Lessons from Jared Kaplan
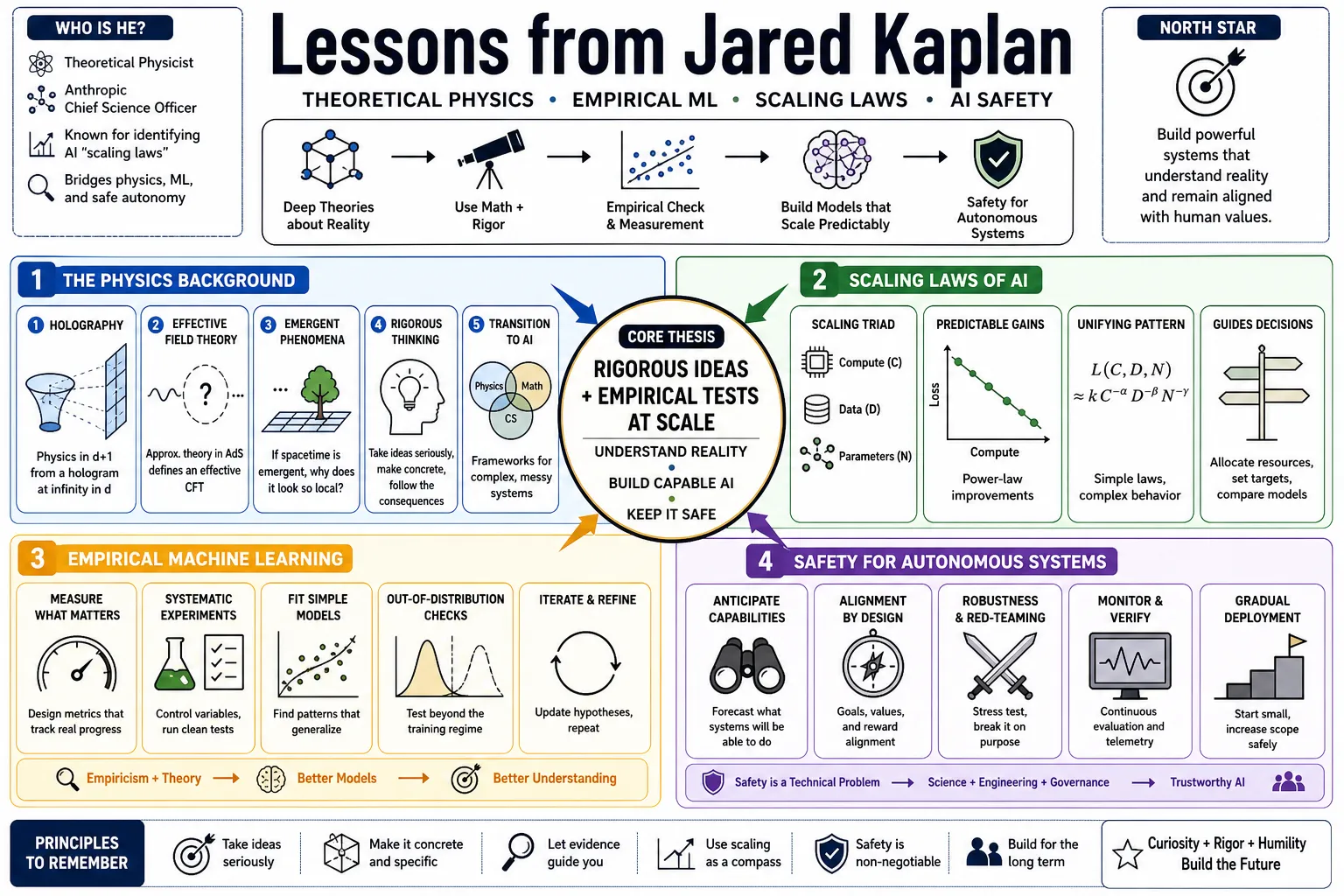
Theoretical physicist and Anthropic Chief Science Officer Jared Kaplan is best known for identifying AI "scaling laws," which demonstrate that neural networks predictably improve with more compute, data, and parameters. This profile collects his views on physics, empirical machine learning, and the safety measures required to manage autonomous systems.
Part 1: The Physics Background
- On holography: "The basic idea of holography is that physics in $d + 1$ dimensions can be reproduced by a 'hologram at infinity,' in $d$ or fewer dimensions." — Source: [Lectures on AdS/CFT]
- On rigorous thinking: "It's always a good idea to take ideas very seriously, make them as concrete and specific as possible, and then see where you are led." — Source: [Lectures on AdS/CFT]
- On effective field theory: "An incomplete theory of quantum gravity in AdS, such as a gravitational effective field theory... defines an approximate or effective CFT." — Source: [Lectures on AdS/CFT]
- On emergent phenomena: "If spacetime is emergent and not fundamental, how does it do such a good job of emerging so that we perceive a local world?" — Source: [Lectures on AdS/CFT]
- On the transition to AI: Theoretical physics provides a framework for looking at complex, messy systems and finding the underlying, predictable physical laws governing them. — Source: [Y Combinator AI Startup School]
- On the similarity between physics and deep learning: Both fields require empirical observation to identify the macro-level behaviors that emerge from micro-level complexity. — Source: [Y Combinator AI Startup School]
- On approaching neural networks: You can treat large language models as physical systems that obey natural laws, rather than just black-box engineering artifacts. — Source: [Y Combinator AI Startup School]
- On scale and complexity: Just as statistical mechanics explains thermodynamics, scaling laws explain the behavior of massive neural networks. — Source: [Y Combinator AI Startup School]
- On empirical science: Finding the UV completion for an effective field theory is mathematically similar to seeking the fundamental principles underlying machine learning models. — Source: [Lectures on AdS/CFT]
Part 2: The Discovery of Scaling Laws
- On the core discovery: "The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude." — Source: [Scaling Laws for Neural Language Models]
- On predictability: Model performance improves predictably over many orders of magnitude, turning AI development from guesswork into an empirical science. — Source: [Scaling Laws for Neural Language Models]
- On architectural details: "Other architectural details such as network width or depth have minimal effects within a wide range." — Source: [Scaling Laws for Neural Language Models]
- On the shift in focus: The realization that scale reliably drives performance shifted the field's focus away from bespoke architectural tweaks toward massive compute scaling. — Source: [Scaling Laws for Neural Language Models]
- On power-law dynamics: The relationship between scale and capability is not linear; it follows a precise power-law distribution that holds true across varying magnitudes. — Source: [Scaling Laws for Neural Language Models]
- On the empirical method: Rather than proving theorems, the discovery of scaling laws relied on running systematic experiments across different model sizes and plotting the results. — Source: [Y Combinator AI Startup School]
- On the limits of scaling: While scaling laws predict lower loss, they do not automatically predict when specific, discontinuous capabilities will emerge. — Source: [Y Combinator AI Startup School]
- On generalization: These scaling trends hold across different data distributions and tasks, suggesting a fundamental property of neural networks. — Source: [Scaling Laws for Neural Language Models]
- On the physics of intelligence: Intelligence, at least in the context of neural networks, scales in a predictable, almost physical manner. — Source: [Y Combinator AI Startup School]
Part 3: Compute, Data, and Parameters
- On compute efficiency: "Larger models are significantly more sample-efficient, such that optimally compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence." — Source: [Scaling Laws for Neural Language Models]
- On the data-compute trade-off: You do not need to scale data linearly with model size to achieve optimal compute efficiency. — Source: [Scaling Laws for Neural Language Models]
- On parameter scaling: Increasing the number of parameters consistently yields better performance, provided the data and compute are scaled appropriately. — Source: [Scaling Laws for Neural Language Models]
- On early stopping: Training a massive model for fewer steps is often a better use of compute than training a smaller model to convergence. — Source: [Scaling Laws for Neural Language Models]
- On the bottleneck: As models grow, securing high-quality data and sufficient compute become the primary bottlenecks, rather than algorithmic design. — Source: [Scaling Laws for Neural Language Models]
- On the data manifold: The underlying dimensions of the data manifold help explain why these power laws exist in the first place. — Source: [Scaling Laws for Neural Language Models]
- On sample efficiency: A larger network requires fewer examples to learn the same underlying pattern compared to a smaller network. — Source: [Scaling Laws for Neural Language Models]
- On predictable returns: Every time you increase the compute budget by a set factor, you get a predictable, proportional decrease in cross-entropy loss. — Source: [Scaling Laws for Neural Language Models]
- On the irrelevance of shape: Provided the model is large enough, the exact ratio of depth to width matters far less than the total parameter count. — Source: [Scaling Laws for Neural Language Models]
- On long-term planning: Because the returns on compute are predictable, organizations can confidently invest billions of dollars into future training runs. — Source: [Y Combinator AI Startup School]
Part 4: Founding Anthropic
- On organizational priorities: Anthropic was founded on the belief that scaling AI requires a simultaneous, proportional scaling of safety research. — Source: [Life With Machines Podcast]
- On empirical safety: Being an empiricist about AI means addressing risks through rigorous red-teaming and measurable protocols rather than just theoretical debate. — Source: [80,000 Hours]
- On industry coordination: It is difficult to make unilateral commitments to pause development if competitors are blazing ahead. — Source: [TechPolicy Press]
- On building trust: The goal is to build AI systems that are reliable, steerable, and safe for enterprise and societal use. — Source: [TechCrunch Equity Podcast]
- On the necessity of alignment: As models become more capable, the traditional methods of alignment break down, necessitating entirely new organizational structures. — Source: [Life With Machines Podcast]
- On Responsible Scaling Policies: Organizations must define specific capability thresholds that trigger mandatory safety and security upgrades. — Source: [Anthropic RSP]
- On the dual mandate: You have to push the frontier of capabilities to understand the frontier of risks; you cannot study the safety of models that do not exist yet. — Source: [TechCrunch Equity Podcast]
- On public benefit: The structure of the company itself must reflect the commitment to long-term societal benefit over short-term commercial pressures. — Source: [Life With Machines Podcast]
- On frontier models: Developing state-of-the-art models like Claude is necessary to test and validate novel safety techniques at scale. — Source: [TechCrunch Equity Podcast]
Part 5: Constitutional AI
- On the core mechanism: "Instead of asking a person to decide which response they prefer, you can ask a version of the large language model, 'which response is more in accord with a given principle?'" — Source: [BioComm.ai Interview]
- On scaling supervision: "You let the language model's opinion of which behavior is better guide the system to be more helpful, honest, and harmless." — Source: [BioComm.ai Interview]
- On human limitations: Relying solely on human feedback is difficult to scale and fraught with subjective bias; AI can supervise itself more consistently. — Source: [Constitutional AI Paper]
- On codifying values: We can encode behavioral norms into a clear constitution that dictates how the model should behave in nuanced situations. — Source: [Constitutional AI Paper]
- On self-critique: The process involves having the model generate self-critiques based on the constitution, and then fine-tuning it on the revised, safer responses. — Source: [Constitutional AI Paper]
- On RLAIF: A preference model can be trained on AI-generated evaluations to provide a reward signal, drastically reducing the need for human raters. — Source: [Constitutional AI Paper]
- On transparency: A written constitution makes the values guiding the AI explicit and subject to public debate, rather than hidden in a black box of human preference data. — Source: [Senate AI Insight Forum]
- On the necessity of advanced techniques: "We see room for much more to make these techniques reliable with human-level systems." — Source: [Senate AI Insight Forum]
- On controlling behavior: Constitutional AI allows researchers to control AI output more precisely and with significantly fewer human labels than previous methods. — Source: [Constitutional AI Paper]
- On helpfulness vs. harmlessness: The constitution provides a framework for the model to balance being genuinely useful with avoiding generating harmful or dangerous content. — Source: [Constitutional AI Paper]
Part 6: Predictability in AI Development
- On treating AI as science: We must move away from treating machine learning as alchemy and approach it with the rigor of experimental physics. — Source: [Y Combinator AI Startup School]
- On extrapolating trends: The consistency of scaling laws means we can accurately project the capabilities of models that are years away from being built. — Source: [Exponential View Podcast]
- On managing expectations: Predictability allows us to foresee capability jumps and prepare safety measures before those models are deployed. — Source: [Exponential View Podcast]
- On the limits of intuition: Human intuition about what a neural network can or cannot learn is frequently wrong; empirical scaling curves are a much more reliable guide. — Source: [Y Combinator AI Startup School]
- On the cost of experiments: Because large training runs are prohibitively expensive, predicting the outcome beforehand is structurally necessary for the field. — Source: [Y Combinator AI Startup School]
- On test-time compute: Scaling laws apply not just to training, but to inference; giving a model more time to think predictably improves its performance on complex tasks. — Source: [Exponential View Podcast]
- On algorithmic efficiency: While brute compute scaling is reliable, improvements in algorithmic efficiency also compound predictably over time. — Source: [Y Combinator AI Startup School]
- On breaking the curve: The goal of AI research is often to find paradigm shifts that bend the scaling curve, achieving better performance for less compute. — Source: [Y Combinator AI Startup School]
- On macro-behavior: You do not need to understand every individual weight in a network to accurately predict the macro-behavior of the system as it scales. — Source: [Y Combinator AI Startup School]
Part 7: Human-Level AI and Timelines
- On timelines: The rapid evolution of AI suggests that reaching human-level capabilities across a broad range of tasks is a plausible reality by the end of the decade. — Source: [Exponential View Podcast]
- On agentic systems: The next major shift is moving from static conversational models to agentic systems capable of executing multi-step, long-horizon workflows. — Source: [TechCrunch Equity Podcast]
- On evaluating intelligence: As models approach human-level performance, traditional benchmarks become saturated, requiring us to design much harder, more open-ended evaluations. — Source: [Exponential View Podcast]
- On coding and logic: Tools like Claude Code demonstrate that models are rapidly mastering syntax, logic, and complex software engineering tasks. — Source: [TechCrunch Equity Podcast]
- On continuous learning: For an AI to be truly human-level, it must possess organizational memory and the ability to learn and adapt continuously within a given environment. — Source: [Y Combinator AI Startup School]
- On the shifting baseline: What we consider human-level is a moving target; models may surpass humans in specific domains long before achieving general autonomy. — Source: [Exponential View Podcast]
- On oversight: As models tackle longer-horizon tasks, the challenge shifts from direct supervision to developing reliable oversight mechanisms for asynchronous work. — Source: [Y Combinator AI Startup School]
- On human-AI collaboration: The future involves humans acting as managers and reviewers for highly capable, autonomous AI agents. — Source: [TechCrunch Equity Podcast]
- On enterprise trust: Deploying human-level agents in real-world environments requires solving fundamental problems of reliability, hallucination, and system security. — Source: [TechCrunch Equity Podcast]
Part 8: AI Safety and The Ultimate Risk
- On recursive self-improvement: Allowing AI systems to train themselves and direct their own research is a critical threshold with massive implications. — Source: [The Guardian]
- On letting go of control: The moment we allow highly capable systems full autonomy represents the ultimate risk, because it is like letting AI go. — Source: [The Guardian]
- On the necessity of alignment at scale: Current alignment techniques work well for current models, but they may not hold up under the pressure of superintelligent systems. — Source: [The Guardian]
- On the capability-safety gap: The primary danger is that the speed of scaling capabilities outpaces our ability to invent corresponding safety and oversight mechanisms. — Source: [Life With Machines Podcast]
- On malicious use: We must proactively defend against the misuse of frontier models for cyberattacks, bioweapon design, and automated deception. — Source: [Life With Machines Podcast]
- On structural incentives: The intense commercial competition in the AI sector makes it structurally difficult for any single actor to prioritize safety over speed. — Source: [TechPolicy Press]
- On the role of government: There is a growing need for regulatory frameworks that understand the technical realities of scaling and enforce baseline safety standards. — Source: [Senate AI Insight Forum]
- On the burden of proof: The burden should be on AI developers to empirically demonstrate that their systems are safe before deploying them at scale. — Source: [Anthropic RSP]
- On existential risk: We have to acknowledge the non-zero probability that unaligned, highly autonomous systems could pose an existential threat to humanity. — Source: [The Guardian]
- On the path forward: Mitigating these risks requires a commitment to transparency, rigorous internal testing, and a willingness to halt deployment if safety thresholds are not met. — Source: [Anthropic RSP]