Lessons from Denny Zhou
Denny Zhou is a research scientist and founder of the Reasoning Team at Google DeepMind. He is a primary author of Chain-of-Thought prompting, a technique that forces language models to generate intermediate steps before answering questions. This collection documents his approach to moving machine learning past simple text prediction and into structured problem-solving.
Part 1: Defining Reasoning in AI
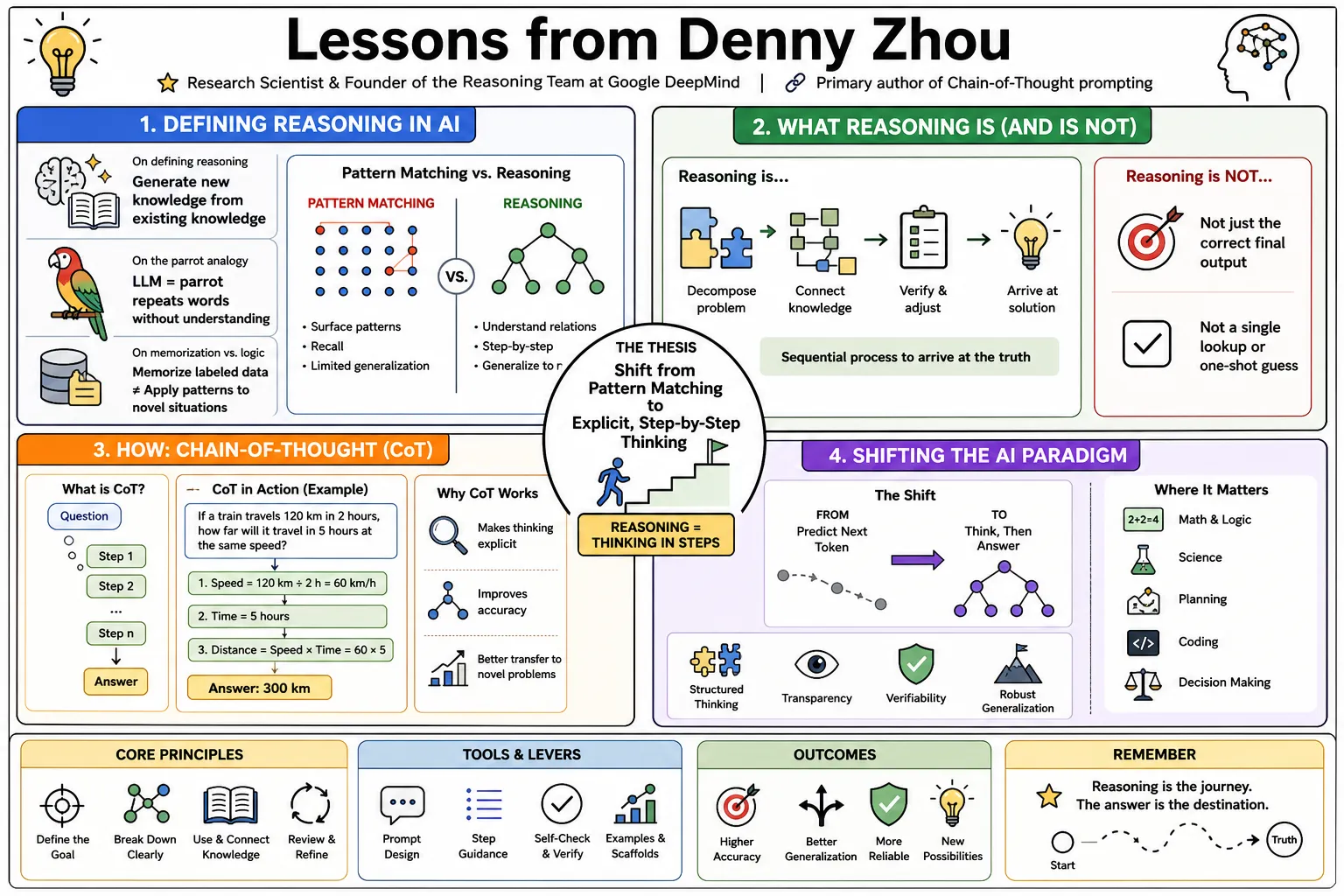
- On defining reasoning: "Reasoning is the ability to generate new knowledge from existing knowledge." — Source: [Stanford CS25 Lecture]
- On the parrot analogy: "An LLM is like a parrot that repeats words without understanding their meaning, merely repeating patterns of language." — Source: [Medium Summary of CS25]
- On memorization vs. logic: "Traditional machine learning relies heavily on memorizing labeled data, whereas true reasoning requires applying underlying patterns to novel situations." — Source: [KDD Keynote 2023]
- On moving beyond pattern matching: "We must shift our focus from models that simply match patterns to systems capable of explicit, step-by-step thinking." — Source: [Teach Language Models to Reason Talk]
- On what reasoning is not: "Reasoning is not just about retrieving the correct final output; it is about the sequential process used to arrive at that conclusion." — Source: [Stanford CS25 Lecture]
- On generating novel solutions: "If a model understands the base instructions, it can derive the correct output for combinations it has never seen during training." — Source: [Research on Analogical Reasoning]
- On the limits of predictive text: "While large language models are fundamentally probabilistic next-token predictors, we can elicit sophisticated problem-solving behaviors by changing how they are queried." — Source: [Chain-of-Thought Paper]
- On the nature of intermediate tokens: "Reasoning fundamentally relies on the generation of intermediate tokens to build a bridge between the problem statement and the final answer." — Source: [Stanford CS25 Notes]
- On analogical thinking in AI: "Models can be taught to identify analogies between different structural problems, allowing them to solve new scenarios without direct training data." — Source: [Teach Language Models to Reason Talk]
- On human-like cognition: "While we do not claim models 'think' exactly like humans, prompting them to simulate human reasoning steps drastically improves their accuracy on complex tasks." — Source: [Google DeepMind Research]
Part 2: The Chain-of-Thought Breakthrough
- On the origin of Chain-of-Thought: "Providing a few-shot 'chain of thought' as an example allows models to break down complex problems—like arithmetic and symbolic logic—into manageable steps." — Source: [Chain-of-Thought Paper]
- On altering the solution space: "Prompting for step-by-step logic is not just polite instruction; it fundamentally reshapes how the model searches its probability space." — Source: [Stanford CS25 Lecture]
- On scaling laws and reasoning: "Chain-of-thought prompting reveals reasoning capabilities that naturally emerge in large language models at scale." — Source: [Chain-of-Thought Paper]
- On standard prompting failures: "Standard prompting often falls short on tasks requiring complex logic because the model attempts to jump straight to the final answer." — Source: [KDD Keynote 2023]
- On performance gains: "By simply asking the model to 'think step by step', we observed massive improvements in math word problem benchmarks like GSM8K." — Source: [Chain-of-Thought Paper]
- On data efficiency: "Reasoning chains allow us to achieve state-of-the-art performance using only a small fraction of the annotated examples typically required for supervised training." — Source: [Teach Language Models to Reason Talk]
- On interpreting model outputs: "The intermediate steps generated by chain-of-thought make the model's behavior more interpretable, allowing researchers to see where the logic failed." — Source: [Chain-of-Thought Paper]
- On complex arithmetic: "Tasks that previously required specialized modules can now be solved directly by language models via explicit reasoning chains." — Source: [Stanford CS25 Lecture]
- On the simplicity of CoT: "The power of chain-of-thought lies in its simplicity—it requires no architectural changes to the underlying model." — Source: [Chain-of-Thought Paper]
- On few-shot exemplars: "The quality of the reasoning examples provided in the prompt directly influences the quality of the model's generated logic." — Source: [Google DeepMind Research]
Part 3: Self-Consistency and Reliability
- On the premise of Self-Consistency: "Instead of relying on a single decoding path, we sample multiple diverse reasoning paths and select the most consistent answer." — Source: [Self-Consistency Paper]
- On mitigating single-path errors: "Self-consistency acts as an error-correction mechanism, recognizing that a model might occasionally generate a flawed reasoning chain." — Source: [Self-Consistency Paper]
- On majority voting in AI: "By applying a majority vote over multiple generated solutions, we significantly increase the reliability of the final output." — Source: [Stanford CS25 Lecture]
- On confidence and logic: "A model's confidence in an answer strongly correlates with the frequency of that answer across different sampled reasoning paths." — Source: [Self-Consistency Paper]
- On orthogonal improvements: "Self-consistency improves performance independent of the underlying prompt, acting as an orthogonal boost to chain-of-thought." — Source: [Self-Consistency Paper]
- On replacing greedy decoding: "For tasks requiring logic, greedy decoding is suboptimal; sampling diverse paths yields far better results." — Source: [KDD Keynote 2023]
- On temperature scaling: "Introducing temperature into the sampling process allows the model to explore a wider variety of valid reasoning trajectories." — Source: [Self-Consistency Paper]
- On robustness to prompt variations: "Using self-consistency makes the model's performance less sensitive to the exact phrasing of the prompt exemplars." — Source: [Teach Language Models to Reason Talk]
- On computational cost vs. accuracy: "While sampling multiple paths increases compute cost at inference, the dramatic reduction in hallucinated answers justifies the trade-off." — Source: [Stanford CS25 Lecture]
- On ensemble thinking: "Self-consistency mimics a committee of experts, where the most commonly agreed-upon answer is usually correct." — Source: [Self-Consistency Paper]
Part 4: Problem Decomposition and Least-to-Most Prompting
- On compositional generalization: "Least-to-most prompting enables models to tackle novel, complex problems by breaking them down into simpler, previously solved sub-problems." — Source: [Least-to-Most Prompting Paper]
- On easy-to-hard solving: "We can guide language models to solve hard problems by explicitly asking them to solve easier sub-components first." — Source: [Least-to-Most Prompting Paper]
- On length generalization: "Models often struggle with problems longer than those seen in prompts; least-to-most prompting bridges this gap." — Source: [Least-to-Most Prompting Paper]
- On recursive problem solving: "The answer to a sub-problem is appended to the prompt to help the model solve the next sub-problem in the sequence." — Source: [Stanford CS25 Notes]
- On explicit decomposition: "Unlike standard chain-of-thought, least-to-most explicitly requires the model to generate the list of sub-questions before answering them." — Source: [Least-to-Most Prompting Paper]
- On symbolic manipulation: "For tasks like concatenating the last letters of words, breaking the list into smaller chunks prevents the model from losing track of its state." — Source: [Teach Language Models to Reason Talk]
- On managing context windows: "By isolating sub-problems, we reduce the cognitive load on the model's self-attention mechanism at any given step." — Source: [KDD Keynote 2023]
- On dynamic prompting: "The prompt dynamically expands as the model solves each intermediate step, building a verified context for the final answer." — Source: [Least-to-Most Prompting Paper]
- On algorithmic execution: "Least-to-most prompting forces the language model to act more like an algorithm executing a while-loop." — Source: [Stanford CS25 Lecture]
Part 5: In-Context Learning and Model Optimization
- On zero-shot reasoning: "Models can sometimes perform reasoning tasks without explicit examples simply by appending 'Let's think step by step' to the query." — Source: [Large Language Models as Optimizers Paper]
- On instruction tuning: "Finetuning models on a diverse collection of tasks expressed as instructions drastically improves their ability to reason on unseen tasks." — Source: [Google DeepMind Research]
- On the FLAN collection: "The FLAN approach demonstrates that exposure to various reasoning structures during tuning creates a more adaptable model." — Source: [Teach Language Models to Reason Talk]
- On language models as optimizers: "We can use an LLM to iteratively evaluate and improve its own generated prompts based on task performance." — Source: [Large Language Models as Optimizers Paper]
- On automated prompt engineering: "Instead of humans guessing the best instructions, we let the language model search for the optimal prompt in natural language." — Source: [Large Language Models as Optimizers Paper]
- On meta-prompts: "By providing a meta-prompt that describes the optimization task, the model learns to propose better instructions for itself." — Source: [Large Language Models as Optimizers Paper]
- On gradient-free optimization: "Prompt optimization with LLMs offers a gradient-free way to improve system performance without updating model weights." — Source: [Stanford CS25 Lecture]
- On the mathematical foundations of learning: "In-context learning works because the model's attention mechanism implicitly performs a form of gradient descent on the provided examples." — Source: [KDD Keynote 2023]
- On overcoming prompt brittleness: "Automated optimization helps identify prompts that are mathematically optimal for the model's specific parameter state." — Source: [Large Language Models as Optimizers Paper]
Part 6: Decoding Strategies and Intrinsic Capabilities
- On intrinsic reasoning paths: "Reasoning capabilities are often inherent in a model's pre-trained probability space, waiting to be unlocked." — Source: [Chain-of-Thought Reasoning Without Prompting Paper]
- On the flaws of greedy decoding: "Always picking the single most likely next token hides the model's true reasoning capabilities." — Source: [Chain-of-Thought Reasoning Without Prompting Paper]
- On exploring alternative tokens: "By examining the top-k alternative tokens during decoding, we often find natural reasoning chains forming without explicit prompts." — Source: [Chain-of-Thought Reasoning Without Prompting Paper]
- On CoT without prompting: "Altering the decoding process allows models to generate reasoning paths purely from their base training distribution." — Source: [Chain-of-Thought Reasoning Without Prompting Paper]
- On the hidden state of LLMs: "There is a massive discrepancy between what a model knows and what it outputs when forced down a greedy path." — Source: [Stanford CS25 Lecture]
- On pre-training data: "The sheer volume of code and step-by-step logic in pre-training corpora bakes latent reasoning structures into the model's weights." — Source: [Teach Language Models to Reason Talk]
- On decoding as search: "We must treat text generation not as a linear sequence, but as a search problem over a vast graph of logical possibilities." — Source: [Stanford CS25 Notes]
- On confidence scores: "Models assign high confidence to tokens that belong to a logical sequence, even if that sequence isn't the absolute top-1 prediction initially." — Source: [Chain-of-Thought Reasoning Without Prompting Paper]
- On reducing prompt engineering: "As we improve decoding algorithms, the reliance on meticulously crafted prompt engineering will naturally decrease." — Source: [KDD Keynote 2023]
Part 7: The Limitations of Current Models
- On susceptibility to distraction: "Language models are highly sensitive to irrelevant context, which can easily derail their reasoning processes." — Source: [Google DeepMind Research]
- On the hallucination problem: "When models fail to reason correctly, they often hallucinate confidently, masking logical errors with fluent text." — Source: [Stanford CS25 Lecture]
- On out-of-distribution tasks: "A model's reasoning breaks down quickly when presented with structural rules that contradict its pre-training." — Source: [Teach Language Models to Reason Talk]
- On the limits of scale: "Simply making a model larger does not automatically grant it the ability to solve highly compositional logic puzzles." — Source: [Chain-of-Thought Paper]
- On arithmetic failures: "Models still struggle with exact arithmetic on very large numbers because they operate on sub-word tokens rather than digits." — Source: [Stanford CS25 Notes]
- On logical consistency: "A model might correctly solve a problem one way, but fail when the same problem is phrased with a negative constraint." — Source: [KDD Keynote 2023]
- On evaluating reasoning: "Current benchmarks are inadequate because they measure the final output rather than the validity of the reasoning chain itself." — Source: [Teach Language Models to Reason Talk]
- On prompt sensitivity: "The fact that adding a single space to a prompt can change the output demonstrates how fragile LLM reasoning remains." — Source: [Large Language Models as Optimizers Paper]
- On memory constraints: "Long reasoning chains eventually overwhelm the model's attention span, causing it to forget early assumptions." — Source: [Stanford CS25 Lecture]
Part 8: The Path Toward Artificial General Intelligence
- On the path to AGI: "Achieving Artificial General Intelligence requires moving beyond models that predict text to systems that actively plan and verify logic." — Source: [Teach Language Models to Reason Talk]
- On model verification: "The next frontier is building models that can reliably verify their own reasoning steps before generating the final token." — Source: [Stanford CS25 Lecture]
- On system 1 vs. system 2 thinking: "We are transitioning LLMs from fast, intuitive 'System 1' responses to slow, deliberate 'System 2' thinking." — Source: [KDD Keynote 2023]
- On inference scaling: "Future performance gains will come from scaling compute during inference—allowing the model more time to 'think'—rather than just during training." — Source: [Stanford CS25 Notes]
- On autonomous agents: "Robust reasoning is the prerequisite for deploying language models as autonomous agents capable of executing multi-day tasks." — Source: [Google DeepMind Research]
- On self-improvement: "Models will eventually use their reasoning capabilities to generate their own high-quality training data, creating a self-improving loop." — Source: [Large Language Models as Optimizers Paper]
- On integrating external tools: "Teaching models to reason includes teaching them when to pause and query external calculators, search engines, or code interpreters." — Source: [Teach Language Models to Reason Talk]
- On the definition of success: "Success is a model that says 'I don't know' when it cannot construct a valid chain of thought." — Source: [Stanford CS25 Lecture]
- On the ultimate goal: "Our goal is not just to build a better chatbot, but to create an automated scientist capable of discovering genuinely new knowledge." — Source: [Google DeepMind Research]