Lessons from Ashish Vaswani
Ashish Vaswani was the lead author of the 2017 paper "Attention Is All You Need," which introduced the Transformer architecture and laid the groundwork for modern language models. After his time at Google Brain, he co-founded Adept AI and Essential AI to focus on enterprise AI and human-computer collaboration. This collection gathers his public statements on deep learning, model architecture, and the realities of building commercial artificial intelligence.
Part 1: The Origins of the Transformer
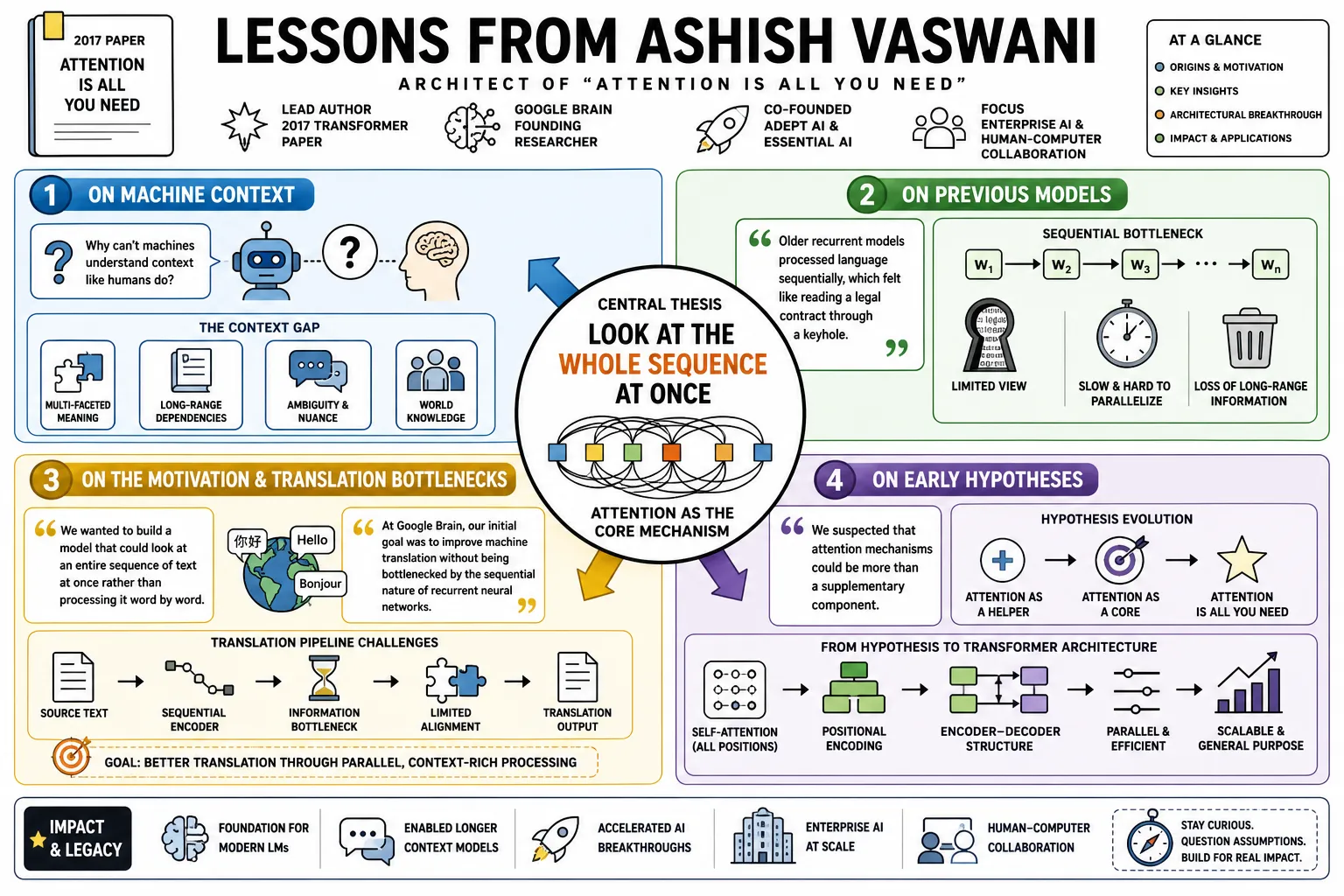
- On Machine Context: "Why can't machines understand context like humans do?" — Source: [AI With Ayushman]
- On Previous Models: "Older recurrent models processed language sequentially, which felt like reading a legal contract through a keyhole." — Source: [AI With Ayushman]
- On the Motivation: "We wanted to build a model that could look at an entire sequence of text at once rather than processing it word by word." — Source: [Wired]
- On Translation Bottlenecks: "At Google Brain, our initial goal was to improve machine translation without being bottlenecked by the sequential nature of recurrent neural networks." — Source: [Wired]
- On Early Hypotheses: "We suspected that attention mechanisms could be more than a supplementary tool for recurrent models; they could be the entire foundation." — Source: [Attention Is All You Need]
- On Collaboration: "The paper was a product of eight people working closely together, often writing code and debating architecture decisions in the same room." — Source: [Wired]
- On the Name: "The title of the paper came from the realization that we could drop convolutions and recurrence entirely." — Source: [Wired]
- On Initial Training Runs: "Our early models demonstrated that relying entirely on self-attention allowed for significantly more parallelization during training." — Source: [Attention Is All You Need]
- On Algorithmic Simplicity: "We were searching for a simpler network architecture that could still handle complex sequence transduction tasks." — Source: [Attention Is All You Need]
- On Breaking Paradigms: "Moving away from RNNs meant we had to rethink how a model understands the order of words, which led to the development of positional encoding." — Source: [Stanford CS25]
Part 2: Breaking the Recurrence Bottleneck
- On Sequential Processing: "The inherent sequential nature of RNNs precludes parallelization within training examples, which becomes a severe constraint at longer sequence lengths." — Source: [Attention Is All You Need]
- On Computational Efficiency: "Self-attention layers connect all positions with a constant number of sequentially executed operations, whereas recurrent layers require operations proportional to sequence length." — Source: [Attention Is All You Need]
- On Path Lengths: "One key advantage of self-attention is the shortened path length that signals must traverse to learn long-range dependencies." — Source: [Attention Is All You Need]
- On Matrix Multiplications: "By framing the problem around attention, we could utilize highly optimized matrix multiplication routines that modern hardware excels at." — Source: [Stanford CS25]
- On Hardware Utilization: "The Transformer was designed specifically to maximize the throughput of existing accelerators like TPUs and GPUs." — Source: [Stanford CS25]
- On Long-Range Dependencies: "Shorter paths between any combination of positions in the input and output sequences make it easier for the model to learn relationships across large gaps." — Source: [Attention Is All You Need]
- On Training Speed: "Removing the recurrence bottleneck allowed us to train translation models to state-of-the-art performance in a fraction of the time." — Source: [Attention Is All You Need]
- On Self-Attention Utility: "Self-attention is powerful because it allows each position in the sequence to compute its representation by looking at every other position simultaneously." — Source: [Stanford CS25]
- On Future Hardware: "The architecture choices we made were heavily influenced by how we expected compute hardware to scale in the coming years." — Source: [Stanford CS25]
Part 3: The Philosophy of Attention
- On Information Retrieval: "An attention function can be described as mapping a query and a set of key-value pairs to an output." — Source: [Attention Is All You Need]
- On Multi-Head Attention: "Instead of performing a single attention function, we found it beneficial to linearly project the queries, keys, and values multiple times to allow the model to jointly attend to information from different representation subspaces." — Source: [Attention Is All You Need]
- On Subspace Representations: "With single-head attention, averaging inhibits the ability to focus on different specific aspects of the input. Multi-head attention solves this." — Source: [Attention Is All You Need]
- On Scaled Dot-Product Attention: "We scale the dot products by the square root of the dimension to prevent the softmax function from being pushed into regions where it has extremely small gradients." — Source: [Attention Is All You Need]
- On Interpretability: "Attention distributions allow us to inspect what the model is focusing on, which provides a degree of transparency into its decision-making process." — Source: [Attention Is All You Need]
- On Syntactic Structure: "When we visualize the attention heads, we can observe them learning to track syntactic and semantic structure in sentences." — Source: [Attention Is All You Need]
- On Global Receptive Fields: "Self-attention gives every token a global receptive field from the very first layer of the network." — Source: [Stanford CS25]
- On Masking: "In the decoder, we modify the self-attention sub-layer to prevent positions from attending to subsequent positions, ensuring predictions depend only on the known past." — Source: [Attention Is All You Need]
- On Feed-Forward Networks: "The position-wise feed-forward networks applied after the attention layers are necessary to introduce non-linearity and expand the representation capacity." — Source: [Attention Is All You Need]
- On Generalization: "The attention mechanism is surprisingly general and can be applied beyond text, treating audio or image patches as sequences." — Source: [Stanford CS25]
Part 4: The Path to Adept AI and Human-Machine Collaboration
- On Building Tools: "The goal should be to build tools that deepen the partnership between humans and computers." — Source: [Economic Times]
- On Action Models: "Language models are good at reading and writing, but the next step is models that can take actions on a computer." — Source: [Wired]
- On Software Interfaces: "We spend so much time navigating complex software interfaces. AI can serve as a translation layer between human intent and software execution." — Source: [Wired]
- On Enterprise Use Cases: "The most immediate value for AI is in enterprise settings where it can automate tedious workflows and free up human time." — Source: [Bloomberg]
- On User Intent: "An action-oriented model must accurately map ambiguous user intent to precise API calls and UI interactions." — Source: [Bloomberg]
- On Knowledge Work: "We want to give every knowledge worker an AI teammate that understands their specific tools and context." — Source: [Wired]
- On Multimodality: "To truly collaborate with humans, a model needs to understand both text and the visual state of the screen." — Source: [Wired]
- On the Limits of Chatbots: "Conversational agents are just the beginning; the real shift happens when the agent can reliably do the work for you." — Source: [Bloomberg]
- On Practical Applications: "Research is most rewarding when you see it deployed to solve concrete problems in people's daily workflows." — Source: [Bloomberg]
Part 5: Rethinking Scaling and the Compute Paradigm
- On Premature Scaling: "We must be careful not to prematurely scale architectures before we fully understand their fundamental limitations." — Source: [Bloomberg]
- On Compute Dependence: "The industry has become heavily reliant on scaling compute, but scientific breakthroughs often require looking beyond sheer scale." — Source: [Bloomberg]
- On Efficiency: "There is immense value in finding architectural changes that provide the same capabilities at a fraction of the compute cost." — Source: [Stanford CS25]
- On Data Quality: "Scaling model size only works well if the quality of the data scales with it." — Source: [India Science Festival]
- On Architectural Complacency: "The success of the Transformer has, in some ways, made the field less inclined to experiment with radically different architectures." — Source: [Stanford CS25]
- On Post-Training: "We are finding that how you train the model after pre-training—through alignment and reinforcement learning—is just as important as the pre-training itself." — Source: [Bloomberg]
- On Hardware Constraints: "We have to design algorithms that are sympathetic to the realities of memory bandwidth and inter-chip communication." — Source: [Stanford CS25]
- On Diminishing Returns: "As models grow larger, we face diminishing returns on performance relative to the energy and capital expended." — Source: [Bloomberg]
- On Innovation Cycles: "The AI field moves through cycles of scaling up known methods, followed by the discovery of new methods when scaling hits a wall." — Source: [India Science Festival]
- On Evaluation: "Our benchmarks are saturating quickly, which makes it harder to measure true progress in reasoning capabilities." — Source: [India Science Festival]
Part 6: Building Essential AI and Open Models
- On Open Collaboration: "Open models are essential to prevent widening inequality in the AI domain." — Source: [Economic Times]
- On Defining Reasoning: "At Essential AI, our focus is on research that redefines reasoning in model development." — Source: [Ashish Vaswani on Essential AI with AMD]
- On Enterprise Integration: "The goal is to build AI systems that integrate cleanly into enterprise data ecosystems without requiring massive infrastructure overhauls." — Source: [Bloomberg]
- On Data Security: "Businesses want the benefits of large models but are rightfully concerned about data privacy and ownership." — Source: [Bloomberg]
- On Purpose-Built Models: "Instead of one massive model that does everything passably, there is a strong case for smaller, highly tuned models for specific enterprise tasks." — Source: [Bloomberg]
- On Collaborative Ecosystems: "The rapid advancement of AI has historically relied on researchers openly sharing ideas and weights." — Source: [Economic Times]
- On System Architecture: "Deploying AI in production is as much a systems engineering problem as it is a machine learning problem." — Source: [Ashish Vaswani on Essential AI with AMD]
- On Custom Silicon: "Working closely with hardware partners allows us to optimize the entire stack for our specific reasoning workloads." — Source: [Ashish Vaswani on Essential AI with AMD]
- On Accessibility: "We need to make it easier for organizations of all sizes to utilize state-of-the-art models without prohibitive compute costs." — Source: [Economic Times]
Part 7: Advice for Future Researchers
- On Long-term Research: "There are several instances of companies shuttering longer-term R&D efforts to pour resources into money-making aspects, especially at times of distress. This stifles innovation." — Source: [Economic Times]
- On First Principles: "When designing architectures, you have to go back to first principles regarding what information the model actually needs to access." — Source: [Stanford CS25]
- On Asking Questions: "The most important trait for a researcher is the willingness to question underlying assumptions that the rest of the field takes for granted." — Source: [India Science Festival]
- On Simplicity: "If an architecture is too complex to implement and debug easily, it will struggle to gain adoption, regardless of its performance." — Source: [Stanford CS25]
- On Team Dynamics: "Research breakthroughs often happen when you have a small group of highly motivated people who trust each other enough to share half-baked ideas." — Source: [Wired]
- On Choosing Problems: "Focus on problems that are slightly beyond what current hardware can easily solve, so that your solution arrives just as the hardware matures." — Source: [Stanford CS25]
- On Empirical Validation: "Intuition is helpful for generating hypotheses, but extensive empirical validation is what actually moves the field forward." — Source: [Attention Is All You Need]
- On the Hype Cycle: "Ignore the noise of the commercial hype cycle and focus on the technical barriers preventing models from deeper understanding." — Source: [Bloomberg]
- On Perseverance: "Training large models involves many failures. You have to be resilient and methodical in figuring out why a run collapsed." — Source: [Stanford CS25]
Part 8: The Broader Trajectory of AI Development
- On AI Apprentices: "AI systems may evolve to act as apprentices or collaborators for scientists in the laboratory." — Source: [Y Combinator]
- On Scientific Discovery: "The real promise of modern AI is not text generation, but accelerating scientific discovery in fields like biology and materials science." — Source: [Y Combinator]
- On General Intelligence: "Achieving generalized reasoning will require architectures that can plan, verify their own work, and learn from fewer examples." — Source: [Bloomberg]
- On Commercial Pressure: "The pressure to monetize AI models quickly can detract from the deep research required for the next massive leap forward." — Source: [Economic Times]
- On Democratization: "The technology is most beneficial when its foundational capabilities are accessible to researchers outside of the top few tech giants." — Source: [Economic Times]
- On Agentic Behavior: "We are moving from models that answer questions to models that execute multi-step workflows autonomously." — Source: [Wired]
- On Modality Convergence: "Eventually, the distinction between text, audio, and visual models will collapse into unified systems that process all modalities simultaneously." — Source: [Stanford CS25]
- On Model Interpretability: "As these systems integrate deeper into society, understanding exactly why a model made a specific decision will transition from a research interest to a societal requirement." — Source: [Bloomberg]
- On the Future: "We are still in the early days of understanding what neural networks are truly capable of when structured correctly." — Source: [India Science Festival]