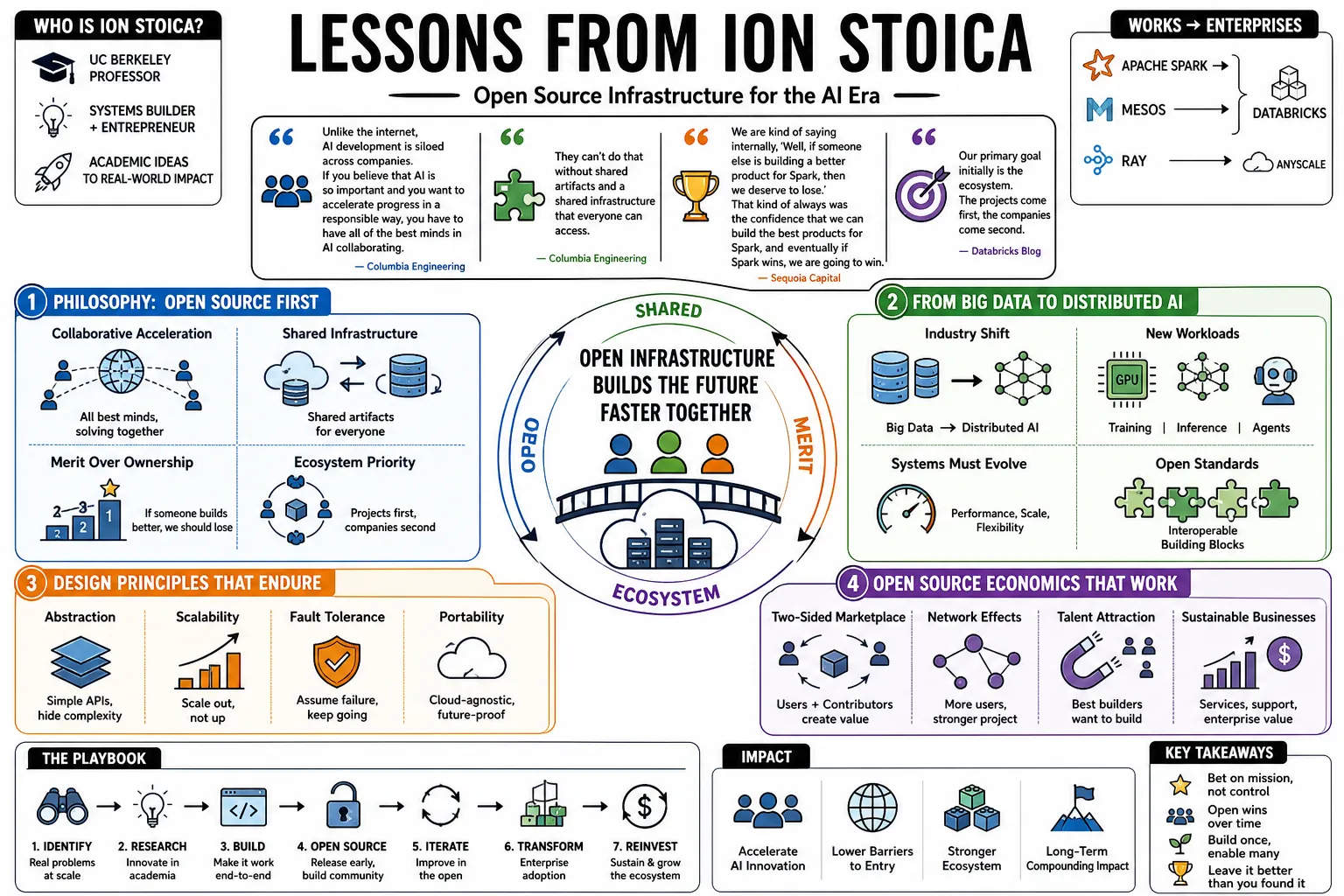
Lessons from Ion Stoica
Ion Stoica is a UC Berkeley professor who co-created Apache Spark, Mesos, and Ray, then co-founded Databricks and Anyscale to turn those academic projects into commercial enterprises. These notes track his approach to infrastructure design and open-source economics as the industry shifts from big data to distributed AI.
Part 1: The Philosophy of Open Source
- On collaborative acceleration: "Unlike the internet, AI development is siloed across companies. If you believe that AI is so important and you want to accelerate progress in a responsible way, you have to have all of the best minds in AI collaborating." — Source: Columbia Engineering
- On the necessity of shared infrastructure: "They can't do that without shared artifacts and a shared infrastructure that everyone can access." — Source: Columbia Engineering
- On winning by merit: "We are kind of saying internally, 'Well, if someone else is building a better product for Spark, then we deserve to lose.' That kind of always was the confidence that we can build the best products for Spark, and eventually if Spark wins, we are going to win." — Source: Sequoia Capital
- On ecosystem priority: "Our primary goal initially wasn't to make money; it was to make sure Spark became the de-facto standard for big data processing. You have to win the ecosystem first." — Source: Databricks Blog
- On the maintenance burden: "Open source is not free. Creating it is hard, but maintaining it as the user base scales is an entirely different engineering challenge that requires dedicated capital." — Source: a16z Podcast
- On standardizing APIs: "The winner in infrastructure is rarely the fastest engine; it is the engine that successfully standardizes the API layer for developers." — Source: Spark Summit
- On managing contributions: "You want community contributions, but you also have to protect the core architecture. If you accept every feature request, the system collapses under its own complexity." — Source: RISELab Archive
- On commercial models: "The service model is the only proven way to sustain a massive open-source project. You give away the engine, but you charge for the operational peace of mind." — Source: Foundation Capital
- On developer trust: "Developers adopt open source because they don't want to be locked in. If you betray that trust by crippling the open-source version, you lose the ecosystem." — Source: Anyscale Blog
Part 2: Distributed Systems & Big Data
- On the developer gap: "Writing distributed applications is hard. And now if more and more applications are going to become distributed, there is an increased gap between the desire of people to scale up their workload... and the expertise the typical programmer has." — Source: Weights & Biases
- On memory versus disk: "Spark succeeded because it recognized that memory was getting cheaper. We shifted the bottleneck from disk I/O to network and CPU by keeping data in memory across iterations." — Source: AMPLab Papers
- On lineage for fault tolerance: "Instead of replicating data across nodes like MapReduce, we tracked the lineage of the data. If a node fails, you just recompute that specific partition. It is much faster and cheaper." — Source: USENIX NSDI
- On the limits of MapReduce: "MapReduce was great for single-pass jobs, but machine learning requires running the same algorithm over the data hundreds of times. Writing to disk after every pass was killing performance." — Source: Databricks Origins
- On scheduling frameworks: "Mesos was born from the realization that we needed a way to share cluster resources efficiently across different compute frameworks, rather than statically partitioning the hardware." — Source: ACM Queue
- On hiding complexity: "A good distributed system makes a cluster of machines feel like a single laptop to the developer." — Source: Ray Summit
- On data gravity: "Moving data is expensive. You always want to bring the compute to the data, not the other way around." — Source: Spark Architecture Papers
- On stateful computation: "The next frontier after batch processing was stateful stream processing. Systems had to maintain state across streams without losing fault tolerance." — Source: RISELab Archive
- On bottlenecks: "In distributed systems, the bottleneck always moves. Once you optimize storage, the network breaks. Once you fix the network, the CPU is maxed out." — Source: USENIX ATC
Part 3: The Rise of AI Infrastructure
- On Python's dominance: "Python won the data science ecosystem. We had to build Ray so that Python developers could distribute their code without having to learn Java or C++." — Source: Anyscale Blog
- On the "infinite laptop": "We wanted Ray to provide the experience of an infinite laptop. You write your Python script locally, and it seamlessly scales to thousands of cores in the cloud." — Source: Weights & Biases
- On general-purpose AI compute: "Spark was built for bulk synchronous processing. AI needs heterogeneous, asynchronous task execution. That is why Ray had to be a completely new architecture." — Source: Ray Paper (OSDI)
- On LLM scale: "No single machine can train a modern Large Language Model. Distributed computing is no longer an option for AI; it is a hard prerequisite." — Source: Sequoia Capital
- On OpenAI's adoption: "When OpenAI chose Ray to train ChatGPT, it validated our hypothesis that the most advanced AI models would require a flexible, distributed execution engine." — Source: Anyscale Origins
- On engineering-grade AI: "We need to move AI from a black-box science experiment to engineering-grade systems with predictable performance and reliability." — Source: Columbia Engineering
- On hardware utilization: "GPUs are too expensive to leave idle. AI infrastructure must maximize hardware utilization through aggressive pipelining and efficient scheduling." — Source: Ray Summit
- On training versus inference: "Training requires massive batch processing and fault tolerance; inference requires ultra-low latency and dynamic scaling. A unified system has to handle both extremes." — Source: Anyscale Blog
- On the AI ecosystem: "The pace of AI is too fast for monolithic systems. You need a modular infrastructure where people can plug in new algorithms and hardware backends daily." — Source: Foundation Capital
Part 4: Sky Computing & The Future of Cloud
- On defining Sky Computing: "Sky Computing is the next logical step. It envisions the cloud evolving into a commodity utility, much like the Internet or the electrical grid." — Source: Sky Computing Paper
- On cloud walled gardens: "Currently, cloud providers act as walled gardens. They trap your data with proprietary APIs and high egress fees, locking you into their specific ecosystem." — Source: USENIX NSDI
- On the egress fee problem: "The transition to Sky Computing is an economic challenge, not just a technical one. Data egress fees are the primary barrier preventing multi-cloud mobility." — Source: a16z Podcast
- On the cloud of clouds: "We need a compatibility layer—a cloud of clouds—that allows applications to run across multiple providers seamlessly." — Source: UC Berkeley Sky Lab
- On automated routing: "In the Sky Computing model, you don't choose AWS or GCP. The system automatically routes your workload to the provider with the best price, performance, or available GPUs at that exact moment." — Source: SkyPilot Documentation
- On the internet parallel: "In the early days of networking, isolated corporate networks couldn't talk to each other. The Internet Protocol solved that. We need an IP equivalent for cloud computing." — Source: USENIX NSDI
- On market forces: "If history is a guide, market forces will eventually push cloud compute toward commoditization, forcing providers to compete on cost and hardware rather than lock-in." — Source: Sky Computing Paper
- On capacity constraints: "With the GPU shortage, no single cloud has enough hardware. Sky Computing lets you stitch together idle GPUs across multiple regions and providers to get your job done." — Source: Anyscale Blog
- On open standards: "For the Sky to work, we need open standards for identity, billing, and resource provisioning across independent cloud boundaries." — Source: UC Berkeley Sky Lab
- On enterprise leverage: "When workloads become portable, enterprises regain their negotiating leverage with cloud vendors." — Source: a16z Podcast
Part 5: Startup Strategy & Commercialization
- On identifying markets: "You want to solve a problem ideally, which is going to be more important tomorrow than today." — Source: Sequoia Capital
- On the transition from lab to company: "Academic software proves the concept. Commercial software has to answer the pager at 3 AM. The leap between the two requires completely rebuilding the core." — Source: Databricks Founders
- On competing with incumbents: "We knew AWS would offer their own version of Spark. Our strategy was simply to be the absolute best place to run Spark, offering optimizations and integrations they couldn't match." — Source: Foundation Capital
- On product focus: "Initially, we tried to build too many tools around Spark. We had to realize that our core value was the managed platform itself—making it invisible and easy to use." — Source: Databricks Blog
- On open-source monetization: "You don't charge for the code. You charge for the security, the integration, the uptime, and the ease of use. That is what enterprises actually buy." — Source: Sequoia Capital
- On founders scaling: "As a founder, your job changes every six months. If you are doing the same things today that you were doing a year ago, you are bottlenecking your company." — Source: Foundation Capital
- On Anyscale's specific mission: "Anyscale was created because we saw developers spending 80% of their time building cluster management tools just to run their AI models. We wanted to eliminate that overhead." — Source: Anyscale Origins
- On platform unification: "Customers don't want a data warehouse and a separate AI platform. They want a unified system where their data and their models live together." — Source: Databricks Spark Summit
- On customer pain points: "Engineers love building distributed systems. Customers hate managing them. Build the system, but sell the management." — Source: RISELab Archive
- On timing: "Spark caught the exact moment when enterprise data outgrew traditional databases, and memory prices dropped. Timing the hardware cycle is critical." — Source: AMPLab Papers
Part 6: Academic Research & Lab Models
- On the 5-year cycle: "At Berkeley, we use a 5-year lab model. It forces us to pick a massive, ambitious problem, solve it, and then explicitly shut the lab down. It prevents intellectual stagnation." — Source: UC Berkeley CS
- On multidisciplinary work: "The AMPLab was successful because it forced algorithms people, machine learning people, and systems people into the same room. You can't solve big data in isolation." — Source: AMPLab Papers
- On picking ideas: "Academia's job is to pursue non-consensus ideas. If an idea is obviously profitable today, a startup or big tech company is already doing it." — Source: USENIX Keynote
- On student autonomy: "You hire brilliant PhD students and you give them the freedom to pivot. Spark wasn't the original grant proposal; it was a side project that gained traction." — Source: Databricks Origins
- On industry feedback: "Our labs work closely with industry sponsors, not for funding, but for reality checks. We need to know what problems scale actually creates in the real world." — Source: RISELab Archive
- On publishing vs. impact: "Writing a paper is easy. Building a system that thousands of people actually download and run is how you prove your research has merit." — Source: ACM SIGCOMM
- On prototyping: "A research prototype only has to work once for the paper. But open-sourcing a prototype forces the lab to write better code from day one." — Source: UC Berkeley CS
- On the role of universities: "Universities are the last neutral ground where researchers can build foundational infrastructure without worrying about quarterly revenue targets." — Source: Columbia Engineering
- On long-term vision: "In a 5-year lab, the first year is chaos, the middle three are execution, and the last year is commercialization and spin-offs." — Source: AMPLab Retrospective
Part 7: Engineering Mindset & Problem Solving
- On active problem solving: "We are good at solving problems… when you have a failure, look at it as a problem to solve. It puts us in an active mode." — Source: CS Immigrant Interview
- On managing expectations: "It has to deal with your own expectations… the difference between reality and expectations. If you have very low expectations (of yourself), you're going to have fewer rejections." — Source: CS Immigrant Interview
- On simplicity: "The most elegant system is not the one with the most features; it is the one that achieves scale with the fewest architectural concepts." — Source: Spark Architecture Papers
- On technical debt: "You can take on technical debt to hit a deadline, but in distributed systems, debt compounds exponentially. A bad abstraction at the network layer will eventually crash the whole application." — Source: Ray Summit
- On testing at scale: "You cannot mathematically prove that a large distributed system works. You have to test it in production environments by actively injecting failures." — Source: USENIX ATC
- On debugging: "Debugging a distributed system is like solving a murder mystery where the evidence disappears every three seconds. You need deterministic logging from day one." — Source: RISELab Archive
- On API design: "APIs should be highly opinionated. If you give developers too many configuration knobs, they will inevitably misconfigure the cluster." — Source: Spark Summit
- On measuring performance: "Never trust a micro-benchmark. The only performance metric that matters is how long it takes a user to complete their actual end-to-end workload." — Source: ACM SIGCOMM
- On user empathy: "Engineers often build for other engineers. You have to force yourself to watch a data scientist struggle with your tool to realize how bad your UX actually is." — Source: Weights & Biases
- On iteration speed: "The primary advantage of Spark over Hadoop was that it allowed data scientists to iterate quickly. Speed of thought is a feature." — Source: Databricks Origins
Part 8: Security, Economics, & The Next Era
- On system security: "Security is always a difficult topic. It means so many things to so many people, and in distributed systems, the attack surface is effectively infinite." — Source: Spark Summit East
- On cost as a constraint: "We have reached a point where the cost of compute is the primary constraint on AI capability. Engineering efficiency is now a financial imperative." — Source: Anyscale Blog
- On the future of the internet: "Early on, we worked on Chord and peer-to-peer networks. That decentralized ethos still informs how we think about breaking up cloud monopolies today." — Source: MIT Chord Project
- On data lock-in: "Compute is becoming stateless and portable, but data has gravity. The next major battleground is who controls the data formats and storage layers." — Source: Sky Computing Paper
- On open-source economics: "If you build an open-source tool that saves companies millions, but you don't capture any of that value, your project will eventually starve to death." — Source: Foundation Capital
- On AI safety and infrastructure: "You cannot enforce AI safety policies if the underlying infrastructure is opaque. Transparency at the system level is required for safe AI." — Source: Columbia Engineering
- On network limits: "As GPUs get faster, the network is becoming the bottleneck again. We are spending more time waiting for gradients to sync than actually computing them." — Source: Ray Paper (OSDI)
- On the legacy of DHTs: "Distributed Hash Tables taught us how to find data without a central coordinator. That mathematical elegance is still embedded in modern scheduling algorithms." — Source: ACM SIGCOMM
- On the future of software engineering: "In the future, developers won't write distributed systems. They will write sequential logic, and compilers like Ray and Sky will distribute it automatically across the globe." — Source: UC Berkeley Sky Lab