Lessons from Ian Goodfellow
Ian Goodfellow invented Generative Adversarial Networks (GANs) and co-authored the standard deep learning textbook. He also found key security flaws in modern AI models. This collection covers his practical approach to machine learning and his read on algorithmic constraints, along with his advice for new researchers.
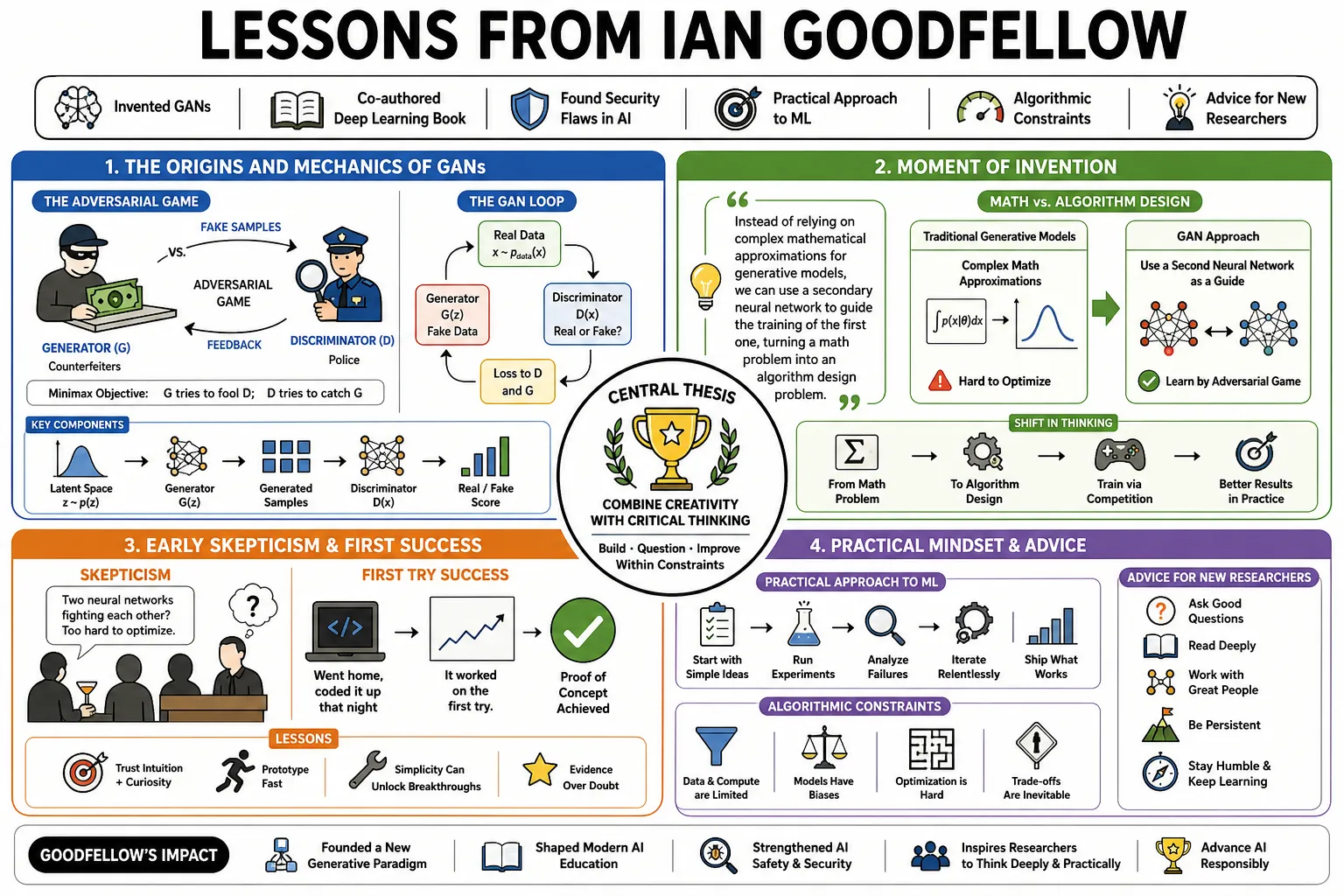
Part 1: The Origins and Mechanics of GANs
- On the adversarial game: "The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency." — Source: [Generative Adversarial Nets]
- On the moment of invention: "Instead of relying on complex mathematical approximations for generative models, we can use a secondary neural network to guide the training of the first one, turning a math problem into an algorithm design problem." — Source: [DeepLearning.AI Interview]
- On early skepticism: "When I first proposed the idea of having two neural networks fight each other to friends at a bar, they thought it wouldn't work because it seemed too difficult to optimize. I went home, coded it up that night, and it worked on the first try." — Source: [Lex Fridman Podcast]
- On the discriminator's role: "The discriminator acts as a dynamic loss function that updates itself as the generator improves, providing a much richer gradient signal than a static mathematical metric could." — Source: [NIPS 2016 Tutorial: GANs]
- On mode collapse: "A common failure mode in GANs occurs when the generator discovers a single output that easily fools the discriminator and continuously produces that one output, ignoring the rest of the data distribution." — Source: [NIPS 2016 Tutorial: GANs]
- On continuous improvement: "The competition in GANs drives both networks to improve their methods until the counterfeits are indistinguishable from the genuine articles." — Source: [Generative Adversarial Nets]
- On the limits of explicit density: "Before GANs, generative models struggled with the intractable summations required to explicitly define probability density functions over complex high-dimensional spaces like images." — Source: [Deep Learning Book]
- On maximum likelihood: "GANs can be viewed as an alternative to maximum likelihood estimation, one that bypasses the need for explicit probability distributions in favor of a sample-generation mechanism." — Source: [NIPS 2016 Tutorial: GANs]
- On Nash equilibrium: "The theoretical endpoint of a GAN is a Nash equilibrium where the generator perfectly captures the data distribution and the discriminator is left guessing at a 50 percent accuracy rate." — Source: [Generative Adversarial Nets]
- On generative modeling: "Generative modeling is a way of testing our understanding of the data. If we really understand something, we should be able to build it." — Source: [Lex Fridman Podcast]
Part 2: The Mathematical Foundations of Deep Learning
- On representation learning: "Deep learning allows computers to build complex concepts out of simpler concepts, removing the need for human engineers to formally specify all the knowledge the computer needs." — Source: [Deep Learning Book]
- On hierarchical abstraction: "A deep neural network understands the world through a hierarchy of layers, where early layers detect edges, middle layers detect shapes, and final layers detect objects." — Source: [Deep Learning Book]
- On linear algebra: "Linear algebra is the workhorse of deep learning, providing the mathematical language to efficiently compute and represent the massive parallel operations that neural networks require." — Source: [Deep Learning Book]
- On probability theory: "Because machine learning must always deal with uncertain quantities and stochastic, non-deterministic environments, probability theory is a fundamental requirement for designing modern AI." — Source: [Deep Learning Book]
- On objective functions: "The core of machine learning is defining a performance measure or cost function, and then using mathematical optimization to find the parameters that minimize this cost." — Source: [Deep Learning Book]
- On the bias-variance tradeoff: "A model must balance its capacity to memorize the training data with its ability to discover the true underlying rules of the task." — Source: [Deep Learning Book]
- On regularizing networks: "Regularization is any modification we make to a learning algorithm that is intended to reduce its generalization error but not its training error." — Source: [Deep Learning Book]
- On Occam's razor: "The principle that the simplest explanation is usually the best is mathematically formalized in deep learning through techniques like weight decay, which penalize overly complex models." — Source: [Deep Learning Book]
- On the curse of dimensionality: "As the number of variables in a dataset increases, the number of possible configurations grows exponentially, making traditional machine learning methods fail where deep learning succeeds." — Source: [Deep Learning Book]
- On numerical computation: "Deep learning relies heavily on numerical methods because the equations governing neural networks almost never have closed-form, analytical solutions." — Source: [Deep Learning Book]
Part 3: Adversarial Vulnerabilities and Security
- On model fragility: "Neural networks can be easily fooled by adding small, carefully constructed perturbations to an image, causing the network to misclassify it with high confidence." — Source: [Explaining and Harnessing Adversarial Examples]
- On the linearity hypothesis: "Contrary to popular belief, adversarial examples are not caused by highly non-linear behavior in deep networks, but rather by their overly linear responses in high-dimensional spaces." — Source: [Explaining and Harnessing Adversarial Examples]
- On the fast gradient sign method: "We can efficiently generate adversarial examples by simply taking a small step in the direction of the gradient that maximizes the model's error." — Source: [Explaining and Harnessing Adversarial Examples]
- On transferability: "An adversarial example designed to fool one specific neural network will often successfully fool a completely different neural network trained on a different subset of data." — Source: [Explaining and Harnessing Adversarial Examples]
- On adversarial training: "The best thing we can do is to actually train on adversarial examples themselves, constantly updating the model against attacks during the training process to build robustness." — Source: [Medium Profile]
- On security arms races: "Defending against adversarial attacks often turns into an arms race, where new defenses are quickly bypassed by slightly modified attack strategies." — Source: [Lex Fridman Podcast]
- On physical world attacks: "Adversarial examples are not just digital curiosities; they can exist in the physical world, such as modified stop signs that autonomous vehicles classify as speed limit signs." — Source: [Adversarial Examples in the Physical World]
- On the illusion of understanding: "When a model fails drastically on an adversarial example that a human can easily classify, it reveals that the model is relying on completely different features than human perception does." — Source: [Lex Fridman Podcast]
- On defending with scale: "Simply making a neural network larger or training it on more standard data does not automatically protect it from adversarial examples." — Source: [Explaining and Harnessing Adversarial Examples]
- On the necessity of failure: "Studying how models break under adversarial conditions is one of the most effective ways to understand their internal mechanisms and fundamental limitations." — Source: [NIPS 2017 Keynote]
Part 4: Scaling, Compute, and Model Growth
- On data milestones: "A rough rule of thumb is that a supervised deep learning algorithm will generally achieve acceptable performance with around 5,000 labeled examples per category." — Source: [Deep Learning Book]
- On human-level performance: "To match or exceed human performance across complex tasks, supervised deep learning algorithms typically require datasets containing at least 10 million labeled examples." — Source: [Deep Learning Book]
- On why he abandoned SVMs: "It was obvious to me right away that deep learning would fix a lot of my complaints about SVMs. SVMs don't give you a lot of freedom to design the model. But deep neural nets tend to get better as they get bigger." — Source: [Medium Profile]
- On computational constraints: "Many of the core algorithms in deep learning existed for decades, but they only became practical when hardware, specifically GPUs, became powerful enough to run them at scale." — Source: [Deep Learning Book]
- On the limits of scale: "While scaling up networks and data reliably improves performance, it does not automatically solve structural issues like causal reasoning or adversarial vulnerability." — Source: [Lex Fridman Podcast]
- On memory limits and innovation: "The invention of GANs was partially driven by the severe memory constraints of early GPUs, forcing the search for a method that bypassed explicit probability calculations." — Source: [DeepLearning.AI Interview]
- On dataset bias: "As models scale to ingest massive portions of the internet, they inevitably absorb and amplify the biases present in that data, shifting the challenge from model capacity to data curation." — Source: [Deep Learning Book]
- On compute as a driver: "The timeline of AI breakthroughs maps closely onto the timeline of available computing power, suggesting that hardware progress is as critical as algorithmic progress." — Source: [Lex Fridman Podcast]
- On distributed training: "As models grow beyond the capacity of a single machine, learning to efficiently distribute the training process across multiple GPUs becomes a fundamental skill for researchers." — Source: [Deep Learning Book]
Part 5: Optimization and Training Realities
- On optimization vs. learning: "Optimization refers to the task of either minimizing or maximizing some function. Learning is different from pure optimization in that we want to minimize the generalization error, not just the training error." — Source: [Deep Learning Book]
- On gradient descent: "The foundation of training deep models is backpropagation and stochastic gradient descent, simple algorithms that scale astonishingly well to billions of parameters." — Source: [Deep Learning Book]
- On local minima: "While early researchers feared that neural networks would get stuck in bad local minima, in practice, high-dimensional spaces contain many good local minima that yield excellent performance." — Source: [Deep Learning Book]
- On learning rates: "Setting the learning rate is often the most critical hyperparameter choice; if it is too high, the loss diverges, and if it is too low, the model takes too long to learn or gets stuck." — Source: [Deep Learning Book]
- On batch normalization: "Techniques that smooth the optimization landscape, like batch normalization, are often what transform a theoretically sound architecture into a model that can actually be trained in practice." — Source: [Deep Learning Book]
- On saddle points: "In deep neural networks, saddle points are far more common than bad local minima, and modern optimization algorithms are designed to escape them quickly." — Source: [Deep Learning Book]
- On hyperparameter tuning: "Finding the right architecture and training settings is still largely an empirical science requiring intuition, trial, and error, rather than purely theoretical derivation." — Source: [Deep Learning Book]
- On the non-convex landscape: "Deep learning relies on non-convex optimization, meaning there are no mathematical guarantees of finding the absolute best solution, yet empirical results show it works consistently well." — Source: [Deep Learning Book]
- On early stopping: "One of the most effective and widely used forms of regularization is simply stopping the training process as soon as the validation error begins to increase." — Source: [Deep Learning Book]
Part 6: Practical Advice for ML Researchers
- On getting noticed: "One way that you could get a lot of attention is to write good code and put it on Github. If you have an interesting project that solves a problem that someone working at a top lab wanted to solve, they'll find you." — Source: [DeepLearning.AI Interview]
- On open source: "Contributing to open-source libraries like TensorFlow or PyTorch is often a better resume builder for young researchers than traditional academic credentials." — Source: [DeepLearning.AI Interview]
- On choosing a path: "The hardest problem facing someone entering AI today is not a lack of resources, but choosing which of the many viable paths and subfields to focus on." — Source: [YouTube Interview]
- On reading papers: "Instead of trying to understand every equation on the first read, researchers should take a multi-pass approach: get the high-level concept first, then drill down into the math later." — Source: [Silicon Tutor]
- On core technologies: "Working on foundational architectures and core algorithms is often a faster path to having a broad impact than building specific, narrow applications." — Source: [DeepLearning.AI Interview]
- On implementation: "True understanding in machine learning comes from implementing the algorithms from scratch; theoretical knowledge often breaks down when faced with practical debugging." — Source: [Deep Learning Book]
- On debugging models: "When a neural network fails to learn, the problem is rarely the core math; it is usually an issue with data preprocessing, label alignment, or a silent bug in the training loop." — Source: [Deep Learning Book]
- On game programming: "My background as a hobbyist game programmer helped build intuition for complex, highly parallel systems, an experience that was foundational for my work in deep learning." — Source: [Medium Profile]
- On collaborating: "Machine learning moves too fast for lone-wolf researchers; breakthroughs often happen in collaborative environments where ideas are shared openly and critiqued quickly." — Source: [Lex Fridman Podcast]
Part 7: AI Timelines, Safety, and the Future
- On AI hype: "Machine learning is simultaneously underhyped by the general public who don't grasp its economic impact, and incorrectly hyped by media that exaggerate how close we are to human-level reasoning." — Source: [Medium Profile]
- On AI safety: "We cannot assume that AI systems will naturally align with human values; ensuring models are robust against adversarial attacks is a prerequisite for deploying them safely in critical infrastructure." — Source: [Lex Fridman Podcast]
- On reinforcement learning: "The integration of deep learning with reinforcement learning is one of the most promising avenues for expanding AI from passive perception to active decision-making." — Source: [Future of Life Institute]
- On autonomous agents: "For AI to truly advance, agents must learn to generalize their capabilities across diverse, open-ended environments rather than just mastering narrow, single-task domains." — Source: [Lex Fridman Podcast]
- On deepfakes: "While GANs enabled the creation of highly realistic synthetic media, the solution to misinformation lies not in halting AI research, but in developing better detection systems and digital provenance tools." — Source: [Lex Fridman Podcast]
- On job displacement: "The economic impact of AI will be profound, and society needs to proactively address the transition for workers whose tasks are automated by sophisticated deep learning systems." — Source: [Lex Fridman Podcast]
- On malicious use: "The vulnerability of neural networks to adversarial examples presents a tangible security threat if bad actors attempt to subvert medical, financial, or autonomous driving systems." — Source: [Explaining and Harnessing Adversarial Examples]
- On verification: "We need to move beyond empirical testing and develop methods to formally verify the behavior of neural networks, proving they will not act catastrophically in edge cases." — Source: [NIPS 2017 Keynote]
- On AGI timelines: "Predictions about the arrival of Artificial General Intelligence are highly uncertain, but the rapid scaling of current architectures suggests we should prepare for highly capable systems sooner rather than later." — Source: [Lex Fridman Podcast]
Part 8: The Philosophy of Artificial Intelligence
- On human perception: "Studying adversarial examples forces us to admit that human perception is highly specialized and not the only, or necessarily the most objective, way to process visual information." — Source: [Lex Fridman Podcast]
- On the nature of creativity: "Generative models challenge the idea that creativity is exclusively human, demonstrating that novel, realistic outputs can emerge from purely mathematical optimization." — Source: [Lex Fridman Podcast]
- On intelligence as optimization: "Much of what we consider intelligent behavior can be framed as a system optimizing a complex reward function within a constrained environment." — Source: [Deep Learning Book]
- On serendipity in science: "The invention of GANs, an idea formulated during a casual argument at a bar, proves that scientific breakthroughs often rely on unstructured creativity as much as deliberate lab work." — Source: [DeepLearning.AI Interview]
- On near-death experiences: "A severe medical emergency during my PhD studies clarified my priorities, confirming that AI research was the singular pursuit I wanted to dedicate my life to." — Source: [Reddit AMA]
- On the "magic" of AI: "When a deep network learns a complex task, it can seem like magic, but unpacking the math reveals a mechanical, predictable process of gradients and weights." — Source: [Deep Learning Book]
- On open science: "The rapid progress of deep learning over the last decade is a direct result of the culture of open-source code and freely published pre-prints on platforms like arXiv." — Source: [Lex Fridman Podcast]
- On biological inspiration: "While early neural networks were inspired by the brain, modern deep learning has diverged significantly, proving that artificial systems do not need to perfectly mimic biology to be effective." — Source: [Deep Learning Book]
- On the ultimate goal: "The end goal of deep learning research is not just to build better tools, but to mathematically uncover the fundamental principles of learning and intelligence itself." — Source: [Deep Learning Book]