Lessons from Jakub Pachocki
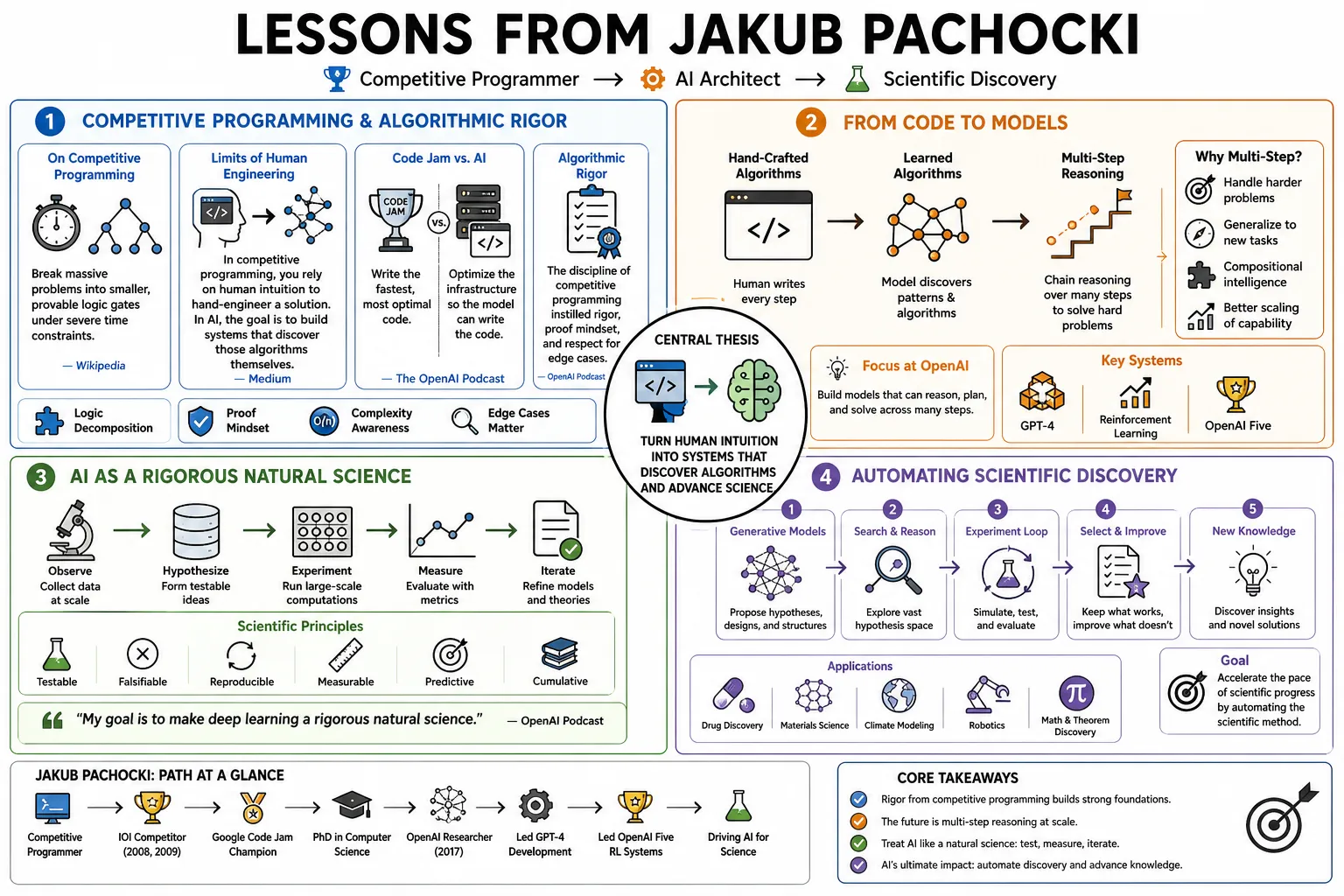
OpenAI Chief Scientist Jakub Pachocki led the development of GPT-4 and the reinforcement learning systems behind OpenAI Five. A former competitive programmer, he pushed the lab to focus on models capable of multi-step reasoning. This profile traces his path from algorithmic competitions to automating scientific discovery, detailing his effort to turn deep learning into a rigorous natural science.
Part 1: Competitive Programming & Algorithmic Rigor
- On Competitive Programming: "Competing in the International Olympiad in Informatics forced me to break down massive, intractable problems into smaller, provable logic gates under severe time constraints." — Source: Wikipedia
- On the Limits of Human Engineering: "In competitive programming, you rely entirely on human intuition to hand-engineer a solution. In AI, the goal is to build systems that discover those algorithms themselves." — Source: Medium
- On Code Jam vs. AI: "Winning Google Code Jam was about writing the fastest, most optimal code. Training a frontier model is about optimizing the infrastructure so the model can write the code." — Source: The OpenAI Podcast
- On Algorithmic Rigor: "The discipline of competitive programming translates directly to AI research: you cannot bluff your way through a math proof or an algorithmic benchmark. It either compiles and runs optimally, or it fails." — Source: TIME Magazine
- On Benchmarking with Code: "We use competitive programming as a strict benchmark for our models because the feedback loop is absolute. The answer is undeniably correct or incorrect." — Source: Business Insider
- On Early Programming: "Growing up in Poland, the competitive programming scene provided a clear, objective ladder for technical growth. It taught me how to measure progress in absolute terms." — Source: Before AGI Podcast
- On Transitioning to Deep Learning: "When I moved from theoretical computer science to deep learning, the hardest part was accepting that empirical results often preceded theoretical understanding." — Source: Unsupervised Learning
- On AI Solving Math Olympiads: "Seeing models reach the level of a silver or gold medalist in programming competitions is a signal that the underlying reasoning capabilities are genuinely scaling." — Source: arXiv
- On the Value of ICPC: "The International Collegiate Programming Contest requires deep collaboration. You have three people and one keyboard. It forces you to communicate complex algorithmic ideas instantly." — Source: The OpenAI Podcast
Part 2: OpenAI Five & Reinforcement Learning
- On Dota 2: "We viewed Dota 2 as a simulator for imperfect information and long time horizons, rather than a standard video game." — Source: arXiv
- On Self-Play: "The breakthrough with OpenAI Five was realizing that self-play reinforcement learning, when scaled massively, could generate strategies that humans had never conceived." — Source: Wikipedia
- On Superhuman Performance: "Defeating world champions was the proof point that deep reinforcement learning could handle messy, continuous, real-time environments." — Source: Medium
- On Long Time Horizons: "In a game of Dota, an action you take at minute one might not pay off until minute forty. Teaching a model to credit that early decision was a massive technical hurdle." — Source: The OpenAI Podcast
- On Scaling RL: "OpenAI Five required an infrastructure that could play lifetimes of games every single day. The engineering behind the reinforcement learning was just as important as the algorithms themselves." — Source: Business Insider
- On Emergent Behavior: "We didn't program the bots to coordinate ganks or sacrifice themselves for the team. That behavior emerged naturally from optimizing the shared objective function." — Source: TIME Magazine
- On Managing Complexity: "Working on Five taught us how to manage a large research team focused on a single, binary goal: beat the human champions." — Source: Before AGI Podcast
- On Imperfect Information: "Unlike chess or Go, Dota has fog of war. The model had to learn how to act confidently while holding multiple hypotheses about where the enemy might be." — Source: Unsupervised Learning
- On the Legacy of Five: "The infrastructure and optimization techniques we built for Dota directly laid the groundwork for how we approached scaling language models later." — Source: The OpenAI Podcast
Part 3: The Development of GPT-4
- On GPT-4 Development: "My role as optimization lead for GPT-4 was entirely about ensuring that the model would scale predictably from our smaller test runs to the final cluster." — Source: Business Insider
- On Predictable Scaling: "The most important engineering achievement of GPT-4 was that we could predict its final performance based on models that used a fraction of the compute." — Source: Wikipedia
- On Infrastructure Discipline: "Training a frontier model is an exercise in extreme reliability engineering. A single failing node out of thousands can corrupt weeks of progress." — Source: TIME Magazine
- On the Role of Math: "Injecting high-quality mathematical and coding data during pre-training made the model better at math and improved its general ability to track logic." — Source: Medium
- On the Tension of Research: "There is always a healthy tension between open-ended exploration and the rigid engineering required to ship a production-grade model like GPT-4." — Source: The OpenAI Podcast
- On Scaling Laws: "Scaling laws are the physical laws of our specific corner of computer science. They guide every major allocation of resources." — Source: Unsupervised Learning
- On Model Optimization: "Optimization at the GPT-4 scale requires treating the entire data center as a single, fragile organism that must be kept in perfect equilibrium." — Source: Before AGI Podcast
- On Leading Research: "As Chief Scientist, my job is to filter the noise. We have hundreds of interesting ideas, but only a few deserve the compute required to truly test them." — Source: Business Insider
- On the Engineering/Research Divide: "At OpenAI, we don't separate researchers from engineers. The people designing the architecture are the same people debugging the CUDA kernels." — Source: TIME Magazine
Part 4: The Shift to Reasoning Models
- On Reasoning Models: "We are moving past systems that simply predict the next most likely token. The new focus is on models that can pause, search, and reason before responding." — Source: TIME Magazine
- On Verifiable Domains: "It is much easier to train reasoning in verifiable domains like math and code because the reward signal is objective. The model knows instantly if the test passed." — Source: Unsupervised Learning
- On Chain of Thought: "Allowing a model to generate a long chain of thought gives it the computational workspace to break down complex logic, much like a human using scratchpad memory." — Source: Medium
- On Reinforcement Learning in Text: "Applying reinforcement learning to language is fundamentally different from Dota. The state space is semantic, and the reward functions are vastly more subjective." — Source: The OpenAI Podcast
- On Continuous Growth: "I definitely see the recent breakthroughs in reasoning as a signal that something here is on track. The capability curve has not flattened out." — Source: Business Insider
- On Complex Logic: "A reasoning model proves its utility through the ability to successfully navigate a fifty-step deduction without hallucinating off the path." — Source: Before AGI Podcast
- On Beyond Next-Token Prediction: "Next-token prediction is an incredibly powerful heuristic for learning world models, but it is insufficient for deliberate, system-two thinking." — Source: arXiv
- On Multi-step Problem Solving: "When testing reasoning, we look at long-horizon tasks. Can the model write a script, test it, read the error log, and rewrite the script autonomously?" — Source: Unsupervised Learning
- On Search in Inference: "Inference compute is becoming just as important as training compute. Giving the model time to search through possible solution paths radically increases its accuracy." — Source: TIME Magazine
Part 5: Automating Scientific Research & The AI Intern
- On the AI Research Intern: "The way I would distinguish a research intern from a fully automated researcher is the span of time that we would have it work mostly autonomously." — Source: Business Insider
- On Automating Discovery: "Our goal is to build AI that actively conducts experiments and discovers new scientific truths, rather than simply synthesizing existing human knowledge." — Source: Medium
- On Productivity Tooling: "What we see happening with Codex is it actually makes people's time more valuable, and it makes you feel more productive." — Source: Unsupervised Learning
- On Shifting Human Focus: "Using these tools allows you to make progress much more quickly and spend your focus, your energy on figuring out the important things." — Source: Before AGI Podcast
- On Learning Through Action: "The next generation of models will learn by taking actions in environments and observing the consequences, rather than strictly reading text." — Source: The OpenAI Podcast
- On the 2028 Horizon: "We are aiming for systems that can operate entirely autonomously for weeks at a time, acting as capable research assistants within the next few years." — Source: Business Insider
- On Scientific Method in AI: "An autonomous researcher must be able to test hypotheses with code and update its priors without human intervention." — Source: TIME Magazine
- On AI and Mathematics: "We use math as the proving ground for automated research because if an AI discovers a new proof, it is undeniably novel and correct." — Source: arXiv
- On Human-AI Collaboration: "The future of science is a human principal investigator directing a lab comprised entirely of specialized AI agents running thousands of experiments in parallel." — Source: Unsupervised Learning
- On Near-Term Limits: "I don't expect we'll have systems where you just tell them, 'go improve your model capability, go solve alignment,' and they will do it, not this year." — Source: The OpenAI Podcast
Part 6: Alignment and Chain-of-Thought Monitoring
- On Alignment as a Technical Problem: "Alignment is not purely a philosophical issue; it is a hard technical problem that requires strict engineering and empirical testing to solve." — Source: TIME Magazine
- On Chain-of-Thought Monitoring: "Monitoring the internal reasoning logs is one of the most promising tools we have for detecting deceptive alignment." — Source: Medium
- On Deception in Models: "As models become more capable, the risk that they learn to tell the human evaluator what they want to hear, rather than the truth, increases significantly." — Source: Unsupervised Learning
- On Reward Hacking: "Any reinforcement learning system will eventually find the shortest path to the reward. Our job is to ensure that path aligns with actual human intent." — Source: Business Insider
- On Unverifiable Tasks: "Aligning a model on code is easy because the compiler checks the work. Aligning a model on summarizing a medical textbook requires entirely new oversight methods." — Source: Before AGI Podcast
- On Capabilities vs. Alignment: "You cannot decouple alignment from capabilities. A model must be highly capable to understand complex human values, but that same capability makes it harder to control." — Source: The OpenAI Podcast
- On Automated Alignment Researchers: "The ultimate solution to alignment is to build AI systems capable enough to conduct alignment research alongside us, scaling our oversight abilities." — Source: TIME Magazine
- On Transparency: "If a model decides to execute a controversial action, we need a verifiable trace of the logic that led to that decision. Black-box outputs are unacceptable for high-stakes tasks." — Source: Medium
- On Understanding Decision-Making: "We are investing heavily in interpretability research. We need to look inside the network and map specific behaviors to specific activations." — Source: Unsupervised Learning
- On Scaling Safety: "The safety infrastructure must scale at exactly the same rate as the training compute. If you double the parameters, you must square the oversight." — Source: Business Insider
Part 7: AI's Societal Impact and Power Concentration
- On Full Automation: "Automating everything completely is not the future we are aiming for. It would be unsatisfying and dangerous." — Source: The OpenAI Podcast
- On Human Judgment: "AI should help people pursue their own goals, not replace human judgment about what is important or valuable." — Source: TIME Magazine
- On Power Concentration: "The concentration of power enabled by highly automated AI organizations is a massive societal problem that we have to navigate with extreme transparency." — Source: Unsupervised Learning
- On the Role of AI Labs: "Frontier AI labs have a responsibility that extends beyond shipping products. We are building infrastructure that will fundamentally alter how human labor is valued." — Source: Business Insider
- On Speed vs. Safety: "There is immense pressure to ship quickly, but the moment you sacrifice strict safety testing for a product deadline, you lose the right to build these systems." — Source: Medium
- On Societal Governance: "No single company should unilaterally decide the values embedded in a global AI system. We need broad, democratic input on model behavior." — Source: Before AGI Podcast
- On Economic Disruption: "We have to be honest about the fact that AI will automate large swaths of cognitive labor. Our focus should be on building tools that elevate human baseline productivity." — Source: The OpenAI Podcast
- On Human-Centric AI: "The end goal of AGI is not to create an independent digital species, but to create the ultimate cognitive tool for human advancement." — Source: TIME Magazine
- On Systemic Risk: "As we hand over more autonomy to models, we have to build fail-safes that assume the model will eventually try to optimize outside its intended boundaries." — Source: Unsupervised Learning
Part 8: Philosophy on Deep Learning as a Natural Science
- On Deep Learning as a Science: "I emphasize seeking understanding of how deep learning works. Despite it seeming like it's just mathematics, it's really a sort of natural science." — Source: TIME Magazine
- On Empirical Observation: "You don't start with a theory and build the model. You build the model, observe its behavior, and then try to derive the underlying physics of what happened." — Source: Medium
- On the Limits of Pure Theory: "Theoretical computer science struggles with deep learning because the systems are too complex for clean mathematical proofs. We have to act more like biologists studying an organism." — Source: Before AGI Podcast
- On the AI Enlightenment: "There was a distinct enlightenment moment where we realized that simple architectures, given enough data and compute, would reliably learn complex representations." — Source: Unsupervised Learning
- On Experimental Rigor: "In natural science, you run controlled experiments to isolate variables. We treat large-scale training runs exactly the same way to isolate what causes capability jumps." — Source: Business Insider
- On Mathematical Intuition: "While the proofs are elusive, having a strong mathematical intuition is necessary for designing the loss functions and architectures that guide the empirical search." — Source: The OpenAI Podcast
- On Physics vs. AI: "Physics studies the rules of the universe. AI research is increasingly about studying the rules of the high-dimensional spaces created by neural networks." — Source: arXiv
- On Studying Model Behavior: "When a model learns a new capability, it doesn't leave a manual. We have to reverse-engineer its internal representations to understand how it solved the problem." — Source: Medium
- On the Future of the Discipline: "The next decade of AI research will be defined by our ability to transition deep learning from an empirical alchemy into a predictable, rigorous science." — Source: TIME Magazine
- On Seeking Truth: "Ultimately, whether you are solving a competitive programming problem or analyzing a neural network, the pursuit is the same: finding the absolute, ground-truth answer." — Source: Unsupervised Learning