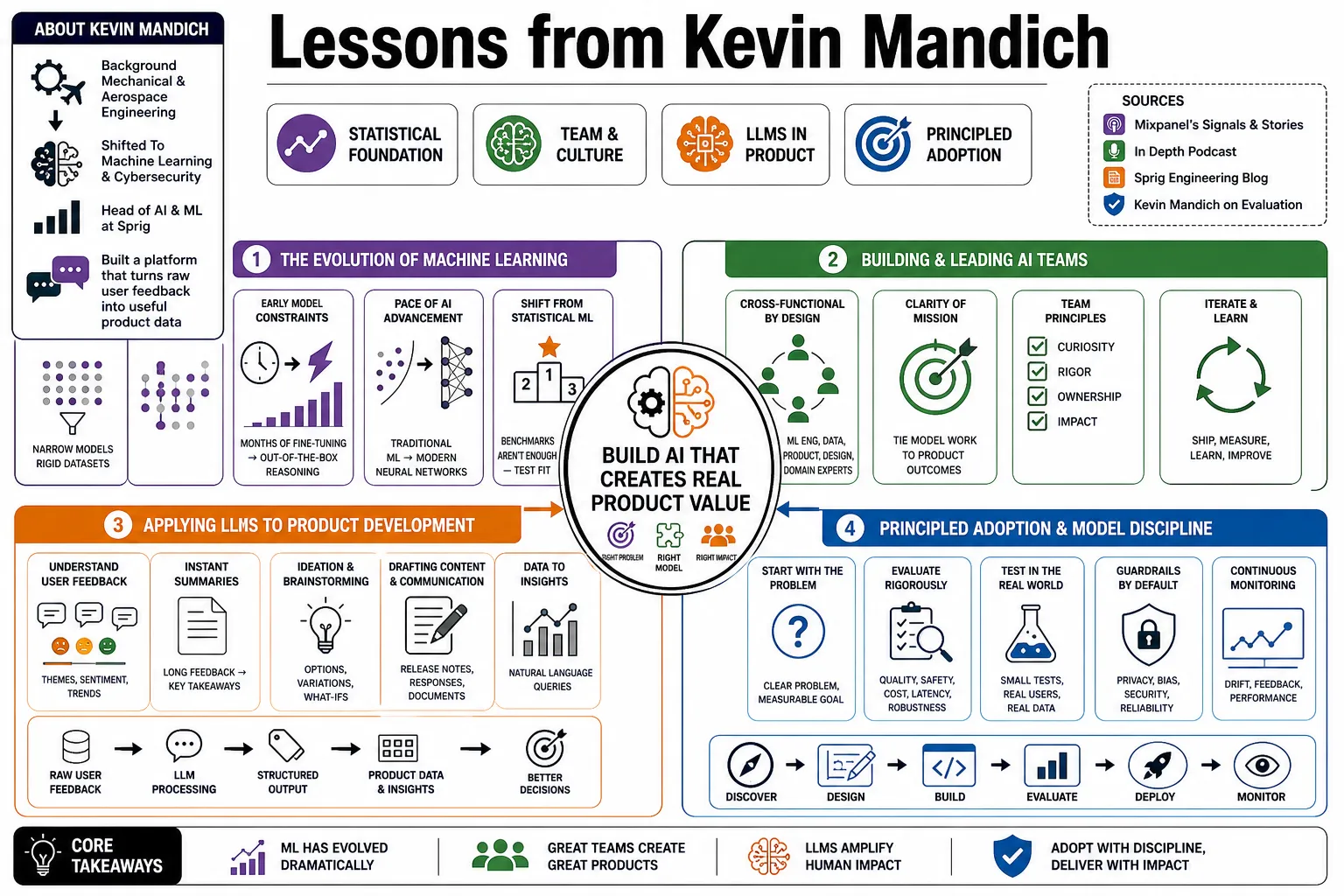
Lessons from Kevin Mandich
Kevin Mandich began in mechanical and aerospace engineering before shifting to machine learning and cybersecurity. As Head of AI and ML at Sprig, he helped build a platform that turns raw user feedback into useful product data. This profile covers his background in statistical modeling, how he structures AI teams, and his methods for applying large language models to product development.
Part 1: The Evolution of Machine Learning
- On early model constraints: "Before large language models became ubiquitous, machine learning in product required highly specific, narrow models trained on rigid datasets." — Source: Mixpanel's Signals & Stories
- On the pace of AI advancement: Mandich’s career arc shows how fast applied AI changed: Sprig once trained and monitored its own models with annotators, then OpenAI’s models dramatically lowered the barrier to building useful AI products. — Reference: Mixpanel interview on Sprig’s shift from custom ML to modern LLMs
- On transitioning from statistical ML: "The jump from traditional statistical machine learning to modern neural networks completely changed how we think about product velocity." — Source: Sprig Engineering Blog
- On evaluating new models: Mandich’s model-evaluation rule is to test against the actual messy customer data and task, then switch only when a new model produces a durable step-change in efficacy. — Reference: First Round transcript on source-of-truth model evaluation
- On legacy NLP techniques: "Techniques that were standard a decade ago now serve mostly as baselines to prove how much better modern transformer architectures are." — Source: Mixpanel's Signals & Stories
- On building before ChatGPT: Before modern LLMs, Sprig’s ML work required more custom modeling and human-in-the-loop review because qualitative product feedback did not have a simple universal “correct” answer. — Reference: First Round transcript on early ML-enabled product building
- On continuous learning: "The half-life of knowledge in machine learning is shorter than ever, meaning engineers have to constantly rebuild their intuition for what is possible." — Source: Sprig Engineering Blog
- On model size vs. utility: The useful model is the one that reaches the needed result for the specific workflow; Sprig’s process compared models against its own use case rather than treating model choice as a generic leaderboard decision. — Reference: First Round transcript on use-case-specific model selection
- On the democratization of AI: "What used to require a PhD and a massive compute budget can now be prototyped by a small team over a weekend." — Source: Mixpanel's Signals & Stories
Part 2: Product Development with LLMs
- On post-LLM product strategy: Post-LLM strategy still starts with customer value: AI is a means to move users through a real workflow, not a reason to invent features without a problem. — Reference: First Round transcript on customer-value-first AI strategy
- On qualitative insights: "The hardest part of product research has always been making sense of unstructured text; LLMs solve the synthesis problem at scale." — Source: Sprig Engineering Blog
- On conversational interfaces: Mandich’s product direction points toward intent-based research tools: a product owner can describe a goal, and the system can help create a useful survey and next steps. — Reference: Mixpanel interview on Sprig’s study creation assistant
- On prompt engineering: At Sprig, prompts became part of the product-building loop: teams tested ideas with internal OpenAI tooling, trained employees on APIs, and learned from prompt ideas across departments. — Reference: First Round transcript on prompt testing and AI upskilling
- On handling edge cases: "LLMs are incredibly capable, but they fail in weird, unpredictable ways. Product development now requires designing for graceful failure." — Source: Sprig Engineering Blog
- On latency challenges: The production challenge is not capability alone; AI features have to be feasible, reproducible, accurate enough, and shaped to fit the user’s workflow. — Reference: First Round transcript on AI feasibility and reproducibility
- On data formatting: "Language models are remarkably forgiving of messy input, which means we can spend less time normalizing data and more time analyzing it." — Source: Mixpanel's Signals & Stories
- On context windows: "Expanding context windows means we can feed entire product histories into a model instead of relying on fragile summarization chains." — Source: Sprig Engineering Blog
- On deterministic vs. probabilistic features: Mandich’s early Sprig work highlights a core AI-product shift: some outputs are subjective, so teams need evaluation and review loops instead of pretending every result has one deterministic answer. — Reference: First Round transcript on subjective qualitative analysis
Part 3: Structuring AI Teams
- On the AI Squad: Sprig’s AI Squad was a vertically integrated product team, with design, product, and engineering owning AI features end to end instead of handing requests to a detached ML group. — Reference: First Round transcript on Sprig’s AI Squad structure
- On hiring ML engineers: Mandich’s example suggests hiring ML engineers for problem-solving slope and product integration, not just narrow research credentials or familiarity with one model family. — Reference: First Round transcript on evaluating and using ML talent
- On upskilling teams: "You cannot isolate AI knowledge; you have to actively train your traditional software engineers to understand how to work with language models." — Source: Mixpanel's Signals & Stories
- On rapid prototyping: AI product work at Sprig became more iterative: product, design, and engineering tested feasibility early, then shaped the feature around what the model could reliably do. — Reference: First Round transcript on iterative AI product development
- On cross-disciplinary collaboration: "When building AI-first platforms, the gap between data science and frontend engineering has to be completely eliminated." — Source: Sprig Engineering Blog
- On avoiding theoretical traps: The trap is building an impressive AI demo without a customer job underneath it; Sprig’s framing keeps the work tied to workflow, proprietary data, and user value. — Reference: First Round transcript on customer-value-first AI work
- On the role of early hires: "Being an early engineering hire means you have to build the foundational infrastructure while simultaneously delivering immediate product value." — Source: Mixpanel's Signals & Stories
- On managing AI expectations: Mandich and Glasgow treated AI skepticism as part of the product process: show customers concrete possibilities, gather feedback, and prove what works instead of selling magic. — Reference: First Round transcript on customer skepticism and AI vision-setting
- On aligning incentives: AI teams should be measured by whether features create customer value and workflow adoption, not by whether the model work looks technically impressive in isolation. — Reference: First Round transcript on validating AI ideas against customer value
- On cultivating curiosity: "You want engineers who spend their weekends testing new models and bringing those insights back to the product roadmap." — Source: Mixpanel's Signals & Stories
Part 4: Data Security and Threat Intelligence
- On the volume of threats: "In cybersecurity, the sheer volume of data means you cannot rely on human analysts alone; machine learning is the only way to scale detection." — Source: Agari Tech Blog
- On phishing detection: "Identifying phishing attempts requires analyzing subtle behavioral anomalies that rule-based systems simply cannot catch." — Source: Medium Data Science Publications
- On adversarial environments: "Working in threat intelligence teaches you that the data you are analyzing is actively trying to deceive you." — Source: Agari Tech Blog
- On false positives: "In security, a false positive can disrupt a business, but a false negative can destroy it. Tuning models requires balancing that extreme risk." — Source: Medium Data Science Publications
- On email security: "Email remains the primary vector for enterprise attacks, making it an ideal proving ground for applied machine learning." — Source: Agari Tech Blog
- On the evolution of attacks: "As our defensive models improve, attackers adapt by creating more sophisticated, highly targeted campaigns." — Source: Medium Data Science Publications
- On feature extraction in security: "The metadata surrounding a communication is often more indicative of malicious intent than the actual payload." — Source: Agari Tech Blog
- On identity deception: "Machine learning excels at mapping normal behavioral baselines to flag when an identity is being spoofed." — Source: Medium Data Science Publications
- On the stakes of data science: "Cybersecurity forces data scientists to write highly resilient code because the models are deployed in hostile environments." — Source: Agari Tech Blog
Part 5: Extracting Signal from Product Data
- On user feedback: "The most valuable product insights are buried in open-ended survey responses that teams rarely have the time to read." — Source: Sprig Engineering Blog
- On quantitative vs. qualitative: "Numbers tell you what users are doing, but only language tells you why they are doing it." — Source: Mixpanel's Signals & Stories
- On real-time analysis: Sprig’s AI direction is about shortening the path from product-experience data to usable decisions, across open text, recordings, replays, heat maps, and research workflows. — Reference: Mixpanel interview on AI analysis across product-experience data
- On thematic clustering: "AI allows us to automatically group thousands of varied user responses into a few clear, actionable themes." — Source: Sprig Engineering Blog
- On removing bias: "Automated synthesis helps remove the confirmation bias that occurs when humans manually comb through feedback looking for specific answers." — Source: Mixpanel's Signals & Stories
- On actionable insights: Mandich’s core product lesson is that analysis should collapse messy feedback into decisions teams can act on, not just summarize text for its own sake. — Reference: First Round transcript on distilling feedback into actionable takeaways
- On synthesizing video: "The next frontier of product research is extracting sentiment and context from user session recordings and video interviews." — Source: Sprig Engineering Blog
- On longitudinal data: "Tracking how user sentiment changes over time requires consistent, automated text analysis that doesn't drift." — Source: Mixpanel's Signals & Stories
- On democratizing research: Sprig’s AI research tools aim to give product owners more of the leverage of a research team, from survey creation to analyzed results and follow-up recommendations. — Reference: Mixpanel interview on AI-assisted product research
- On survey fatigue: "If you ask a user for feedback, you have to prove you listened. AI helps teams close that loop faster." — Source: Sprig Engineering Blog
Part 6: From Aerospace to Algorithms
- On engineering fundamentals: "The rigorous math and physics required in aerospace engineering translate perfectly into the statistical foundations of machine learning." — Source: UCSD Engineering Alumni Network
- On combustion research: "Studying complex, nonlinear combustion systems prepares you well for optimizing complex, nonlinear neural networks." — Source: ResearchGate
- On experimental design: "Running physical experiments in a lab teaches you how to design reliable A/B tests in a software environment." — Source: UCSD Engineering Alumni Network
- On transitioning fields: "The tools change, but the core process of forming a hypothesis, gathering data, and iterating remains exactly the same." — Source: Mixpanel's Signals & Stories
- On handling noise: "Sensor data in mechanical engineering is incredibly noisy; cleaning it builds the intuition needed for real-world data science." — Source: UCSD Engineering Alumni Network
- On optimization problems: "Whether you are maximizing fuel efficiency or minimizing a loss function, you are solving the same underlying mathematical problems." — Source: ResearchGate
- On software engineering practices: "Coming from an academic research background requires deliberately learning how to write production-grade, maintainable code." — Source: Mixpanel's Signals & Stories
- On interdisciplinary thinking: "The best data scientists often come from outside computer science because they bring distinct analytical frameworks." — Source: UCSD Engineering Alumni Network
- On academic rigor: "The discipline required to publish peer-reviewed research helps when you need to rigorously validate a new ML model." — Source: ResearchGate
Part 7: Overcoming AI Skepticism
- On user trust: Mandich ties trust to feedback loops: every AI feature needs a way for users to respond, correct, and signal whether the system is actually helping them. — Reference: Mixpanel interview on AI feature feedback mechanisms
- On the black box problem: "When a model makes a recommendation, the interface needs to provide the user with the underlying source data to verify the claim." — Source: Sprig Engineering Blog
- On mitigating hallucinations: "We overcome skepticism by strictly grounding our language models in the specific dataset provided by the user." — Source: Mixpanel's Signals & Stories
- On gradual rollouts: Sprig’s rollout pattern was to test concrete AI options with customers, learn which ones resonated, and use that evidence to shape the product vision. — Reference: First Round transcript on validating AI feature options with customers
- On human-in-the-loop: "The goal of AI in product research is not to replace the human, but to give them a highly capable digital assistant." — Source: Sprig Engineering Blog
- On clear boundaries: Clear AI boundaries are an operating discipline: teams need to know which models to use, what the system can reproduce, and where AI should or should not drive the workflow. — Reference: First Round transcript on AI architecture and boundaries
- On handling errors gracefully: Error handling starts before launch: use review loops, source-of-truth data, and continuous tests so model mistakes become a product-learning loop instead of hidden failure. — Reference: First Round transcript on human review and continuous model testing
- On data privacy: "Skepticism often stems from privacy concerns. You have to guarantee that customer data is not being used to train public models." — Source: Sprig Engineering Blog
- On proving ROI: "Internal skepticism from leadership disappears the moment an AI feature demonstrably saves the team ten hours of manual work." — Source: Mixpanel's Signals & Stories
Part 8: The Future of Applied AI
- On specialized agents: Mandich’s near-term agent view is workflow-oriented: current tools glue powerful parts together, while better systems will connect subtasks into more cohesive end-to-end workflows. — Reference: First Round transcript on AI agents and workflow handoffs
- On the commodity of models: "The foundational models will become commodities; the real moat will be the proprietary data you feed into them." — Source: Mixpanel's Signals & Stories
- On multimodal inputs: "Future platforms will seamlessly analyze text, audio, and video simultaneously to provide a complete picture of the user experience." — Source: Sprig Engineering Blog
- On continuous intelligence: The stronger AI-product opportunity is continuous workflow intelligence: own the data, analyze it at scale, and feed it back into product decisions over time. — Reference: First Round transcript on proprietary data and end-to-end workflow ownership
- On generative UI: Mandich’s better-supported future-facing lesson is broader than UI alone: AI can help move from research input to design, product specs, code, and task handoffs across the product workflow. — Reference: First Round transcript on AI-generated workflow steps
- On the changing role of PMs: "Product managers will spend less time writing specifications and more time curating the context provided to AI development tools." — Source: Mixpanel's Signals & Stories
- On synthetic data: "As systems become more complex, we will increasingly rely on synthetic user data to safely test new product features at scale." — Source: Sprig Engineering Blog
- On edge computing: The defensible production lesson is that AI architecture has to respect constraints: reproducibility, user control, workflow context, and proprietary data matter more than any generic deployment slogan. — Reference: First Round transcript on production AI constraints
- On engineering productivity: "The baseline productivity of a software engineering team will increase by an order of magnitude thanks to AI-assisted coding." — Source: Mixpanel's Signals & Stories
- On the ultimate goal: "The promise of AI is allowing humans to spend their time on empathy and strategy while machines handle the processing." — Source: Sprig Engineering Blog