Lessons from Cynthia Dwork
Theoretical computer scientist Cynthia Dwork co-invented differential privacy and established the mathematics of algorithmic fairness. Her research proved how to extract useful data without exposing individuals and defined what it means for systems to treat similar people equally. This profile covers her ideas on the privacy-utility trade-off, the mechanics of fairness, and the strict limits of machine learning.
Part 1: The Privacy Problem
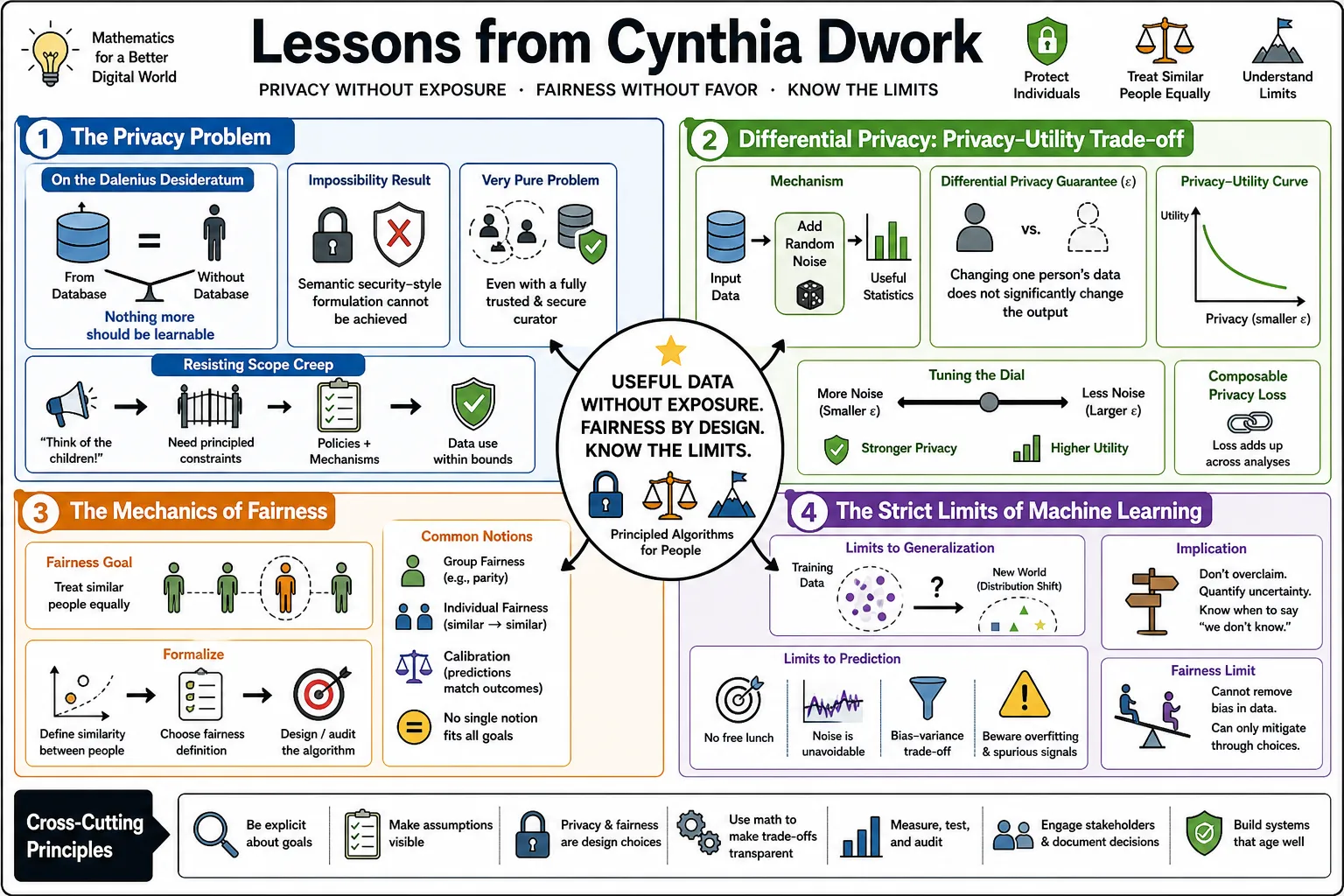
- On the Dalenius Desideratum: "In 1977 Dalenius articulated a desideratum for statistical databases: nothing about an individual should be learnable from the database that cannot be learned without access to the database. We give a general impossibility result showing that a formalization of Dalenius' goal along the lines of semantic security cannot be achieved." — Source: [Microsoft Research]
- On pure privacy: Balancing large-scale data analysis with individual privacy is a "very pure privacy problem" that persists even when the curator of the data is completely trusted and secure. — Source: [Ethan Zuckerman's Blog]
- On resisting scope creep: "People always come up with new uses and say 'Think of the children!' What can we give a curator to resist that sort of pressure?" — Source: [Ethan Zuckerman's Blog]
- On vague privacy policies: Typical institutional privacy policies offer empty assurances, effectively saying that your data is confidential unless they are required to disclose it by law or they feel they need to. — Source: [Ethan Zuckerman's Blog]
- On the illusion of anonymization: Merely removing names or identifying numbers from a dataset is mathematically insufficient to guarantee privacy against an adversary with auxiliary information. — Source: [The Algorithmic Foundations of Differential Privacy]
- On auxiliary information: The fundamental threat to database privacy is that external, seemingly harmless information can be combined with anonymized data to re-identify individuals. — Source: [The Algorithmic Foundations of Differential Privacy]
- On the impossibility of perfect privacy: If a database has any utility for answering statistical queries, it inherently leaks some amount of information about the individuals within it. — Source: [Microsoft Research]
- On protecting the absent: Paradoxically, a statistical release can threaten the privacy even of someone who is not included in the database at all, simply by revealing facts about their demographic group. — Source: [Microsoft Research]
- On the need for mathematical guarantees: Privacy cannot rely on intuition or ad-hoc anonymization techniques; it requires a rigorous mathematical definition that can withstand arbitrary future attacks. — Source: [Harvard SEAS]
- On the role of the curator: The entity holding the data must be equipped with formal tools to confidently release aggregate findings without needing to manually evaluate the privacy risk of every query. — Source: [The Algorithmic Foundations of Differential Privacy]
Part 2: Differential Privacy Foundations
- On what differential privacy is: "Differential privacy is a definition. It is a mathematical guarantee that can be satisfied by an algorithm that releases statistical information about a data set." — Source: [UNECE]
- On the core promise: Differential privacy guarantees that participating in a database will not substantially increase an individual's risk of any adverse outcome, compared to if they had opted out. — Source: [The Algorithmic Foundations of Differential Privacy]
- On algorithmic property: Differential privacy is a property of the data analysis algorithm itself, not a property of the specific dataset being analyzed. — Source: [The Algorithmic Foundations of Differential Privacy]
- On the epsilon parameter: The parameter epsilon controls the privacy loss; a smaller epsilon provides stronger privacy guarantees but may reduce the accuracy of the statistical outputs. — Source: [Harvard SEAS]
- On plausible deniability: The framework gives every individual plausible deniability, ensuring that the output of the analysis could have occurred whether or not their specific data was included. — Source: [Microsoft Research]
- On worst-case guarantees: The definition assumes the worst possible scenario, protecting against adversaries who may know everything about a dataset except the single row corresponding to the target individual. — Source: [The Algorithmic Foundations of Differential Privacy]
- On composition: A critical strength of differential privacy is that it is composable; if multiple differentially private analyses are performed, the total privacy loss is bounded and predictable. — Source: [The Algorithmic Foundations of Differential Privacy]
- On robustness to post-processing: Once an algorithm produces a differentially private output, no further computation on that output can reverse the privacy protection. — Source: [The Algorithmic Foundations of Differential Privacy]
- On shifting the burden: Instead of asking individuals to blindly trust a curator, differential privacy embeds the trust into verifiable mathematics. — Source: [Harvard SEAS]
- On not being a single algorithm: Many different algorithms can satisfy the differential privacy definition, giving data scientists a toolkit rather than a constraint. — Source: [UNECE]
Part 3: The Mechanics of Noise
- On injecting noise: To achieve differential privacy, algorithms must introduce carefully calibrated random noise into the computation or the output. — Source: [The Algorithmic Foundations of Differential Privacy]
- On query sensitivity: The amount of noise required depends on the sensitivity of the query, which measures how much a single individual's data could change the true answer. — Source: [The Algorithmic Foundations of Differential Privacy]
- On the Laplace mechanism: A foundational method for achieving differential privacy is adding noise drawn from a Laplace distribution scaled to the global sensitivity of the function being computed. — Source: [The Algorithmic Foundations of Differential Privacy]
- On local vs. global models: In the global model, a trusted curator adds noise to the output; in the local model, individuals add noise to their own data before sending it to the curator. — Source: [The Algorithmic Foundations of Differential Privacy]
- On hiding in the crowd: Noise provides cover; it ensures that any anomalous result could just as easily be the product of random chance as the presence of a specific individual. — Source: [Harvard SEAS]
- On interactive vs. non-interactive release: Differentially private systems can either answer specific queries interactively or release a synthetic dataset non-interactively for public analysis. — Source: [Microsoft Research]
- On the exponential mechanism: For queries with non-numeric outputs, the exponential mechanism selects an optimal response by skewing probabilities in favor of higher-utility outcomes while preserving privacy. — Source: [The Algorithmic Foundations of Differential Privacy]
- On utility limits: The fundamental theorem of the field demonstrates that you cannot ask an unlimited number of highly accurate questions without eventually violating privacy. — Source: [Microsoft Research]
- On randomized response: The concept traces its roots to 1960s social science techniques, where survey respondents used a coin flip to decide whether to answer a sensitive question truthfully or randomly. — Source: [The Algorithmic Foundations of Differential Privacy]
Part 4: Fairness Through Awareness
- On the fallacy of blindness: Fairness through blindness, the idea that ignoring protected attributes like race or gender ensures fair outcomes, frequently fails because algorithms can learn proxies for those attributes. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On the need for awareness: Achieving true fairness often requires explicit awareness of protected attributes in order to adjust for historical disparities and systemic biases. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On task-specific similarity: "In order to accomplish this individual-based fairness, we assume a distance metric that defines the similarity between the individuals. This is the source of 'awareness' in the title of this paper." — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On maintaining utility: The goal of fair classification is to prevent discrimination against individuals based on group membership while maintaining maximum predictive utility for the classifier. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On the risk of proxy variables: If a system is blind to race, it may rely heavily on zip codes or educational history, which often encode the exact disparities the system was trying to ignore. — Source: [Quanta Magazine]
- On affirmative action as awareness: Implementing a fairness metric mathematically forces a system to account for differences in background, functionally embedding a form of computational affirmative action. — Source: [Quanta Magazine]
- On societal context: Algorithms do not exist in a vacuum; understanding what constitutes similarity requires domain experts to articulate the societal context of the task. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On malicious fairness: A system can satisfy group-level fairness metrics while still maliciously misclassifying individuals within a group to sabotage the overall outcome. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On the limitations of group fairness: Statistical parity ensures that groups receive proportional outcomes, but it does nothing to guarantee that the most qualified individuals within a disadvantaged group are the ones selected. — Source: [Innovations in Theoretical Computer Science (ITCS)]
Part 5: Individual Fairness and Metrics
- On treating likes alike: "An algorithm is fair if it gives similar predictions to similar individuals." — Source: [Georgetown University Tech Law]
- On the Lipschitz condition: Individual fairness mathematically enforces a Lipschitz condition, meaning the distance between the algorithmic outcomes for two people cannot exceed the distance between the people themselves. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On the difficulty of metrics: The hardest part of implementing individual fairness is defining the task-specific similarity metric, as it requires quantifying exactly who is similar to whom for a given context. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On resolving the metric problem: While computer scientists can provide the algorithms, they cannot independently invent the fairness metric; this requires legal, ethical, and domain-specific consensus. — Source: [Quanta Magazine]
- On the connection to differential privacy: The mathematics of individual fairness are deeply related to differential privacy, as both frameworks rely on limiting how much a function's output can change based on a small change in input. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On arbitrary classification: If two individuals are functionally identical for a task, any discrepancy in their algorithmic treatment is arbitrary and therefore unfair. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On randomizing outcomes: Achieving individual fairness sometimes requires randomizing outcomes, such as giving two similar candidates an equal probability of a loan, rather than relying on deterministic thresholds. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On uncovering hidden biases: Developing a similarity metric forces organizations to make their implicit biases and hiring criteria explicit and subject to scrutiny. — Source: [Quanta Magazine]
- On moving beyond intuition: Fairness can no longer be a vague objective; it must be formalized mathematically if we want algorithms to reliably execute it at scale. — Source: [Harvard SEAS]
Part 6: Outcome Indistinguishability
- On moving past loss minimization: Traditional machine learning focuses on minimizing error, but Outcome Indistinguishability requires models to produce predictions that are computationally indistinguishable from real-world outcomes. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On computational bounds: A predictor achieves Outcome Indistinguishability if no computationally bounded algorithm can tell the difference between the predicted probabilities and the actual events. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On the Turing test for predictions: The framework functions like a cryptographic Turing test: if a discriminator algorithm cannot distinguish the model's outputs from nature's ground truth, the model is sufficiently accurate. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On multicalibration: Outcome Indistinguishability builds on multicalibration, ensuring that a model's predictions are calibrated not just on average, but simultaneously across many overlapping demographic subpopulations. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On the hierarchy of indistinguishability: There are varying levels of indistinguishability, ranging from models that match real-world expectations over broad groups to those that mimic nature down to individual trajectories. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On cryptographic roots: The concept borrows heavily from cryptography, specifically the idea of pseudorandomness, where a generated sequence is deemed secure if it cannot be distinguished from true randomness. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On predicting risk: When assessing risk, such as loan defaults or medical conditions, a model should output probabilities that behave indistinguishably from the underlying reality of those risks. — Source: [Simons Institute for the Theory of Computing]
- On algorithmic accountability: If an auditor can identify a specific subpopulation where the predictions systematically diverge from reality, the model fails the indistinguishability test. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
- On the nature of truth: Because we only ever observe a single outcome, Outcome Indistinguishability forces models to accurately capture the hidden, underlying probabilities of those events. — Source: [Simons Institute for the Theory of Computing]
- On bridging accuracy and fairness: By requiring predictions to be indistinguishable from reality across all computationally identifiable subgroups, the framework inherently prevents discriminatory model decay on minority populations. — Source: [ACM SIGACT Symposium on Theory of Computing (STOC '21)]
Part 7: Data Utility and Trade-offs
- On the accuracy-privacy tension: There is an inescapable, mathematical tension between the utility of a dataset and the privacy of the individuals contained within it. — Source: [The Algorithmic Foundations of Differential Privacy]
- On acceptable losses: Implementing differential privacy often requires accepting a marginal loss in accuracy to guarantee that no individual's data can be exploited. — Source: [The Algorithmic Foundations of Differential Privacy]
- On the budget of privacy: Privacy must be treated as a finite resource; every query run on a dataset consumes a portion of the privacy budget, and once exhausted, the data can no longer be safely queried. — Source: [Microsoft Research]
- On small datasets: Differential privacy struggles with very small datasets, because hiding a single individual requires adding noise that overwhelms the actual signal of the data. — Source: [The Algorithmic Foundations of Differential Privacy]
- On theoretical limits: Computer science can define the optimal trade-off curve between privacy and utility, but society must decide where on that curve it wishes to operate. — Source: [Quanta Magazine]
- On learning without memorizing: A useful differentially private algorithm successfully learns the general, population-level patterns of a dataset without memorizing any specific training examples. — Source: [The Algorithmic Foundations of Differential Privacy]
- On preventing overfitting: The mathematical guarantees of differential privacy inherently prevent models from overfitting to their training data, providing a secondary benefit to generalizability. — Source: [The Algorithmic Foundations of Differential Privacy]
- On infinite queries: It is mathematically impossible to answer an infinite number of unique, low-error queries on a dataset without entirely destroying the privacy of the participants. — Source: [Microsoft Research]
- On adaptive data analysis: Differential privacy provides a safeguard for adaptive data analysis, where researchers use the results of previous queries to inform the design of subsequent ones. — Source: [Harvard SEAS]
Part 8: Algorithmic Justice and Society
- On the US Census: The deployment of differential privacy in the 2020 US Census represented a massive real-world transition from theoretical privacy to institutional implementation. — Source: [WiDS 2019: Differential Privacy and the US Census]
- On mathematical rigor as a shield: Formal definitions of fairness and privacy serve as a shield against both adversarial attacks and careless institutional data practices. — Source: [Harvard SEAS]
- On algorithms encoding values: Algorithms are not objective arbiters of truth; they directly encode the values, biases, and historical inequalities of the societies that design them. — Source: [IPAM Green Family Lecture Series]
- On shifting the discourse: The introduction of differential privacy forced the technology industry to stop claiming that ad-hoc anonymization was sufficient for data protection. — Source: [Harvard SEAS]
- On interdisciplinarity: Solving the challenges of algorithmic fairness requires deep collaboration between computer scientists, legal scholars, philosophers, and social scientists. — Source: [Quanta Magazine]
- On the limits of technology: Mathematics can guarantee that an algorithm executes a specific definition of fairness, but it cannot determine whether that definition is just. — Source: [Innovations in Theoretical Computer Science (ITCS)]
- On structural inequality: If an algorithmic system operates in a world with structural inequality, a mathematically fair classification system is only one small part of achieving actual justice. — Source: [IPAM Green Family Lecture Series]
- On the burden of proof: Data curators and algorithm designers, rather than marginalized individuals, should bear the burden of proving that their systems do not cause harm. — Source: [Harvard SEAS]
- On the future of privacy: True privacy in the digital age will not come from restrictive data collection laws alone, but from building computational systems that make data abuse mathematically impossible. — Source: [Harvard SEAS]