to rewrite everything in five years. If you couple to a workflow, the process remains consistent." — Source: [HashiCorp Tao]
- On the death of the runbook: "Manual runbooks are inherently flawed because they drift from reality. Executable code is the only reliable documentation of how your infrastructure actually works." — Source: [The Cloudcast]
- On practitioner empowerment: "Infrastructure as code shifts power to the practitioner. It allows developers to define what they need to run their application without waiting weeks for an IT operations team to rack a server." — Source: [The New Stack]
Part 6: Platform Engineering and Cloud 2.0
- On Cloud 2.0: "We are in the 'multi-everything' era. Applications are no longer monolithic; they are decomposed into microservices running across a mix of containers, serverless, and VMs on multiple clouds." — Source: [SiliconANGLE]
- On the internal platform: "Platform engineering is treating infrastructure as an internal product. The goal is to provide a 'chassis' of core primitives—provisioning, security, networking—that application teams can simply consume." — Source: [HashiCorp Blog]
- On the golden path: "Platform teams must establish a golden path. It’s about creating reusable patterns and guardrails so developers don't have to reinvent the wheel every time they deploy an app." — Source: [The Logan Bartlett Show]
- On business speed: "Platform engineering isn't just an IT efficiency exercise; it’s about business velocity. Removing the friction between app devs and ops can reduce deployment times from months to days." — Source: [EnterpriseReady Podcast]
- On self-service infrastructure: "The ultimate maturity phase is self-service. You want to provide a simplified interface where developers can deploy applications without needing to understand the underlying complexity." — Source: [The New Stack]
- On the graveyard of platforms: "There is a massive graveyard of internal platform companies that tried to build a monolithic 'PaaS' and failed. The successful ones build modular, composable platforms." — Source: [The Logan Bartlett Show]
- On autonomous DevOps: "AI can write context-free code, like generating an S3 bucket script. But the future of autonomous DevOps requires giving AI the context of your specific environment—your VPCs, policies, and naming conventions." — Source: [AI Native Dev Podcast]
- On reducing cognitive load: "Developers should spend their time writing business logic, not figuring out how to configure a load balancer. A good platform team abstracts that cognitive load away." — Source: [InfoQ]
- On standardizing chaos: "As organizations scale, individual teams adopting different tools creates unmanageable chaos. Platform engineering is the organizational response to standardize that fragmentation." — Source: [HashiCorp YouTube]
Part 7: Product Design and The Tao of HashiCorp
- On life support lines: "When we started, we looked for 'life support lines'—critical workflows that were broken or entirely manual. We only built a tool if a sufficient one didn't already exist to fix that workflow." — Source: [Strategy of Security]
- On pragmatism over dogma: "If a theoretical perfect solution is too complex for a user to actually implement, we reject it in favor of a pragmatic one that solves the immediate problem." — Source: [HashiCorp Tao]
- On asynchronous design: "Product design should be written-first. Using design docs and RFCs allows us to debate technical trade-offs rigorously before a single line of code is written." — Source: [Software Engineering Daily]
- On the Tao of HashiCorp: "The Tao is our foundational design ethos. It dictates that tools must be workflow-centric, modular, and focused on immutability." — Source: [HashiCorp Blog]
- On solving one problem well: "A tool should do one thing exceptionally well. When a tool tries to be a platform that does everything, it usually ends up doing nothing particularly well." — Source: [Mayfield]
- On interface design: "The interface you present to the user must be decoupled from the complex reality of the underlying infrastructure. The user should experience simplicity, while the tool manages the chaos." — Source: [Software Engineering Daily]
- On avoiding lock-in: "We build tools that are agnostic by design. They should enable users to interact with any provider, rather than locking them into a specific vendor's ecosystem." — Source: [The New Stack]
- On backward compatibility: "In infrastructure, you cannot break things. We prioritize backward compatibility heavily because practitioners rely on these tools as the foundation of their businesses." — Source: [InfoQ]
- On the Unix philosophy: "Our design philosophy is heavily inspired by the Unix approach: build small, distinct programs that communicate clearly and can be chained together to solve complex problems." — Source: [HashiCorp Tao]
Part 8: Entrepreneurship and Scaling HashiCorp
- On the origin: "We met trying to build a system to deploy code across multiple cloud providers for a university project. It was a spectacular failure, but the problems we identified became the roadmap for HashiCorp." — Source: [Mayfield]
- On doing the drudgework: "You have to be willing to do the unglamorous work. I sent an email looking for someone to do the drudgework of our research project, and Mitchell was the only one who thought it looked fun." — Source: [HashiCorp YouTube]
- On the practitioner focus: "We started the company with a practitioner-first strategy. We knew that if we built open-source tools that solved real technical gaps for the developer, adoption would follow." — Source: [EnterpriseReady Podcast]
- On knowing your limits: "We recognized early on that we were technologists first. We made the strategic decision to hire professional leadership to help transition us from an open-source project into a true enterprise business." — Source: [The Logan Bartlett Show]
- On logical buyers: "Instead of building disparate tools for different markets, we focused on building a 'Microsoft Office' suite for a single logical buyer: the DevOps or Platform Engineering persona." — Source: [Open Source Underdogs]
- On the early days: "We started the company at an Ikea desk in an apartment. The first few years were just about releasing a massive suite of foundational tools with a tiny team to see what would stick." — Source: [HashiCorp YouTube]
- On hyper-growth: "Scaling a business means constantly tearing down and rebuilding your internal processes. What works for a team of ten breaks at fifty, and breaks again at five hundred." — Source: [WorkOS Podcast]
- On building trust: "Trust compounds over time. By consistently providing reliable, open-source infrastructure tools, we built a level of trust with developers that translated into long-term commercial relationships." — Source: [LaunchDarkly]
- On long-term vision: "Infrastructure moves slowly. You cannot build an infrastructure company expecting a quick flip; you have to commit to a decade-long vision of how data centers will evolve." — Source: [a16z Podcast]