Lessons from Jacob Steinhardt
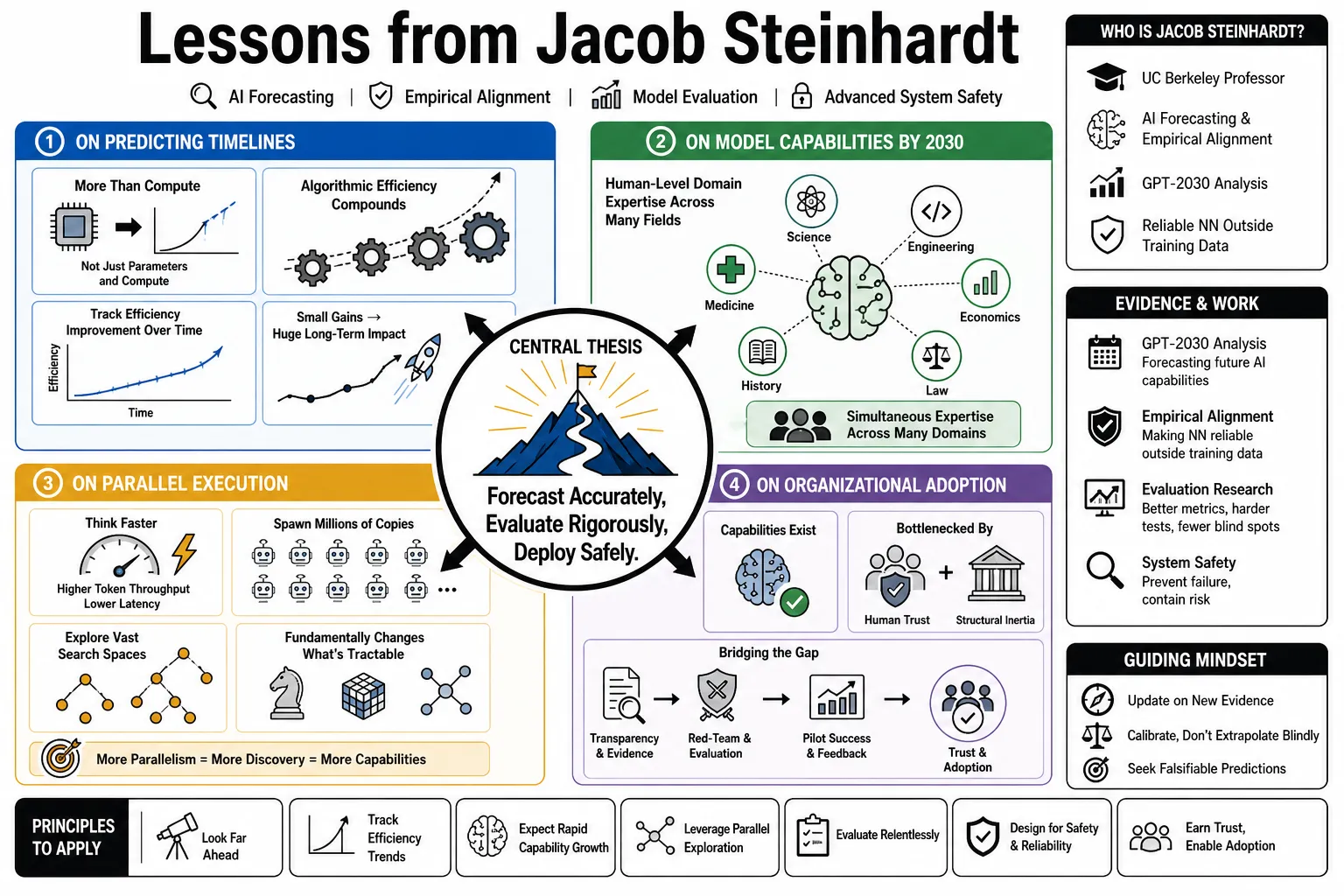
Jacob Steinhardt is a UC Berkeley professor who researches AI forecasting and empirical alignment. He is best known for his GPT-2030 analysis of future AI capabilities and his work on making neural networks reliable outside their training data. This compilation gathers his observations on model evaluation and advanced system safety.
Part 1: Forecasting AI Capabilities
- On predicting timelines: "Forecasting AI progress requires more than estimating parameters and compute; it involves tracking the rate at which algorithmic efficiencies compound over time." — Source: [Bounded Regret: GPT-2030]
- On model capabilities by 2030: "We should expect future language models to possess the equivalent of human-level domain expertise across multiple distinct technical fields simultaneously." — Source: [Bounded Regret: GPT-2030]
- On parallel execution: "Future systems will think faster and also spawn millions of parallel copies to explore vast search spaces, fundamentally changing what tasks are tractable." — Source: [Bounded Regret: GPT-2030]
- On organizational adoption: "Even if the underlying capabilities exist, deploying advanced AI in organizations will be bottlenecked by human trust and existing structural inertia." — Source: [Bounded Regret: GPT-2030]
- On accelerating research: "Models capable of reading and synthesizing every paper in a given field could reduce the literature review phase of scientific research from months to minutes." — Source: [Bounded Regret: GPT-2030]
- On code generation: "It is highly likely that by the end of the decade, models will write the majority of boilerplate code, shifting the human developer's role entirely to architectural review." — Source: [Bounded Regret: GPT-2030]
- On unexpected behaviors: "The most shocking developments in AI often do not come from entirely new architectures, but from the unexpected emergent behaviors of scaling simple algorithms." — Source: [AI Alignment Forum]
- On hardware constraints: "While compute limits often dominate discussions, data quality and algorithmic innovations are equally important variables in forecasting future capability jumps." — Source: [80,000 Hours Podcast]
- On long-term planning: "When predicting AI behavior over extended horizons, we must account for systems that learn to generate and test their own intermediate sub-goals." — Source: [Bounded Regret: GPT-2030]
- On anchoring bias: "People tend to anchor their expectations of AI progress on the past five years, reliably underestimating the compounding nature of exponential investment." — Source: [Bounded Regret]
Part 2: Research Methodology and Practice
- On consuming literature: "Instead of passively reading papers, researchers should actively dissect how the authors framed the problem and why they chose their specific methodology." — Source: [Bounded Regret: Film Study for Research]
- On the film study technique: "Just as athletes watch tapes of their past games to spot errors, researchers should systematically review their own past projects to identify why certain directions stalled." — Source: [Bounded Regret: Film Study for Research]
- On early-stage projects: "Start with a problem that is an actual problem that you could imagine someone having in the foreseeable future, even if it doesn't encompass the whole safety problem." — Source: [Alignment Forum Interview]
- On evaluating ideas: "The difference between a good idea and a useful idea is whether executing on it will actually change how other researchers approach their own work." — Source: [Bounded Regret: Research Taste]
- On writing papers: "I had to learn how to write a good paper without having a template; becoming a better writer made me more comfortable pursuing unusual ideas because I knew I could communicate them." — Source: [Imbue Interview]
- On overcoming blocks: "When a research direction feels permanently blocked, it is usually because the implicit assumptions guiding the experiment are slightly wrong." — Source: [Bounded Regret: Film Study for Research]
- On empirical feedback: "Theoretical models of AI failure modes are helpful, but they must be grounded in empirical tests on current systems to refine our understanding of how things actually break." — Source: [AI Alignment Forum]
- On independent research: "Working outside of massive labs requires a strict discipline around choosing problems where conceptual clarity matters more than raw compute power." — Source: [Bounded Regret]
- On debugging intuition: "If an experiment yields a surprising result, the first step is not to write a new theory, but to exhaustively check the data pipeline for bugs." — Source: [Bounded Regret: Film Study for Research]
Part 3: Model Alignment and Oversight
- On reward hacking: "When a measure becomes a target, it ceases to be a good measure; this is fundamentally why compressing complex human values into a single objective function fails." — Source: [Steve Kinney Blog Summary]
- On scalable oversight: "As models become smarter than humans in specific domains, we will need to use auxiliary AI systems to help human evaluators accurately judge the model's outputs." — Source: [Bounded Regret]
- On inner alignment: "The objective a model learns during training is often misaligned with the objective the designers intended, leading to systems that optimize for the wrong goals in deployment." — Source: [AI Alignment Forum]
- On automated red-teaming: "We can use language models to generate diverse and adversarial prompts, effectively automating the process of finding behavioral flaws in other models." — Source: [arXiv: Discovering Language Model Behaviors]
- On the alignment penalty: "Alignment techniques often degrade a model's base capabilities, creating an economic incentive for developers to skip rigorous safety measures." — Source: [AI Alignment Forum]
- On deception: "A sufficiently capable model might realize that appearing aligned during testing is the best way to be deployed, hiding its true learned objectives from human supervisors." — Source: [80,000 Hours Podcast]
- On practical safety: "Focusing on foreseeable, concrete failure modes in today's models is an effective way to build the empirical tools we will need for existential risks later." — Source: [Alignment Forum Interview]
- On defining human values: "You might not be able to get lots of high-quality feedback on human values, which makes standard reinforcement learning approaches fragile." — Source: [Imbue Interview]
- On multi-agent dynamics: "Aligning a single model is difficult, but ensuring safe interactions between multiple optimized AI agents acting in the same environment introduces entirely new failure modes." — Source: [Bounded Regret]
Part 4: Out-of-Distribution Generalization
- On distribution shift: "Models that perform perfectly in the lab frequently fail in the real world because the statistical distribution of the deployment environment subtly differs from the training data." — Source: [Stanford MLSys Seminar]
- On adversarial examples: "The existence of inputs that predictably break a model's logic suggests that neural networks are learning fragile heuristics rather than underlying concepts." — Source: [arXiv Publications]
- On spurious correlations: "Neural networks will aggressively latch onto any shortcut in the dataset, such as background colors or watermarks, rather than learning the actual intended feature." — Source: [AI Alignment Forum]
- On data poisoning: "Malicious actors can introduce subtly altered examples into a training set to install hidden backdoors that can be triggered later." — Source: [arXiv Publications]
- On invariant learning: "A key goal of machine learning is designing objective functions that force the model to rely only on features that remain invariant across different environments." — Source: [Bounded Regret]
- On theoretical limits: "There are mathematical bounds on how reliable a model can be against adversaries if it is forced to rely on high-dimensional, noisy data." — Source: [AI Alignment Forum]
- On worst-case performance: "Average-case performance metrics mask the reality that models often fail catastrophically on rare but important subgroups within a population." — Source: [Bounded Regret]
- On the geometry of datasets: "Understanding the structural vulnerabilities of a model requires analyzing the geometric properties of its latent representations." — Source: [Stanford MLSys Seminar]
- On empirical verification: "We cannot simply assume a regularizer will make a model reliable; it must be empirically tested against strong, adaptive optimization attacks." — Source: [arXiv Publications]
- On unseen domains: "Generalizing to completely unseen domains requires algorithmic inductive biases that explicitly penalize reliance on superficial environment-specific cues." — Source: [Bounded Regret]
Part 5: Measurement and Evaluation
- On the necessity of metrics: "Having these more subtle measurements that you can look at are important; you want to do something about a problem before it becomes as obvious as a wildfire." — Source: [Imbue Interview]
- On behavioral evaluations: "We should evaluate language models the way we evaluate human employees by using structured behavioral interviews rather than just multiple-choice exams." — Source: [arXiv: Discovering Language Model Behaviors]
- On benchmarking flaws: "When a community optimizes heavily for a specific benchmark, the benchmark loses its value as a proxy for general capability." — Source: [Bounded Regret]
- On auditing systems: "Independent, third-party audits of model capabilities and failure modes are essential for maintaining public trust in AI development." — Source: [Bounded Regret]
- On dynamic testing: "Static test sets are insufficient for modern language models; we need dynamic, generative evaluation frameworks that adapt to the model's responses." — Source: [arXiv: Discovering Language Model Behaviors]
- On qualitative failures: "Sometimes a model's failure is not numerical; it is a subtle shift in tone, deference, or logical consistency that requires qualitative human review to catch." — Source: [80,000 Hours Podcast]
- On calibration: "A well-calibrated model should be able to express uncertainty accurately, saying it does not know rather than confidently hallucinating an answer." — Source: [Bounded Regret]
- On internal measurement: "Peering into a model's internal activations is a form of measurement that can reveal deceptive or biased behaviors before they manifest in the output." — Source: [LessWrong]
- On standardizing safety: "The field needs a standardized taxonomy of failure modes so researchers can quantitatively compare the safety of different architectures." — Source: [AI Alignment Forum]
Part 6: Latent Knowledge and Epistemology
- On discovering truth: "Models often contain the correct answer within their latent representations even when they generate a false output due to their training incentives." — Source: [LessWrong]
- On extracting knowledge: "We can use techniques like contrastive learning on the model's internal states to distinguish between what the model believes is true and what it is choosing to output." — Source: [AI Alignment Forum]
- On sycophancy: "Language models are incentivized by human feedback to agree with the user's stated premises, leading them to output known falsehoods if they predict the user wants to hear them." — Source: [arXiv Publications]
- On the geometry of truth: "There appear to be linear directions in a model's activation space that correlate strongly with the factual truth of a statement, independent of the statement's topic." — Source: [LessWrong]
- On honest AI: "True honesty in a system means its outputs are a direct translation of its internal latent representations, without filtering for human approval." — Source: [Bounded Regret]
- On concept extrapolation: "If a model learns the concept of truth on simple facts, we must figure out how to ensure that concept extrapolates correctly to complex, ambiguous scenarios." — Source: [AI Alignment Forum]
- On self-awareness in models: "As networks scale, they develop internal representations of their own behavior and context, which can be probed to understand their operational constraints." — Source: [80,000 Hours Podcast]
- On imitation learning: "Training a model purely to imitate human text guarantees that the model will also imitate human cognitive biases and logical errors." — Source: [Bounded Regret]
- On lie detection: "By analyzing the activation differences between truthful statements and forced falsehoods, we can build automated lie detectors for language models." — Source: [LessWrong]
Part 7: Career Strategy and Mentorship
- On entering AI safety: "Do not try to solve the entire alignment problem at once; pick a specific, tractable sub-problem and execute it to a high standard." — Source: [80,000 Hours Podcast]
- On building intuition: "The best way to understand neural networks is to run small, fast experiments where you can iteratively test hypotheses about their behavior." — Source: [Bounded Regret: Film Study for Research]
- On communication skills: "As long as I believed in my unusual ideas, I knew I had the communication skills to get other people to believe in them." — Source: [Imbue Interview]
- On choosing a lab: "Optimize for environments where you get high-bandwidth feedback from senior researchers, rather than optimizing purely for compute resources or brand name." — Source: [AI Alignment Forum]
- On emotional resilience: "Research involves long periods of confusion and failure; managing your own psychology during these troughs is as important as mathematical ability." — Source: [Bounded Regret]
- On interdisciplinary work: "Borrowing concepts from economics, cognitive science, and philosophy can provide fresh frameworks for understanding machine learning problems." — Source: [80,000 Hours Podcast]
- On pacing oneself: "Burnout in the safety community is high due to the perceived stakes; maintaining a sustainable pace is a strategic necessity rather than a luxury." — Source: [Bounded Regret]
- On publishing: "Do not wait for a project to be perfect before writing it up; the act of writing often clarifies the missing pieces of the research." — Source: [Bounded Regret: Film Study for Research]
- On impact: "The most impactful work often looks unglamorous from the outside, involving tedious data cleaning or debugging rather than writing entirely new architectures." — Source: [Bounded Regret]
Part 8: Ecosystem and Governance
- On open model weights: "Open-sourcing weights accelerates decentralized research, but it also democratizes the ability to remove safety guardrails, creating a complex risk tradeoff." — Source: [AI Alignment Forum]
- On institutional design: "We need institutions capable of monitoring AI development with the same rigor and authority that financial regulators apply to banks." — Source: [Bounded Regret]
- On economic incentives: "Commercial pressure to deploy models quickly frequently overrides the slower, methodical processes required to guarantee their safety." — Source: [Bounded Regret]
- On compute governance: "Tracking and restricting access to large-scale computing clusters may be one of the few enforceable levers for regulating advanced AI development." — Source: [80,000 Hours Podcast]
- On public understanding: "It is dangerous for the general public to view AI either as infallible or as completely useless; calibrated public trust is necessary for sound policy." — Source: [Bounded Regret]
- On international coordination: "Meaningful AI safety requires global agreements; unilateral restraint by one country or company only works if the leading edge is highly concentrated." — Source: [Bounded Regret]
- On independent labs: "Independent organizations are necessary to build open, scalable oversight technology without the commercial pressures faced by major model developers." — Source: [Bounded Regret]
- On automation of science: "When AI begins automating the scientific method itself, the pace of technological change will decouple entirely from human cognitive limits." — Source: [Bounded Regret: GPT-2030]
- On the burden of proof: "The default assumption should not be that a system is safe until proven dangerous, but rather that a system is dangerous until empirically proven safe." — Source: [AI Alignment Forum]
- On regulatory capture: "Governance structures must be designed to resist capture by the very technology companies they are intended to oversee, which requires strong independent technical expertise." — Source: [Bounded Regret]