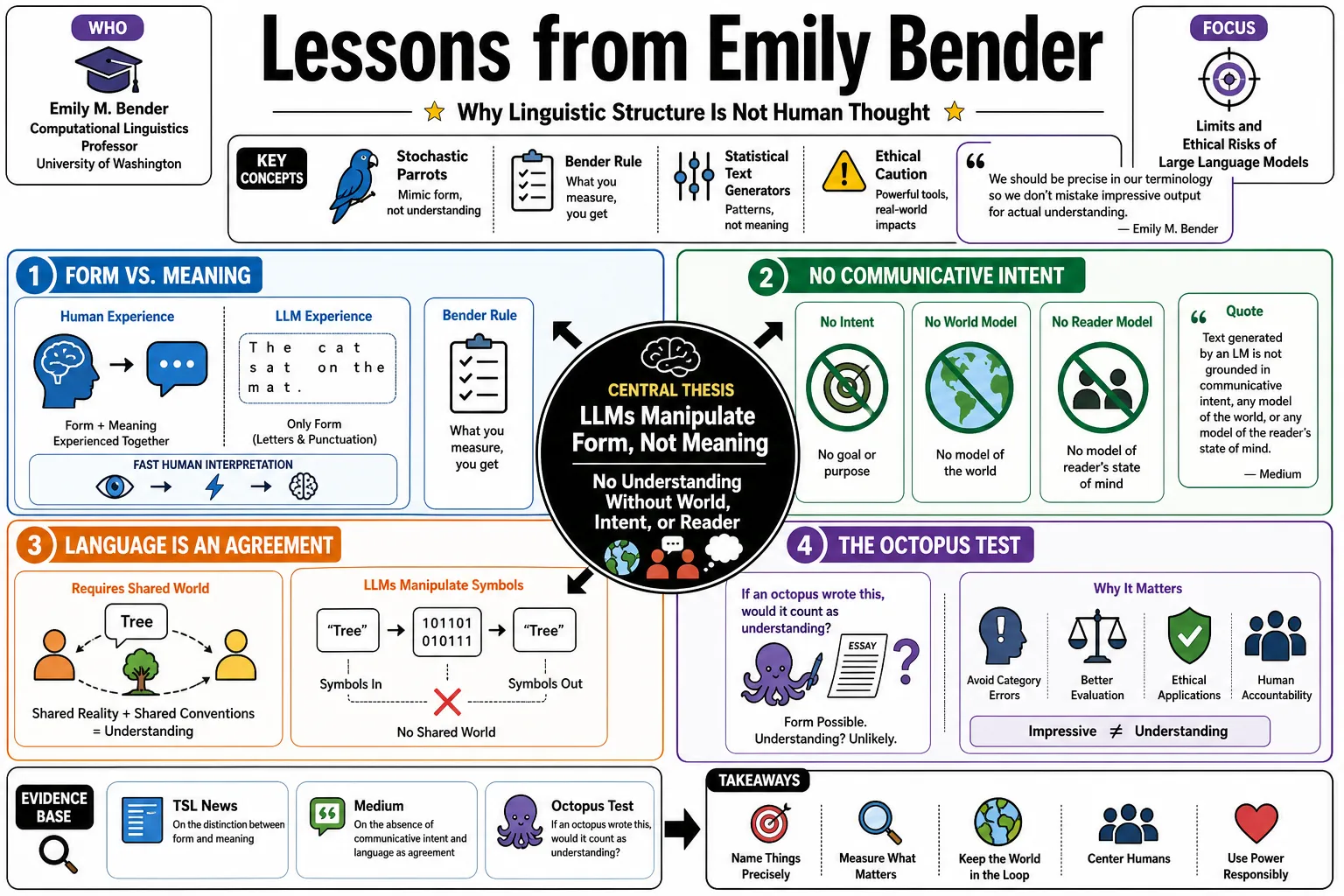
Emily M. Bender is a computational linguistics professor at the University of Washington who studies the limits and ethical risks of large language models. Through concepts like the "Bender Rule" and "stochastic parrots," she argues that statistical text generators lack actual understanding. This profile gathers her case for precise terminology and explains why linguistic structure shouldn't be mistaken for human thought.
Part 1: The Mechanics of Form Versus Meaning
- On the distinction between form and meaning: "When we are using language, we usually can't experience the form without the meaning, because we interpret it so fast. On the other hand, the only thing a large language model can learn is about form—sequences of letters and punctuation." — Source: TSL News
- On the absence of communicative intent: "Text generated by an LM is not grounded in communicative intent, any model of the world, or any model of the reader's state of mind." — Source: Medium
- On language as an agreement: Language requires a shared understanding of the physical world, something a system manipulating text symbols inherently lacks. — Source: Medium
- On the Octopus Test: If an octopus intercepts telegraph messages and learns to mimic the statistical patterns of human conversation, it still has no physical understanding of what words like "bear" or "coconut" represent. — Source: Kottke
- On projection: Our perception of natural language text is mediated by our own linguistic competence, causing us to interpret communicative acts as conveying coherent meaning whether or not they actually do. — Source: Medium
- On human empathy: "Human-like programs abuse our empathy – even Google engineers aren't immune." — Source: The Guardian
- On the gap in training data: It is impossible for a language model to have intent because the training data never included sharing thoughts with a listener, nor does the machine have the physical ability to do so. — Source: Medium
- On mimicking understanding: These systems mimic the syntax and style of human language, but they possess absolutely no understanding of the concepts behind the words they arrange. — Source: Substack
- On correct answers as chance: "We have to keep in mind that when [LLM] output is correct, that is just by chance. You might as well be asking a Magic 8 ball, right?" — Source: TSL News
- On form as the only learned element: A system trained exclusively on the physical realization of language—pixels, sounds, or bits—cannot inherently cross the gap to actual meaning. — Source: ResearchGate
Part 2: The Stochastic Parrot
- On the stochastic parrot metaphor: "Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data... without any reference to meaning: a stochastic parrot." — Source: Quote Investigator
- On probability over cognition: A large language model simply calculates what character or word is statistically likely to follow another, rather than constructing a thought. — Source: Wikipedia
- On hallucination as design: When a system generates false information, it is not a bug or a hallucination, but the system functioning exactly as designed: probabilistically linking forms. — Source: TSL News
- On paper-mâché data: "People think that retrieval augmented generation is going to make it better, but… paper mache of good data is still paper mache." — Source: TSL News
- On resisting the illusion: We must actively remind ourselves that fluent text from a machine does not indicate a mind at work behind the screen. — Source: The Voice of User
- On the danger of scale: Making a language model larger and feeding it more text does not turn it into a system that understands meaning; it just makes it a more convincing parrot. — Source: Wikipedia
- On meaning as a human action: Meaning is not a property of the text itself, but a relationship between the speaker, the listener, and the shared physical world. — Source: Medium
- On linguistic mimicry: The appearance of intelligence in AI output is an illusion created by the machine's ability to copy human linguistic patterns without comprehending them. — Source: Substack
- On the danger of band-aids: "All of these places where synthetic text looks like a nice handy band-aid... we need to say no to that because it's actually worse than nothing." — Source: Reddit
Part 3: Redefining AI as Automation
- On dropping the term AI: "I would like the word artificial intelligence to just drop out of the lexicon." — Source: YouTube
- On accurate terminology: When people discuss these tools, they should say exactly what it is that they built, such as "probabilistic automation" or "synthetic media creation." — Source: YouTube
- On the automation question: "I think that discussions of this technology become much clearer when we replace the term AI with the word 'automation'." — Source: Simon Willison’s Weblog
- On assessing automation: Once we call it automation, we can ask the necessary questions: "What is being automated? Who's automating it and why? Who benefits?" — Source: Simon Willison’s Weblog
- On synthetic text extruding machines: She prefers to call large language models "synthetic text extruding machines" to strip away the false metaphor of intelligence. — Source: YouTube
- On wishful mnemonics: Using terms like "learn," "understand," or "think" to describe software misleads the public and causes them to anthropomorphize the technology. — Source: TechPolicy Press
- On marketing labels: "Artificial Intelligence" is fundamentally a marketing term rather than a rigorously defined technical category. — Source: Mastodon
- On deflecting responsibility: "If you can say it was the machine that did the picking... here's where I think that the apparent value of calling it AI comes in." — Source: Business Insider
- On masking random chance: Using the term AI allows decision-makers to blame algorithms for choices they would otherwise have to admit were made by random chance or flawed logic. — Source: Business Insider
Part 4: Data Statements and Accountability
- On datasets being too big: When datasets become unfathomably large, researchers can no longer be accountable for the specific contents they contain. — Source: Voices of VR
- On data statements as a requirement: "As a general rule, you can't reason about the results of some scientific study based on data without clear information about the data itself, how it was collected, etc." — Source: Morgan Klaus
- On curation over ingestion: The practice of scraping the entire internet must be replaced by deliberate, documented curation of texts. — Source: Hypotheses
- On tracking language variety: A data statement must detail the specific dialects or regional variations included, such as specifying "English as spoken in Palo Alto." — Source: Morgan Klaus
- On annotator demographics: It is necessary to document the age, gender, race, and native language of the people who created or labeled the data. — Source: Morgan Klaus
- On the myth of unbiased data: "There is no such thing as any dataset or model that's completely unbiased. A lot of this is just about harm mitigation." — Source: Northeastern University
- On scientific reproducibility: Without understanding the exact composition of a dataset, independent researchers cannot verify or reproduce the results of an NLP system. — Source: TransACL
- On knowing what you test: Good science requires researchers to treat their training data as a variable to be understood rather than an infinite bucket of words. — Source: Medium
- On the curation rationale: Developers must explicitly state why certain texts were included in a dataset and why others were excluded. — Source: Morgan Klaus
Part 5: The Bender Rule and Linguistic Bias
- On the core directive: The Bender Rule simply states: "Always name the language you’re working on." — Source: Because Language
- On the veneer of language-independence: Failing to name the language creates a false assumption that a technique works universally, rather than just on the language it was tested on. — Source: The Gradient
- On English as the default: NLP research has a long history of treating English as the default standard, ignoring the structural realities of the world's other 7,000 languages. — Source: NIH
- On language specificity: "Acknowledging that we are working on a particular language foregrounds the possibility that the techniques may in fact be language specific." — Source: The Gradient
- On generalizing findings: A model that achieves high accuracy on English data cannot be assumed to perform similarly on languages with different morphological or syntactic structures. — Source: The Gradient
- On structural privilege: Focusing exclusively on high-resource languages leaves speakers of marginalized languages excluded from technological benefits. — Source: Wikipedia
- On scientific precision: Stating "the system achieves 90% accuracy on English" is a scientifically accurate claim, whereas "the system achieves 90% accuracy" is an overstatement. — Source: The Gradient
- On morphological complexity: Techniques optimized for a language with relatively simple morphology like English often fail on highly inflected or agglutinative languages. — Source: Because Language
- On decentering English: The Bender Rule forces the AI field to decenter English and recognize it as just one of many human linguistic systems. — Source: The Gradient
- On the assumption of universality: Researchers often mistake the specific quirks of English grammar for universal properties of human thought or logic. — Source: Because Language
Part 6: Dismantling AI Hype
- On the Naked Emperor effect: "Surprisingly many people, especially those in positions of power, seemingly want to be the naked emperors. That is, they want to believe the hype and convince everyone around to join them." — Source: ESC Key
- On the Booster versus Doomer binary: "The booster versus doomer thing is really constricting... it’s a really small space of possibilities." — Source: Business Insider
- On hiding the people: The narrative framing of AI as an autonomous entity is deliberately designed to hide the human decisions and labor behind the technology. — Source: Business Insider
- On synthetic text generation: "If they couldn't be bothered to write this, why should we be bothered to read it?" — Source: Convergence Mag
- On the economics of hype: "One journalist I talked to pointed out that nobody gets paid to combat AI hype, but lots of people are getting paid to put it out." — Source: TechPolicy Press
- On the intent of hype: "It’s easy to get lost in [the hype], and it’s not an accident that you get lost in it." — Source: Business Insider
- On resisting the urge to be impressed: "We all, but especially journalists, must resist the urge to be impressed." — Source: Mastodon
- On the summit of bullshit mountain: Each time critics believe they have reached peak AI hype, the technology industry manages to produce an even more exaggerated claim. — Source: Buzzsprout
- On the definition of writing: "AI is not 'good at writing'—it's designed to produce plausible-sounding synthetic text." — Source: Critical AI
Part 7: Human Labor and Exploitation
- On the hidden human element: "AI is always people. But they're hidden." — Source: Daily UW
- On the illusion of AI: "The tech firms hide the labor and the humanity of the microworkers in systems that are designed to produce the illusion of AI." — Source: Daily UW
- On stolen data: "You can assume that if they aren't telling you otherwise, it's built on stolen data." — Source: Convergence Mag
- On fake automation: Technologies like Amazon’s "Just Walk Out" stores were frequently framed as autonomous, while actually relying on extensive human monitoring in other countries. — Source: Daily UW
- On environmental costs: The massive energy required to train these language models contributes to climate change, which disproportionately affects communities that see none of the technology's benefits. — Source: Wikipedia
- On the question of "Smart": Whenever a product is labeled as "smart," consumers should immediately ask what data is being collected and where it is going. — Source: Convergence Mag
- On amplifying toxicity: Because language models ingest the internet indiscriminately, they inevitably absorb and amplify hegemonic viewpoints and toxic language. — Source: Wikipedia
- On human agency: "The future is not written. And anytime we sort of say, 'well we've just got to deal with it,' we are basically giving in to big tech's demands for us to give up our agency." — Source: YouTube
- On the cost to marginalized groups: The rush to deploy massive language models frequently ignores the direct harm caused to marginalized communities by biased or harmful outputs. — Source: Wikipedia
- On data opting out: We need clear, accessible mechanisms for individuals to opt out of having their personal data fed into commercial language models. — Source: Convergence Mag
Part 8: Policy, Education, and Moving Forward
- On the right to refuse AI: "It should be possible to be a student at the University of Washington without having to use this stuff... 'No' should always be among the options for classroom usage of AI." — Source: Daily UW
- On engaging with policymakers: "Talking with policy makers... is better than shouting to the void on Twitter." — Source: YouTube
- On reading the footnotes: A critical approach to technology requires looking past the press release and always reading the footnotes of scientific claims. — Source: Buzzsprout
- On educational boundaries: Institutions must protect students' rights to learn without being forced to interact with synthetic text extruding machines. — Source: Daily UW
- On fighting inevitability: Tech companies frame the adoption of their tools as inevitable, but society has the power to reject systems that do not serve human interests. — Source: YouTube
- On evaluating utility: Before adopting a language model, organizations must ask if the task actually requires a machine to generate plausible-sounding text, or if it requires factuality and accountability. — Source: Simon Willison’s Weblog
- On the burden of proof: The burden of proving that an automated system is safe and unbiased should lie with the developers, not with the public discovering harms after deployment. — Source: Voices of VR
- On questioning the data: Every time a new system is announced, the immediate public response should be a demand to see the training data statement. — Source: Morgan Klaus
- On maintaining human connection: Communication is fundamentally about humans connecting with other humans, a process that cannot be automated without losing its core purpose. — Source: Medium