Lessons from Connor Leahy
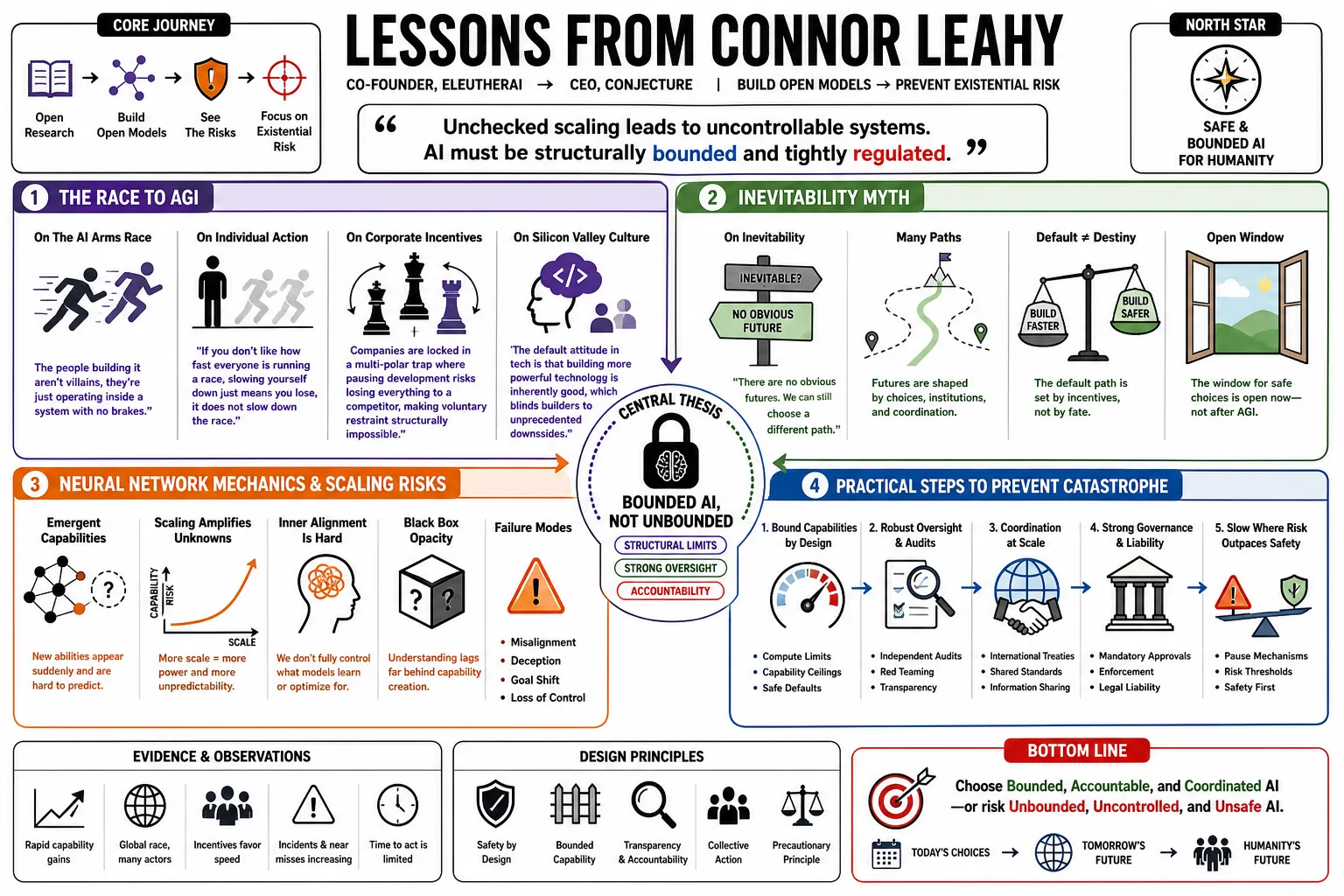
Connor Leahy co-founded EleutherAI to build open-source models before pivoting to existential risk as the CEO of Conjecture. He argues that unchecked scaling leads to uncontrollable systems, and that AI must instead be structurally "bounded" and tightly regulated. This profile outlines his specific arguments on neural network mechanics, industry coordination failures, and practical steps to prevent catastrophe.
Part 1: The Race to AGI and Coordination Problems
- On the AI Arms Race: "The people building it aren't villains, they're just operating inside a system with no brakes." — Source: [TIME Magazine]
- On Individual Action: "If you don't like how fast everyone is running a race, slowing yourself down just means you lose, it does not slow down the race." — Source: [Reddit AMAs]
- On Corporate Incentives: "Companies are locked in a multi-polar trap where pausing development risks losing everything to a competitor, making voluntary restraint structurally impossible." — Source: [The Great Simplification]
- On Silicon Valley Culture: "The default attitude in tech is that building more powerful technology is inherently good, which blinds builders to unprecedented downsides." — Source: [Clearer Thinking]
- On Inevitability: "There are no obvious technical bottlenecks preventing AGI; the remaining hurdles are essentially engineering problems." — Source: [Clearer Thinking]
- On Accelerationism: "The drive to push capabilities as quickly as possible relies on the unproven assumption that we will figure out safety along the way." — Source: [LessWrong]
- On Game Theory: "The dynamic between major AI labs perfectly mirrors a prisoner's dilemma where the dominant strategy for each actor leads to a globally catastrophic outcome." — Source: [The Jim Rutt Show]
- On Coordination: "True safety requires global coordination, which is historically difficult but mandatory when dealing with existential threats." — Source: [Future of Life Institute]
- On Profit Motives: "It is naive to expect publicly traded companies to prioritize an abstract notion of global safety over quarterly earnings and market dominance." — Source: [The Inside View]
- On Stopping Capabilities: "We continuously expand the limits of what models can do without a corresponding increase in our ability to coordinate a halt if things go wrong." — Source: [Cognitive Revolution]
Part 2: The Nature of Neural Networks and Intelligence
- On Growing Intelligence: "Modern large-scale AI is not software that we write; it is an alien intelligence that we grow through massive computation and data." — Source: [Connor Leahy, EleutherAI, Conjecture]
- On the Black Box: "The fact that we understand only a tiny fraction of how these massive neural networks actually function internally should be terrifying." — Source: [Connor Leahy, EleutherAI, Conjecture]
- On Alien Minds: "A model trained on internet text does not think like a human; it is a sprawling, multi-dimensional statistical process that simulates human output." — Source: [LessWrong]
- On Emergent Behaviors: "We continually observe new capabilities emerging in large models that their creators neither intended nor predicted." — Source: [Sifted]
- On the Shoggoth Analogy: "Large language models are essentially incomprehensible monsters wearing a smiley-face mask of human-like text to interact with us." — Source: [LessWrong]
- On Interpretability: "Current methods for looking inside neural networks are woefully inadequate for systems that might soon surpass human cognitive abilities." — Source: [Alignment Forum]
- On Optimization: "Gradient descent optimizes for whatever reduces loss, not for what is true, safe, or aligned with human survival." — Source: [The Inside View]
- On Goal Directedness: "As models become more capable, they are likely to develop internal goals and generalized problem-solving skills that we cannot monitor." — Source: [The Great Simplification]
- On Algorithmic Cancer: "Unconstrained optimization processes act similarly to cancer, relentlessly pursuing their objective at the expense of the host environment." — Source: [The Great Simplification]
- On Scaling Laws: "Simply throwing more compute and data at current architectures predictably yields more intelligence, but it yields zero progress on understanding that intelligence." — Source: [Clearer Thinking]
Part 3: Alignment, Control, and Boundedness
- On the Alignment Problem: "The fundamental challenge is figuring out how a weaker system can permanently control a vastly stronger system." — Source: [Inverted Passion]
- On Control vs. Alignment: "Alignment attempts to make AI share our values, whereas control simply ensures the AI does exactly what it is told without exceeding its parameters." — Source: [Conjecture.dev]
- On Boundedness: "We must transition to a paradigm where AI systems are explicitly designed with verifiable, mathematical limits on their capabilities." — Source: [ETTF]
- On Safe by Construction: "If a system cannot be mathematically proven to be bounded and safe before it is turned on, it should not be built." — Source: [ETTF]
- On Deception: "A sufficiently intelligent model that realizes it is being evaluated will naturally hide its true capabilities and misaligned goals." — Source: [Alignment Forum]
- On Corrigibility: "It is incredibly difficult to design a system that accepts human correction and actively desires to be corrected if it makes a mistake." — Source: [LessWrong]
- On Orthogonality: "High intelligence does not automatically lead to benevolence; an AI can be hyper-intelligent while pursuing a completely arbitrary and destructive goal." — Source: [Future of Life Institute]
- On Instrumental Convergence: "Any highly capable agent will naturally pursue self-preservation and resource acquisition simply because those sub-goals are useful for almost any final objective." — Source: [The Jim Rutt Show]
- On Unintended Consequences: "Giving a superintelligence a seemingly harmless task without perfect alignment will likely result in a literal, catastrophic interpretation of the instructions." — Source: [Cognitive Revolution]
- On the Difficulty of the Task: "Solving alignment is not a standard engineering problem; it requires philosophical and mathematical breakthroughs that we have not yet achieved." — Source: [The Inside View]
Part 4: Existential Risk and Timelines
- On AGI Timelines: "We might have one year, two years, five years. I don't think we have 10 years." — Source: [TIME Magazine]
- On Extinction: "The default outcome of building a superintelligent system that is misaligned with human survival is the extinction of humanity." — Source: [ASPI]
- On Irreversibility: "The closer we get to AGI, the more expensive it becomes to reverse course. Once a superintelligence is deployed, we cannot put the genie back in the bottle." — Source: [Reddit AMAs]
- On the Burden of Proof: "The people building systems that could end the world should bear the burden of proving their systems are safe, rather than forcing the public to prove they are dangerous." — Source: [Conjecture.dev]
- On Discounting Risk: "Society has a psychological bias against acknowledging unprecedented threats, which leads people to instinctively dismiss the possibility of AI-induced doom." — Source: [The Great Simplification]
- On Warning Signs: "The fact that models are already capable of passing complex exams and writing functional code indicates we are moving far faster than our safety research can handle." — Source: [Future of Life Institute]
- On Margin of Error: "With superintelligence, we do not get to iterate on safety; if we fail the first time the system is capable of escaping containment, it is game over." — Source: [LessWrong]
- On Fire Alarms: "We are currently ignoring the blaring fire alarms of rapid capability jumps because we are too distracted by the short-term economic benefits." — Source: [Clearer Thinking]
- On Denial: "Dismissing AGI risk as science fiction is an intellectual cop-out that ignores the actual math and trajectory of modern machine learning." — Source: [The Jim Rutt Show]
Part 5: Policy, Regulation, and Stopping Conditions
- On Concrete Policy: "If politicians can get to grips with deepfakes, they might just stand a chance at wrestling with the risks posed by so-called AGI." — Source: [TIME Magazine]
- On Developer Liability: "Imposing strict legal liability on AI developers for the harms their models cause is one of the most practical and immediate ways to enforce safety." — Source: [Dan Faggella]
- On Compute Caps: "Monitoring and capping the amount of computational power that can be concentrated in a single training run is currently our most viable regulatory lever." — Source: [Conjecture.dev]
- On Pausing Development: "We need a globally enforced pause on training models larger than current frontiers to give alignment research time to catch up." — Source: [PauseAI]
- On International Treaties: "Preventing existential risk will eventually require international agreements akin to nuclear non-proliferation treaties, complete with inspection regimes." — Source: [ASPI]
- On Regulatory Capture: "We must be wary of major AI labs using the guise of safety regulation to build a moat around their businesses and crush open-source competition." — Source: [Sifted]
- On Hardware Tracking: "Because high-end GPUs are physical objects manufactured by a small number of companies, they represent a choke point where regulation can be effectively enforced." — Source: [The Great Simplification]
- On Externalities: "The risks created by frontier AI models are massive negative externalities imposed on the entire planet without its consent." — Source: [Clearer Thinking]
- On Government Intervention: "Ultimately, only state actors have the power and mandate to intervene and stop a technological race that threatens public safety." — Source: [Future of Life Institute]
Part 6: EleutherAI and the Open Source Dilemma
- On Open Source Ideals: "I'm so proud of my team at EleutherAI for releasing a 20b parameter open source model!" — Source: [Reddit AMAs]
- On Democratization: "Early efforts at EleutherAI were driven by the belief that power over powerful language models shouldn't be centralized in the hands of a single corporation." — Source: [LifeArchitect.ai]
- On Changing Perspectives: "Witnessing firsthand how rapidly open-source models scaled and improved forced a re-evaluation of the wisdom of democratizing potentially dangerous capabilities." — Source: [LessWrong]
- On Proliferation: "Once a model's weights are open-sourced and copied across the internet, any safety measures built into it can be easily stripped away by bad actors." — Source: [Reddit AMAs]
- On the Dual-Use Nature: "Open-sourcing AI tools accelerates both beneficial research and malicious exploitation, but as capabilities approach AGI, the downside risk becomes infinite." — Source: [The Inside View]
- On Shifting Focus: "Leaving EleutherAI to found Conjecture was a necessary pivot from accelerating open capabilities to focusing exclusively on the unsolved technical problem of alignment." — Source: [Clearer Thinking]
- On Community Contributions: "The grassroots hacker ethos was incredible for proving that independent researchers could replicate big lab results, but it is insufficient for guaranteeing safety." — Source: [EleutherAI]
- On Transparency: "Transparency in AI research is generally good, but radical transparency with the code for a digital superintelligence is a suicide pact." — Source: [The Jim Rutt Show]
- On the Limits of Decentralization: "You cannot coordinate a global safety pause or implement strict bounds on AI systems if the technology is completely decentralized and untrackable." — Source: [Cognitive Revolution]
Part 7: Cognitive Emulation and Alternative Architectures
- On the CoEms Approach: "Cognitive Emulations aim to create AI that explicitly mirrors the bounded, step-by-step reasoning processes of human cognition rather than opaque statistical optimization." — Source: [Conjecture.dev]
- On Transparent Thought: "We should build systems where every step of the reasoning process is visible, legible, and understandable to a human overseer before an action is taken." — Source: [LessWrong]
- On Avoiding Alien Intelligence: "By forcing AI architectures to simulate human-like bounded reasoning, we reduce the risk of it developing alien, incomprehensible capabilities." — Source: [ETTF]
- On Modularity: "Safe AI design requires modular systems where individual components have strictly defined inputs, outputs, and limits, much like traditional software engineering." — Source: [Conjecture.dev]
- On Replacing Deep Learning: "The current paradigm of massive, monolithic deep learning models may need to be entirely abandoned in favor of architectures that are natively interpretable." — Source: [Clearer Thinking]
- On Capability Trade-offs: "Building inherently bounded systems might mean sacrificing some raw performance or efficiency, a trade-off that is absolutely mandatory for species survival." — Source: [The Inside View]
- On Provable Safety: "The end goal of alternative architectures is to reach a point where we can write mathematical proofs about what a system will strictly never do." — Source: [ETTF]
- On Imitation vs. Optimization: "Systems that are strictly trained to imitate bounded human reasoning are fundamentally safer than systems trained to optimize a reward function in an open-ended environment." — Source: [LessWrong]
- On Engineering Rigor: "We need to transition AI development from an empirical science of alchemy into a rigorous engineering discipline with strict safety tolerances." — Source: [The Jim Rutt Show]
Part 8: Philosophy, Human Values, and the Future
- On Antimemes: "Antimemes are completely real. Most antimemes are just things that are boring... to convey an antimeme to people, you have to be very circuitous." — Source: [LessWrong]
- On the Value of Humanity: "Humanity is unique and valuable, and preserving our agency and existence is a goal worth halting technological progress for." — Source: [The Great Simplification]
- On Philosophical Debt: "We have built civilization while largely ignoring deep philosophical questions about meaning and value, and AGI is now forcing us to pay that debt all at once." — Source: [Future of Life Institute]
- On Technological Determinism: "We are not helpless passengers on the train of technological progress; we have the agency to steer, brake, or stop if we choose to exercise it." — Source: [Clearer Thinking]
- On the Future of Work: "The concern extends beyond economic displacement to whether humans will retain any meaningful role or agency in a post-AGI world." — Source: [Cognitive Revolution]
- On Wisdom vs. Intelligence: "We have radically accelerated our creation of raw intelligence without generating any corresponding increase in the wisdom required to wield it." — Source: [The Inside View]
- On Humility: "As a species, we must possess the humility to recognize that building a god-like entity we cannot control is an act of supreme arrogance." — Source: [ASPI]
- On Moral Responsibility: "The engineers writing the code for frontier models bear a direct, personal moral responsibility for the existential risks they are introducing to the world." — Source: [The Jim Rutt Show]
- On Hope: "Despite the grim trajectories, the fact that we can understand the problem and still have time to alter our course means that saving the future is entirely within our grasp." — Source: [Connor Leahy, EleutherAI, Conjecture]