Lessons from Finale Doshi-Velez
Finale Doshi-Velez is a Harvard computer science professor focused on making machine learning safe for healthcare. She is known for defining exactly what AI interpretability means and how to measure it. This profile collects her arguments for holding complex algorithms accountable when human lives are on the line.
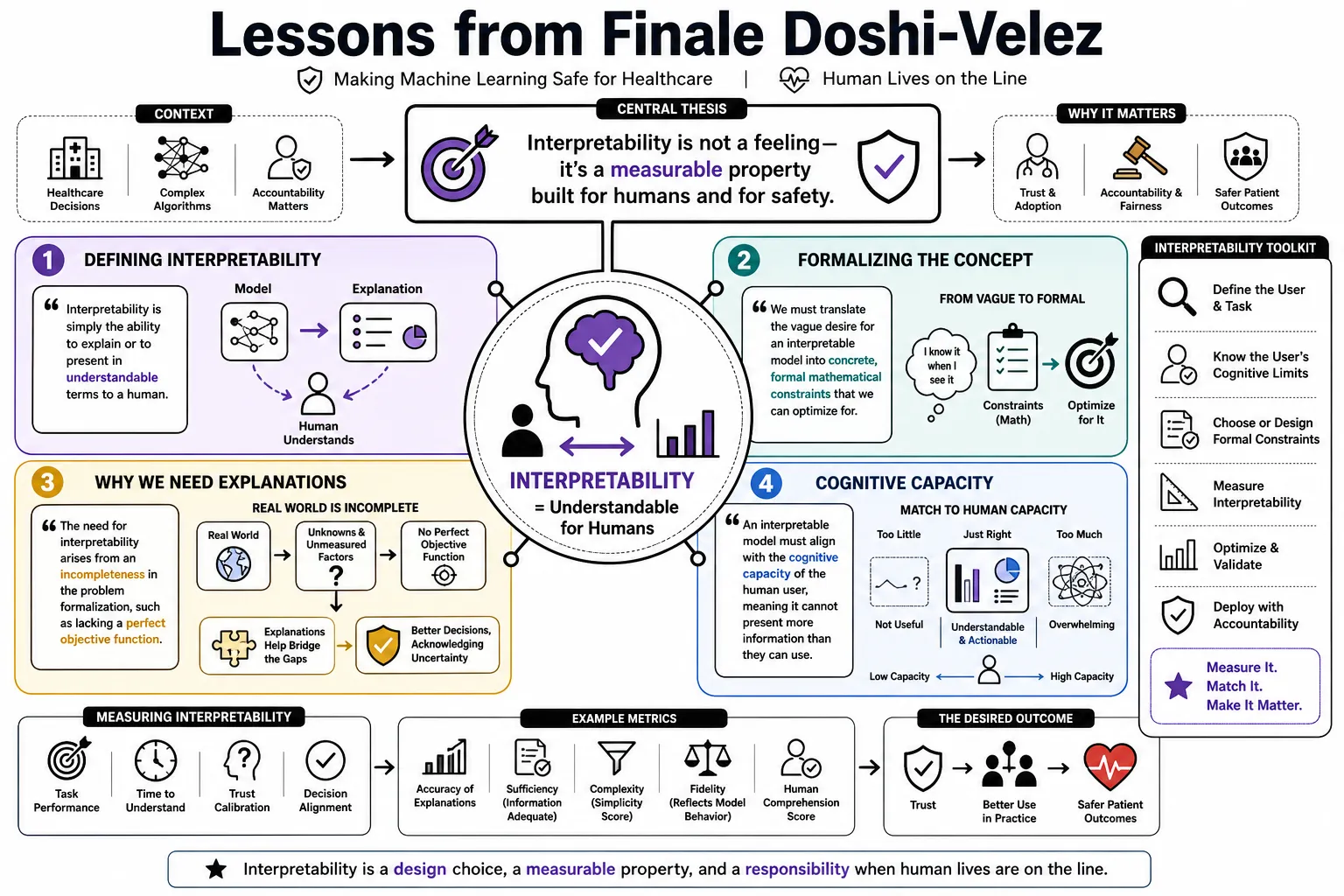
Part 1: Defining Interpretability
- On Interpretability: "Interpretability is simply the ability to explain or to present in understandable terms to a human." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On the Problem with 'Interpretability': "The field has historically treated interpretability as an 'I know it when I see it' concept rather than a testable scientific property." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Formalizing the Concept: "We must translate the vague desire for an interpretable model into concrete, formal mathematical constraints that we can optimize for." — Source: [Talks at Google]
- On Why We Need Explanations: "The need for interpretability arises from an incompleteness in the problem formalization, such as lacking a perfect objective function." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Cognitive Capacity: "An interpretable model must align with the cognitive capacity of the human user, meaning it cannot present more information than a person can process." — Source: [A Roadmap for the Rigorous Science of Interpretability]
- On Local vs Global Explanation: "There is a distinct difference between understanding how a model works as a whole and explaining why it made a specific decision for a single patient." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On the Accuracy Trade-off: "We often assume there is a strict trade-off between how accurate a model is and how interpretable it is, but well-designed models can often achieve both." — Source: [Talking Machines Podcast]
- On Concept-Based Models: "Building models around human-understandable concepts allows users to verify whether the system is relying on sensible logic." — Source: [Learning Interpretable Concept-Based Models with Human Feedback]
- On Defining the Audience: "An explanation is only useful if it is tailored to the background knowledge and goals of the specific person receiving it." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
Part 2: Rigorous Evaluation of AI
- On Application-Grounded Evaluation: "The truest test of an interpretable model is to put it in a real-world task with real domain experts and measure if their performance improves." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Human-Grounded Evaluation: "When real applications are too costly, we can test explanations on laypeople using simplified tasks that maintain the core essence of the problem." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Functionally-Grounded Evaluation: "We can use mathematical proxies like sparsity or monotonicity to evaluate models when human subject experiments are impossible." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On the Danger of False Proxies: "Optimizing for a mathematical definition of simplicity does not guarantee that the resulting model will actually make sense to a doctor." — Source: [A Roadmap for the Rigorous Science of Interpretability]
- On Baseline Comparisons: "Every new method for explainable AI needs to be compared against baseline models to prove it actually provides a tangible benefit to the user." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On the Value of Simplicity: "If a simple decision tree performs just as well as a deep neural network on a clinical dataset, the simple model should always be preferred." — Source: [Talking Machines Podcast]
- On Objective Metrics: "The field will only advance when we stop relying on anecdotal claims of interpretability and start using standardized, falsifiable evaluation metrics." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On User Testing: "An explanation that looks good to the computer scientist who built the model often fails when presented to the clinician who has to use it." — Source: [Talks at Google]
- On Validating Explanations: "We have to test whether the explanation provided by the AI actually matches the true causal mechanism of the underlying data." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
Part 3: Human-AI Interaction
- On Automation Bias: "When an AI system provides a confident explanation, humans are often too quick to trust it, even when the underlying recommendation is wrong." — Source: [Harvard University News]
- On Designing Feedback: "We need frameworks that allow humans to continuously update and correct the concepts an AI uses, rather than treating the model as a static artifact." — Source: [Learning Interpretable Concept-Based Models with Human Feedback]
- On the Cost of Bad Explanations: "A poorly designed explanation can actually decrease human performance by overwhelming them or misleading their intuition." — Source: [Harvard University News]
- On Human Intuition: "Machine learning should be used to augment clinical intuition by surfacing patterns in high-dimensional data that the human mind cannot easily track." — Source: [AI for Understanding Disease]
- On Collaborative Systems: "The ideal AI system acts as a collaborator that can be questioned and interrogated, rather than a black box handing down an oracle's verdict." — Source: [The Possibility of Explanation]
- On Incorporating Priors: "We can improve model safety by explicitly encoding human-in-the-loop interpretability priors directly into the training process." — Source: [Human-in-the-Loop Interpretability Prior]
- On Trust: "Trust is not built by merely showing high accuracy on a test set; it is built by demonstrating that the model's reasoning aligns with human logic." — Source: [Talks at Google]
- On Decision Support: "A decision support tool is only successful if it seamlessly integrates into the cognitive workflow of the expert using it." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Disagreement: "When the human and the AI disagree, the system must provide enough transparency for the human to determine where the AI's logic diverged from their own." — Source: [Talking Machines Podcast]
Part 4: AI in Healthcare and Medicine
- On the Potential of AI in Medicine: "The superpower of these AI systems is that they can look at large amounts of data and surface the right predictions at the right time." — Source: [Harvard SEAS Interview]
- On Clinical Workloads: "Clinicians regularly miss bits of information in the patient's history. Helping surface that information is a relatively low-hanging fruit." — Source: [Harvard SEAS Interview]
- On Healthcare Outcomes: "In the United States we spend more on healthcare and get worse outcomes than comparable countries. Data science can help address these systemic inefficiencies." — Source: [Women in Data Science Conference]
- On Unchecked Optimism: "We have to be wary of unchecked optimism in clinical AI. Algorithms that work in the lab frequently fail when deployed in chaotic hospital environments." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On the Role of Algorithms: "Algorithms will not replace doctors, but they will become essential tools for managing the overwhelming volume of patient data." — Source: [AI for Understanding Disease]
- On Deployment Realities: "A model that achieves state-of-the-art accuracy on the MIMIC-III dataset might still be clinically useless if it relies on lab values that take hours to process." — Source: [TalkRL Podcast]
- On Heterogeneous Data: "Medical data is inherently messy and high-dimensional. Building robust models requires understanding the context in which that data was recorded." — Source: [Harvard Data Science Initiative]
- On the Importance of Context: "A spike in heart rate means something very different if a patient is running on a treadmill versus lying asleep in an intensive care unit." — Source: [AI for Understanding Disease]
- On Actionable Knowledge: "Our goal is not just to predict disease progression, but to translate complex patient histories into actionable knowledge that changes treatment decisions." — Source: [Data to Actionable Knowledge Lab]
- On Clinical Validation: "No machine learning model should be integrated into clinical care without undergoing the same rigorous prospective validation we require for new drugs." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
Part 5: Reinforcement Learning and Treatment Planning
- On Long-term Strategies: "Reinforcement learning is uniquely suited for medicine because treating chronic diseases requires planning a sequence of actions over time, not just making a single diagnosis." — Source: [TalkRL Podcast]
- On Retrospective Data: "The central challenge of applying RL in healthcare is that we must learn safe policies entirely from retrospective, observational data without exploring on real patients." — Source: [TalkRL Podcast]
- On Reward Design: "Defining the correct reward function in clinical RL is incredibly difficult because patient health cannot be reduced to a single objective metric." — Source: [Robust Decision-Focused Learning for Reward Transfer]
- On Model-Based RL: "Using model-based reinforcement learning allows us to focus the algorithm on the clinical dynamics that are most relevant to achieving positive outcomes." — Source: [Robust Decision-Focused Learning for Reward Transfer]
- On Safety Constraints: "Any reinforcement learning policy deployed in a hospital must be bound by strict safety constraints to prevent it from suggesting lethal drug dosages." — Source: [TalkRL Podcast]
- On Evaluating Policies: "Off-policy evaluation is the most critical component of clinical RL. We have to know if a new treatment strategy is better before we ever try it on a human." — Source: [TalkRL Podcast]
- On Individualized Care: "RL provides a mathematical framework for individualized treatment planning, adapting the strategy as the patient's condition evolves." — Source: [Harvard SEAS News]
- On Sepsis Management: "Conditions like sepsis require rapid, sequential decision-making in the ICU, making them prime candidates for reinforcement learning optimization." — Source: [TalkRL Podcast]
- On Uncertainty in RL: "When an RL agent is uncertain about a patient's state, it should defer to the clinician rather than blindly executing a low-confidence action." — Source: [TalkRL Podcast]
- On Transfer Learning: "We must ensure that an RL policy trained on data from one hospital's ICU remains safe and effective when transferred to a different hospital." — Source: [Robust Decision-Focused Learning for Reward Transfer]
Part 6: Accountability and Trust
- On System Accountability: "We need explanations to hold AI systems accountable, ensuring they are not violating safety constraints or acting on discriminatory biases." — Source: [The Possibility of Explanation]
- On Right for the Right Reasons: "It is not enough for a model to be accurate; it must be right for the right reasons, relying on causal variables rather than spurious correlations." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Identifying Bias: "Interpretability tools are essential for auditing models to reveal when they are relying on protected attributes like race or gender to make decisions." — Source: [Talks at Google]
- On the Legal Context: "As AI enters domains like medicine and finance, the legal system will increasingly require systems to provide a trail of logic for liability purposes." — Source: [The Possibility of Explanation]
- On the Ethics of Black Boxes: "Deploying a black-box model in a high-stakes scenario without any means of interrogating its behavior is a fundamental failure of engineering ethics." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On Debugging Models: "Explanation is a powerful debugging tool, allowing engineers to identify when a model has learned a shortcut that will fail in the real world." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Building Reliance: "Proper reliance means a user knows exactly when to trust the AI's recommendation and exactly when to ignore it based on the patient's unique context." — Source: [Harvard University News]
- On Regulatory Standards: "The scientific community must help define the standards for algorithm transparency before regulators impose rules that are technically impossible to satisfy." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On Transparency Trade-offs: "Demanding full transparency can sometimes expose sensitive training data, requiring us to balance interpretability against privacy concerns." — Source: [Talking Machines Podcast]
- On the Burden of Proof: "The burden of proof lies with the developers to show that their AI system is robust, safe, and understandable before it enters the clinic." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
Part 7: Navigating Data and Model Limitations
- On Missing Variables: "Clinical data is highly confounded. If a model does not know that a doctor intervened, it might learn the exact wrong relationship between a drug and a symptom." — Source: [AI for Understanding Disease]
- On Informative Missingness: "In medical records, the absence of data is often highly informative. The fact that a doctor didn't order a test tells you something about the patient's apparent health." — Source: [Harvard Data Science Initiative]
- On Spurious Correlations: "Deep learning models are exceptional at finding shortcuts in data, which is why they often fail catastrophically when the underlying distribution shifts." — Source: [Towards A Rigorous Science of Interpretable Machine Learning]
- On Causal Inference: "We have to move beyond observational prediction and integrate causal inference if we want models that can reliably recommend treatments." — Source: [Data to Actionable Knowledge Lab]
- On Data Quality: "The performance of a clinical AI system is strictly bounded by the quality and representativeness of the electronic health records it was trained on." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On Algorithmic Fairness: "If the historical data reflects systemic biases in healthcare access, the machine learning model will implicitly learn to replicate those inequities." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On Overfitting to Hospitals: "A model trained to predict mortality at a research hospital might fail completely at a rural clinic due to differences in standard protocols." — Source: [Robust Decision-Focused Learning for Reward Transfer]
- On the Limits of Deep Learning: "Deep learning is not a panacea. For many structured clinical datasets, simpler statistical methods are more robust and far easier to audit." — Source: [Talking Machines Podcast]
- On Managing Uncertainty: "A safe AI system must be able to quantify its own uncertainty and communicate to the user when it is making a guess." — Source: [The Possibility of Explanation]
Part 8: The Future of Responsible ML
- On Interdisciplinary Research: "Building responsible AI requires computer scientists to work in close, equal partnerships with doctors, ethicists, and domain experts." — Source: [Harvard SEAS News]
- On Evolving Standards: "Our definitions of fairness, interpretability, and safety will evolve over time, meaning our models must be adaptable to changing societal values." — Source: [The Possibility of Explanation]
- On Practical Impact: "The ultimate measure of success for clinical machine learning is not publication in a top-tier venue, but a measurable improvement in patient outcomes." — Source: [Data to Actionable Knowledge Lab]
- On Continuous Monitoring: "AI systems in healthcare require continuous monitoring post-deployment to ensure their performance does not silently degrade as clinical practices change." — Source: [Do no harm: A roadmap for responsible machine learning for healthcare]
- On Bridging the Gap: "We need to bridge the gap between abstract machine learning theory and the messy, constrained reality of frontline medical care." — Source: [Women in Data Science Conference]
- On Designing for Humans: "The next frontier of AI research is not just building smarter algorithms, but designing interfaces that help humans interact with those algorithms effectively." — Source: [Talks at Google]
- On Realistic Expectations: "We need to set realistic expectations about what AI can do in medicine, focusing on pragmatic decision support rather than autonomous diagnosis." — Source: [AI for Understanding Disease]
- On Educational Needs: "Medical professionals need baseline training in data science concepts so they can critically evaluate the AI tools being integrated into their practice." — Source: [Harvard Data Science Initiative]
- On the Moral Imperative: "Because data science has the power to improve human health on a massive scale, we have a moral imperative to ensure we build these tools rigorously and safely." — Source: [The Possibility of Explanation]