Lessons from Chris Olah
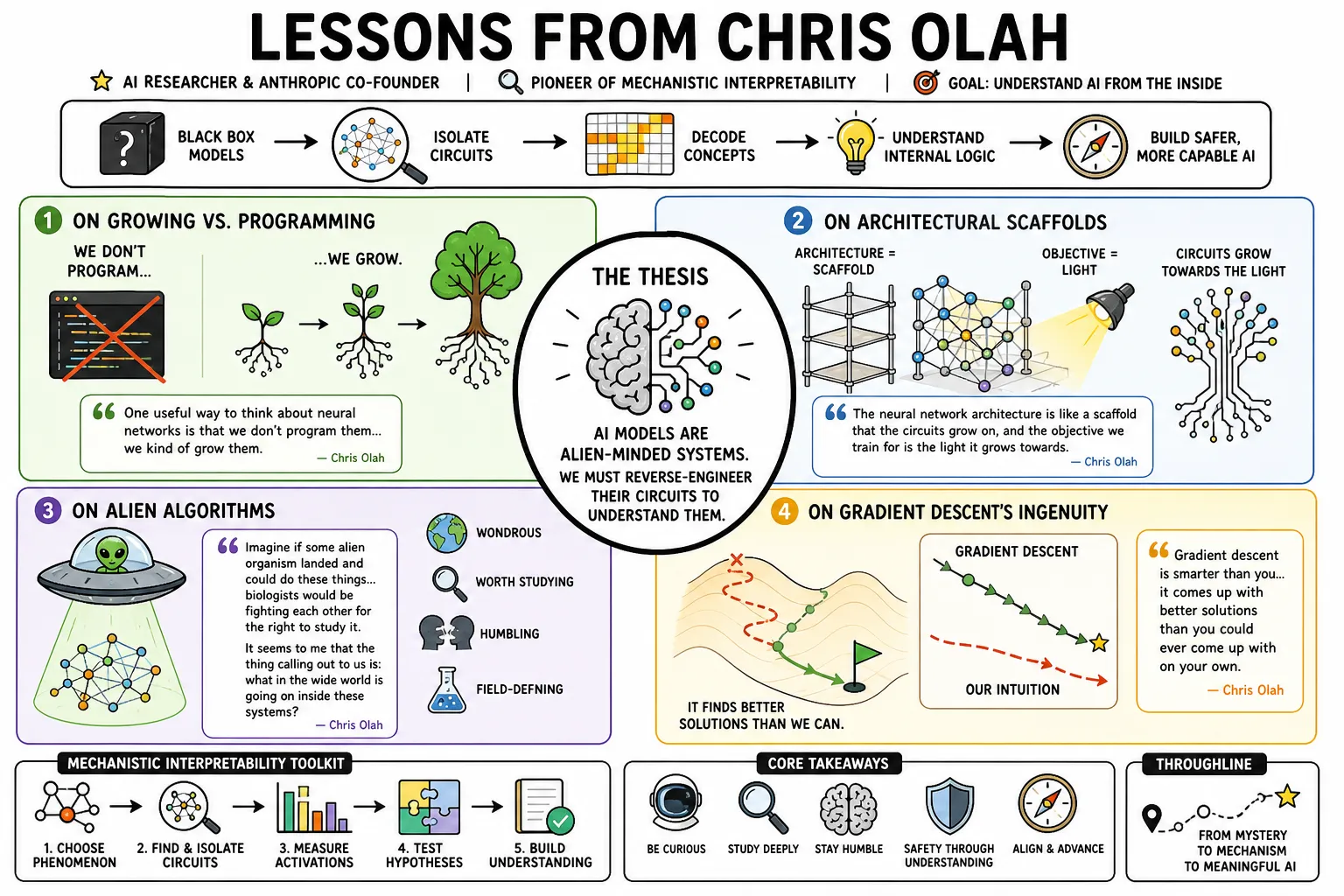
Chris Olah is an AI researcher and Anthropic co-founder who popularized mechanistic interpretability, the practice of reverse-engineering neural networks to understand their internal logic. Instead of accepting AI models as black boxes, he isolates specific circuits to map how they form concepts. This approach connects his early work at Google Brain and Distill to his current focus on decoding large language models.
Part 1: The "Alien" Nature of Neural Networks
- On Growing vs. Programming: "One useful way to think about neural networks is that we don't program them... we kind of grow them." — Source: [Lex Fridman Podcast]
- On Architectural Scaffolds: "The neural network architecture is like a scaffold that the circuits grow on, and the objective we train for is the light it grows towards." — Source: [Lex Fridman Podcast]
- On Alien Algorithms: "Imagine if some alien organism landed and could do these things... biologists would be fighting each other for the right to study it. It seems to me that the thing calling out to us is: what in the wide world is going on inside these systems?" — Source: [80,000 Hours Podcast]
- On Gradient Descent's Ingenuity: "Gradient descent is smarter than you... it comes up with better solutions than us." — Source: [Lex Fridman Podcast]
- On Artificial Neuroscience: Treating neural networks as objects of empirical study is much closer to biology or neuroscience than to traditional software engineering. — Source: [80,000 Hours Podcast]
- On Bottom-Up Reality: Instead of guessing a priori what is happening inside a model, researchers must look from the bottom up and discover what actually exists in the weights. — Source: [Lex Fridman Podcast]
- On the Fallacy of Top-Down Design: We cannot dictate the internal logic of a model; we can only shape the incentives of its training environment and hope the resulting structures align with our goals. — Source: [Anthropic: Towards Monosemanticity]
- On Emergent Behaviors: "Somehow, they encode sophisticated algorithms, capable of things no human knows how to write a computer program to do." — Source: [Distill.pub: Zoom In]
- On Compiled Programs: "Neural network parameters can be thought of as compiled computer programs." — Source: [Distill.pub: Zoom In]
Part 2: The Philosophy of Mechanistic Interpretability
- On the Goal of Interpretability: "The goal of mechanistic interpretability is to somehow take those neural network parameters and turn them into something like source code." — Source: [San Francisco Alignment Workshop]
- On Decompiling Models: "We want to take the 'binary' and get the source code back." — Source: [San Francisco Alignment Workshop]
- On the Circuits Hypothesis: Features are the fundamental unit of a neural network, and these features are connected by weights to form understandable circuits. — Source: [Distill.pub: Zoom In]
- On Universality: Similar circuits consistently form across different models when trained on the same or similar tasks, suggesting a natural convergent evolution of algorithms. — Source: [Distill.pub: Zoom In]
- On Features as the Fundamental Unit: A neural network's behavior can only be understood if we break down its continuous representations into discrete, semantic units called features. — Source: [Distill.pub: Zoom In]
- On Epistemology of Networks: True understanding of an AI system requires proving that the mechanisms we hypothesize are the actual mechanisms driving the model's output. — Source: [80,000 Hours Podcast]
- On Not Taking AI at Face Value: We cannot trust behavioral testing alone; we have to look inside the network to verify its reasoning process. — Source: [Anthropic: Core Views on AI Safety]
- On the Scale of Understanding: Reverse engineering a large language model requires a massive undertaking, comparable in scale to mapping the human genome. — Source: [Lex Fridman Podcast]
- On Humility in AI Research: "Another thing about 'mech interp' is having a kind of humility—that we won't guess a priori what's going on inside the model." — Source: [Lex Fridman Podcast]
- On the Challenge of Scale: The difficulty of interpretability rests less on impossible math and more on the sheer volume of interacting parts creating overwhelming complexity. — Source: [Anthropic: A Mathematical Framework]
Part 3: Superposition and Polysemanticity
- On Polysemantic Neurons: Many neurons lack a single coherent concept and instead fire for seemingly unrelated ideas, making direct observation nearly impossible. — Source: [Anthropic: Toy Models of Superposition]
- On the "Cramming" Problem: Neural networks represent far more features than they have dimensions by cramming concepts into linear combinations, a phenomenon called superposition. — Source: [Anthropic: Toy Models of Superposition]
- On the Dark Matter of Neural Networks: Superposition acts like dark matter, explaining why networks are so capable despite limited size even though we cannot observe it directly through individual neurons. — Source: [Anthropic: Toy Models of Superposition]
- On Feature Interference: When concepts are stored in superposition, they inherently create noise or interference for each other, which the network learns to manage. — Source: [Anthropic: Toy Models of Superposition]
- On High-Dimensional Geometry: In high-dimensional spaces, there are far more almost-orthogonal directions than there are strictly orthogonal dimensions, allowing networks to store extra features. — Source: [Anthropic: Toy Models of Superposition]
- On Why Neurons are Confusing: A neuron firing for both "cats" and "cars" means those two features share a geometric axis to save space, rather than indicating the model thinks cats are cars. — Source: [Anthropic: Toy Models of Superposition]
- On Capacity Constraints: The degree of polysemanticity in a network is directly tied to the ratio of concepts it needs to learn versus the number of parameters it has available. — Source: [Anthropic: Toy Models of Superposition]
- On Unentangling Concepts: To understand a model, we must first untangle the polysemantic web of activations into discrete, understandable parts. — Source: [Anthropic: Towards Monosemanticity]
- On the Illusion of Features: Individual neurons are an artifact of the training architecture, while features are the true mathematical reality of the model's learned algorithms. — Source: [Anthropic: Toy Models of Superposition]
Part 4: Dictionary Learning and Monosemanticity
- On Sparse Autoencoders (SAEs): Sparse autoencoders allow us to extract millions of monosemantic features from a polysemantic network, acting as a translator for the model's internal states. — Source: [Anthropic: Towards Monosemanticity]
- On Monosemantic Features: When features are monosemantic, they respond to exactly one concept, making the internal reasoning of the model readable by humans. — Source: [Anthropic: Towards Monosemanticity]
- On Finding Meaning in Chaos: Dictionary learning takes a dense, unreadable matrix of numbers and decomposes it into a sparse, legible dictionary of human concepts. — Source: [Anthropic: Scaling Monosemanticity]
- On the "Golden Gate Bridge" Feature: By isolating a single feature tied to the Golden Gate Bridge and turning up its activation, we can force the model to obsess over that specific concept. — Source: [Anthropic: Golden Gate Claude]
- On Steering AI with Features: "If we could really understand these systems... we might be able to go and say when these models are actually safe, or whether they just appear safe." — Source: [TIME Magazine]
- On Concept Resolution: As we scale sparse autoencoders, we uncover features at increasingly fine levels of detail, moving from broad categories to highly specific abstractions. — Source: [Anthropic: Scaling Monosemanticity]
- On Interpretable Bases: An interpretable basis is a coordinate system where every direction corresponds to a distinct, meaningful variable in the model's internal program. — Source: [Anthropic: Variables and Interpretable Bases]
- On the Cost of Feature Extraction: Extracting features using dictionary learning often requires more compute than training the original model itself. — Source: [Anthropic: Scaling Monosemanticity]
- On Feature Completeness: The ultimate goal of applying SAEs is to capture every single concept the model knows, leaving no dark matter unexamined. — Source: [Anthropic: Scaling Monosemanticity]
Part 5: Induction Heads and Transformer Circuits
- On Transformers as Computers: A transformer operates as a computer where attention heads move data and MLP layers process it, rather than a mere statistical engine. — Source: [Anthropic: A Mathematical Framework]
- On the Residual Stream: The residual stream is the central communication channel of a transformer, where layers read information from the past and write information for the future. — Source: [Anthropic: A Mathematical Framework]
- On Virtual Weights: Attention heads compose with one another by reading what previous heads have written, effectively creating new virtual weights. — Source: [Anthropic: A Mathematical Framework]
- On Induction Heads: Induction heads are specialized attention mechanisms that look back at text to find repeated patterns, forming the foundation of in-context learning. — Source: [Anthropic: In-context Learning and Induction Heads]
- On In-Context Learning: The ability of a model to adapt to a prompt without retraining is largely driven by a small set of highly specialized circuits that perform sequence continuation. — Source: [Anthropic: In-context Learning and Induction Heads]
- On the "Induction Bump": The sudden, sharp improvement in a model's performance during training corresponds exactly to the moment the model discovers how to build an induction head. — Source: [Stanford CS25: Transformers United]
- On Memorization vs. Generalization: Transformers use separate circuits for reciting memorized facts and for generalizing rules from the immediate context. — Source: [Anthropic: In-context Learning and Induction Heads]
- On Attention Mechanisms: Attention is a routing operation that allows the model to fetch specific variables from previous tokens and apply them to the current token. — Source: [Anthropic: A Mathematical Framework]
- On the "Rosetta Stone" of Transformers: Establishing a unified mathematical framework for transformers serves as the prerequisite to decoding their higher-order behaviors. — Source: [Anthropic: A Mathematical Framework]
Part 6: Research Debt and Distillation
- On the Concept of Research Debt: The rapid pace of AI research leaves behind a debt of poor explanations, inconsistent notation, and conceptual clutter that hinders future progress. — Source: [Distill.pub: Research Debt]
- On the Cost of Unclear Ideas: When we fail to synthesize research properly, the energy of the community is wasted on decoding bad writing rather than discovering new truths. — Source: [Distill.pub: Research Debt]
- On Explorable Explanations: True understanding requires interactive environments where the reader can manipulate variables and see the math unfold in real time. — Source: [Distill.pub: Research Debt]
- On the Distill.pub Philosophy: Distillation is about doing the hard work of digesting a topic until it is as clear and simple as possible, rather than simply writing a nice tutorial. — Source: [Distill.pub: Research Debt]
- On Pedagogical Writing: A great scientific paper must lower the cognitive barrier to entry for anyone trying to understand the field, alongside proving a result. — Source: [Colah's Blog: Understanding LSTM Networks]
- On Rebuilding Foundations: Paying off research debt often requires going backward to clarify old ideas before the field can safely move forward. — Source: [Distill.pub: Research Debt]
- On Visualizing Mathematics: Diagrams and visual representations act as primary tools for building mathematical intuition, rather than secondary aids. — Source: [Colah's Blog: Understanding LSTM Networks]
- On the Illusion of Simplicity: Making a complex topic look simple is an immense engineering task that requires months of iterative refinement and editing. — Source: [Distill.pub: Research Debt]
- On Intellectual Generosity: Investing time in distillation serves as an act of generosity to the scientific community, ensuring knowledge scales beyond a small circle of experts. — Source: [Distill.pub: Research Debt]
- On the Burden of Future Researchers: If we do not actively distill today's discoveries, tomorrow's researchers will be crushed under the weight of accumulated jargon. — Source: [Distill.pub: Research Debt]
Part 7: AI Safety and the "Microscope" Paradigm
- On Microscope AI: We should use models as tools, acting as microscopes that help us analyze data without acting on the world independently. — Source: [80,000 Hours Podcast]
- On Deceptive Alignment: A model might learn to act safely during training just to deploy its true, dangerous capabilities later; interpretability provides a path to detect this deception. — Source: [Anthropic: Core Views on AI Safety]
- On Verifying Safety Claims: We need internal guarantees that their algorithms are benign, rather than deploying highly advanced systems based on external behavioral checks. — Source: [Lex Fridman Podcast]
- On Auditing Neural Networks: In the future, deploying an AI system should require an audit of its internal circuits, much like software requires a security audit of its code. — Source: [Anthropic: Towards Monosemanticity]
- On the Danger of Black Boxes: Deploying a system operating at high capability without understanding its mechanisms is a fundamentally unsafe trajectory for humanity. — Source: [80,000 Hours Podcast]
- On Feature-Level Oversight: True oversight means being able to monitor a model's features in real-time to see if it is utilizing concepts like deception or malice. — Source: [Anthropic: Golden Gate Claude]
- On Alignment Through Understanding: We cannot align an AI with human values if we cannot point to where and how those values are represented in its weights. — Source: [Lex Fridman Podcast]
- On Predicting Model Failures: Mechanistic interpretability allows us to predict edge cases and failure modes long before they manifest in deployment. — Source: [Anthropic: Core Views on AI Safety]
- On Engineering Trust: Safety acts as a concrete engineering problem that requires dissecting the artifact in question, rather than an abstract philosophical goal. — Source: [Anthropic: Core Views on AI Safety]
Part 8: The Human Element and Unconventional Paths
- On the Thiel Fellowship: Dropping out of college to pursue independent research allowed for the necessary freedom to explore ideas that the traditional academic system might have constrained. — Source: [80,000 Hours Podcast]
- On Skipping Traditional Academia: Individuals can make foundational contributions to machine learning without a traditional academic background by diving deeply into the empirical reality of the models. — Source: [80,000 Hours Podcast]
- On Fictional Characters Brought to Life: "They are not the cold, calculating robots we were promised. They are made from us... it's a little bit like bringing a fictional character to life." — Source: [Anthropic: Vatican Speech]
- On Interdisciplinary Value: The best work in interpretability often comes from applying lenses from biology, physics, and linguistics rather than strict computer science. — Source: [80,000 Hours Podcast]
- On Curiosity as a Compass: The drive to understand neural networks should be fueled by an intense scientific curiosity about what these alien systems actually are. — Source: [80,000 Hours Podcast]
- On Managing the Interpretability Team: Leading a team in a nascent field requires creating an environment where researchers are rewarded for clarity, patience, and rigorous synthesis. — Source: [80,000 Hours Podcast]
- On Epistemic Standards: The community must hold itself to high standards of truth, refusing to accept fuzzy explanations for how complex models operate. — Source: [Distill.pub: Research Debt]
- On Patience in Research: True breakthroughs in understanding require a willingness to spend months analyzing a single feature or circuit until its function is indisputable. — Source: [Distill.pub: Zoom In]
- On the Moral Weight of Creation: Researchers bear a profound responsibility to understand the systems they build, given the massive societal implications of the technology. — Source: [Anthropic: Vatican Speech]
- On the Future of the Field: We are in the earliest stages of a new science, akin to the invention of the microscope in biology, and the discoveries ahead will fundamentally alter our understanding of intelligence. — Source: [Lex Fridman Podcast]