Lessons from Kyunghyun Cho
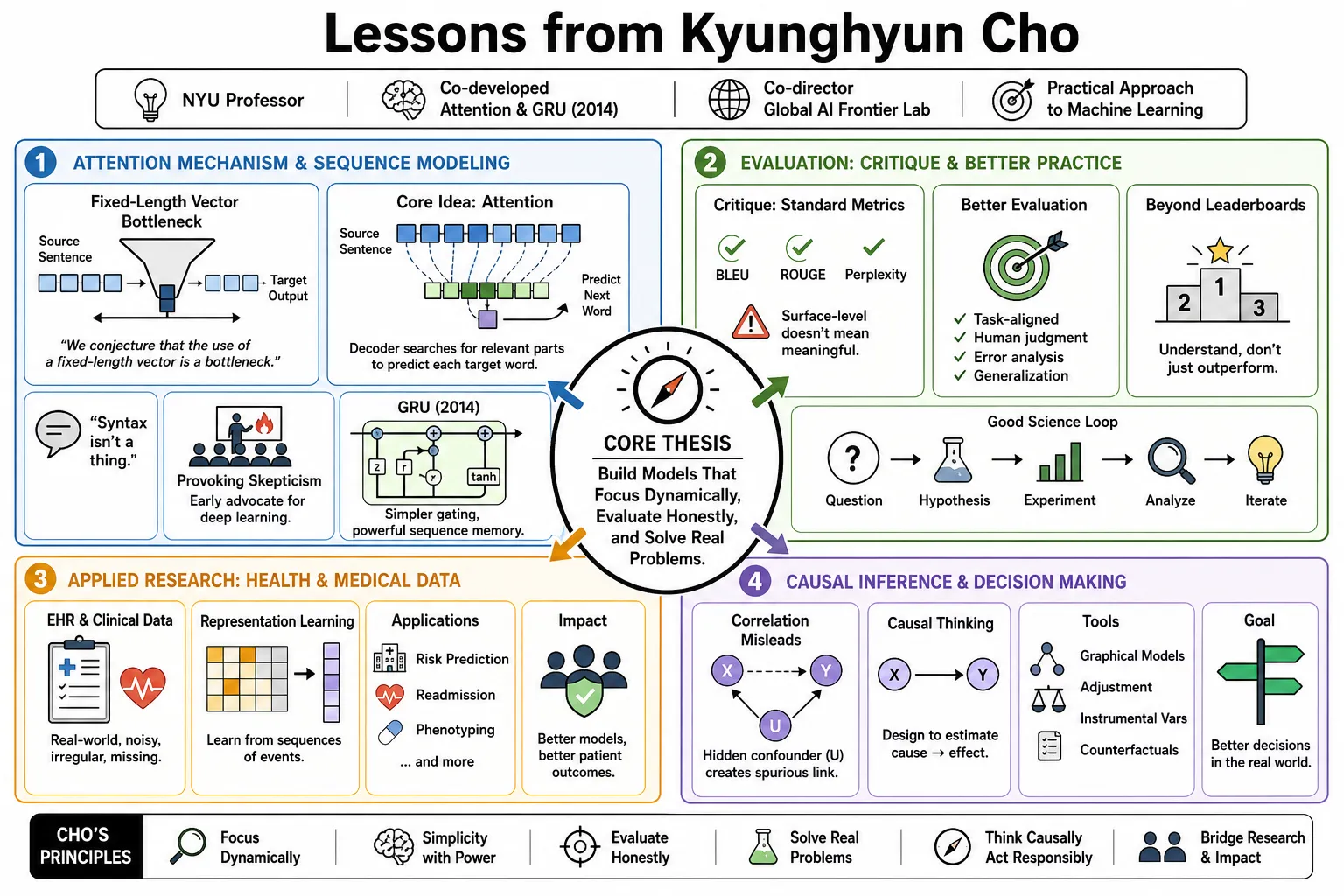
NYU professor Kyunghyun Cho co-developed the attention mechanism and the Gated Recurrent Unit in 2014, allowing neural networks to process language dynamically. As co-director of the Global AI Frontier Lab, he takes a practical approach to machine learning. This profile covers his critiques of standard evaluation methods and his applied research in medical data and causal inference.
Part 1: The Attention Mechanism and Sequence Modeling
- On the fixed-length vector bottleneck: "We conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder-decoder architecture." — Source: [Neural Machine Translation by Jointly Learning to Align and Translate (2014)]
- On the core idea of attention: "Instead of forcing the encoder to compress everything into one vector, we should allow the decoder to automatically search for parts of a source sentence that are relevant to predicting a target word." — Source: [Neural Machine Translation by Jointly Learning to Align and Translate (2014)]
- On linguistic structure: "Syntax isn't a thing." — Source: [Personal Blog: "Bye, Felix" (2024)]
- On early skepticism of deep learning: "It was a regular occurrence in my slide decks to provoke audiences who were wary of deep learning's lack of explicit linguistic structure." — Source: [Personal Blog: "Bye, Felix" (2024)]
- On the Gated Recurrent Unit (GRU): "The motivation was to design a simpler architecture than LSTM that could still effectively capture long-term dependencies in sequence data without suffering from vanishing gradients." — Source: [Learning Phrase Representations using RNN Encoder-Decoder (2014)]
- On soft-searching input: "By allowing the model to dynamically look back at the input during translation, we removed the necessity of cramming all information into a single fixed representation." — Source: [Super Data Science Ep. 977]
- On the transition from statistical translation: "We moved from building highly complex, multi-stage pipelines to training a single neural network end-to-end to map sequences to sequences." — Source: [The Gradient Podcast Ep. 59]
- On sequence-to-sequence learning: "The encoder-decoder framework provided a general recipe for tasks where the input and output have different lengths, which was notoriously hard to handle before." — Source: [The Gradient Podcast Ep. 59]
- On long sentences in translation: "The attention mechanism specifically solved the rapid degradation in translation quality that earlier models experienced when input length increased." — Source: [Super Data Science Ep. 977]
- On bridging architectures: "Our work served as a bridge between the era of recurrent neural networks and the fully attention-based architectures that dominate today." — Source: [Super Data Science Ep. 977]
Part 2: The Future of Deep Learning and World Models
- On the limits of passive data: "Current models have already captured most of the correlations available in passive, static data on the internet." — Source: [Super Data Science Ep. 977]
- On the next frontier of learning: "The next major challenge lies in active data collection: designing systems that can actively choose which data they need to learn from." — Source: [Super Data Science Ep. 977]
- On world models: "There is an ongoing debate about whether AI needs a high-fidelity, step-by-step imagination of the world, or if operating purely on high-level latent representations is sufficient." — Source: [Super Data Science Ep. 977]
- On sample efficiency: "While foundation models are powerful, their sample efficiency is poor compared to humans, pointing to the need for better algorithms rather than merely adding more data." — Source: [Cohere For AI Fireside Chat]
- On chasing scale: "Scaling up works, but we also have to focus on more difficult, costly-to-develop problems like active learning and handling distribution shifts." — Source: [The Gradient Podcast Ep. 59]
- On emergent communication: "My broader goal is to build intelligent machines that communicate effectively, aiming to create new knowledge among multiple agents rather than completing isolated tasks." — Source: [Kyunghyun Cho's Academic Profile]
- On foundation models: "Foundation models are a great starting point, but they still struggle when confronted with out-of-distribution inputs that require reasoning rather than retrieval." — Source: [Cohere For AI Fireside Chat]
- On latent planning: "Planning in a latent space allows a model to consider multiple future states without the computational burden of generating every intermediate pixel or token." — Source: [Super Data Science Ep. 977]
- On retrieval-augmented generation: "RAG provides a mechanism to ground language models in factual databases, mitigating hallucinations by separating knowledge retrieval from language generation." — Source: [Super Data Science Ep. 977]
- On distribution shifts: "We need models that recognize when they are operating outside their training distribution and act cautiously, rather than predicting confidently." — Source: [Cohere For AI Fireside Chat]
Part 3: Pragmatic AI in Healthcare and Science
- On clinical operations: "We need to focus on improving clinical operations at scale instead of building AI to solve isolated diagnostic puzzles." — Source: [NEJM AI Grand Rounds]
- On hospital deployments: "A model that performs well on a test set often fails in a hospital because the operational reality of clinical workflows introduces variables we didn't account for." — Source: [NEJM AI Grand Rounds]
- On drug discovery: "Current drug discovery pipelines are inefficient; AI should be used to model biological complexity early in the process to reduce late-stage clinical trial failures." — Source: [NEJM AI Grand Rounds]
- On medical records: "I envision a system of patient-controlled medical records where AI helps individuals understand and manage their own health history across different providers." — Source: [NEJM AI Grand Rounds]
- On automated clinical trials: "Continuous, automated clinical trials using AI could allow us to monitor drug efficacy and safety in real-time across diverse populations." — Source: [NEJM AI Grand Rounds]
- On interpretability in medicine: "Interpretability can be a useful extra feature, but it may not be strictly necessary for deployment; we regularly use drugs without fully understanding their underlying biological mechanisms." — Source: [Personal Blog (2025)]
- On AI for science: "Applying AI to scientific domains like material design and biology requires us to incorporate domain knowledge, treating it as more than a standard text prediction problem." — Source: [The Gradient Podcast Ep. 59]
- On operational prediction: "Predicting hospital bed availability or patient discharge times can sometimes save more resources than an AI that reads X-rays." — Source: [NEJM AI Grand Rounds]
- On healthcare data: "Medical data is inherently noisy, biased, and sparse; algorithms must be designed specifically to handle these properties." — Source: [NEJM AI Grand Rounds]
- On interdisciplinary collaboration: "Computer scientists cannot solve healthcare alone; building effective medical AI requires deep collaboration with clinicians who understand the ground truth." — Source: [NEJM AI Grand Rounds]
Part 4: Doing Good Science and Research Philosophy
- On personal identity and research: "Doing good science requires detaching your personal identity from your work, so you can objectively evaluate when your hypothesis is wrong." — Source: [The Gradient Podcast Ep. 59]
- On chasing state-of-the-art: "We need to move away from simply chasing the latest SOTA numbers and focus on whether a paper actually teaches us something new about how neural networks operate." — Source: [EMNLP 2019 Keynote]
- On novelty: "A 'novelty-less' journey into neural sequence models can sometimes be more informative than proposing a slightly modified architecture to claim a minor performance bump." — Source: [EMNLP 2019 Keynote]
- On the hero scientist narrative: "The community should be careful not to take the warnings of a few high-profile researchers as gospel; science relies on a diversity of opinions, not authority." — Source: [Personal Blog (2024)]
- On failure in research: "Most research ideas will fail, and learning to rapidly prototype and discard bad ideas is a core skill for any PhD student." — Source: [The Gradient Podcast Ep. 59]
- On peer review: "The current peer review process often optimizes for safe, incremental papers rather than bold, risky ideas that might fail but could fundamentally change the field." — Source: [The Gradient Podcast Ep. 59]
- On academic freedom: "Academia provides the unique freedom to work on problems that have no immediate commercial value but are necessary for the long-term understanding of intelligence." — Source: [Technically Optimistic Podcast]
- On writing papers: "A paper should tell a clear story. If you cannot explain the core motivation of your method in one simple paragraph, the method is probably too complex." — Source: [Personal Blog (2023)]
- On community consensus: "When the entire research community agrees on a single approach, it is usually the right time for researchers to start exploring alternative paradigms." — Source: [The Gradient Podcast Ep. 59]
- On scientific transparency: "Releasing code and data is a strict requirement for verifying claims in a field where theoretical proofs are rare." — Source: [EMNLP 2019 Keynote]
Part 5: Causality and Deep Learning
- On causal discovery: "Deep learning is incredibly good at finding associations, but we are now figuring out how to use these networks to derive actual causal estimators." — Source: [Kempner Seminar Series (2026)]
- On correlational models: "A model that relies purely on correlation will inevitably fail when deployed in an environment where the underlying causal graph has shifted." — Source: [Vector Institute Lecture (2025)]
- On unobserved confounders: "The hardest part of applying deep learning to real-world observational data is dealing with unobserved confounders that bias the network's predictions." — Source: [Vector Institute Lecture (2025)]
- On deep learning as a causal tool: "Neural networks should be viewed as flexible function approximators that can help us estimate complex causal effects when the relationships are non-linear." — Source: [Kempner Seminar Series (2026)]
- On counterfactual reasoning: "To build reliable systems, we need models capable of asking 'what if' questions and reasoning about alternative scenarios." — Source: [Vector Institute Lecture (2025)]
- On experimental design: "Active learning is closely related to experimental design; the model must learn to intervene in the environment to discover causal structure, rather than observing it passively." — Source: [Kempner Seminar Series (2026)]
- On causal representations: "We want to learn latent representations where individual dimensions correspond to independent causal factors of variation in the real world." — Source: [Vector Institute Lecture (2025)]
- On the intersection of fields: "Causality meets deep learning is one of the most exciting frontiers, because it forces us to combine rigorous statistical theory with high-capacity models." — Source: [Kempner Seminar Series (2026)]
- On limits of observational data: "No amount of data can overcome the fundamental limits of observational studies; sometimes, you simply must run an experiment to establish causality." — Source: [Vector Institute Lecture (2025)]
Part 6: Rethinking Evaluation and Test Accuracies
- On test-set accuracy: "The community has an over-reliance on test-set accuracy as a proxy for model quality, which hides fundamental flaws in how models generalize." — Source: [Allen School Distinguished Lecture (2024)]
- On benchmark saturation: "When a benchmark saturates, it rarely means the underlying problem is solved; it usually means the models have found shortcuts specific to that dataset." — Source: [Allen School Distinguished Lecture (2024)]
- On evaluating open-ended generation: "Evaluating translation and text generation is inherently difficult because there are many valid ways to say the same thing, making rigid string-matching metrics inadequate." — Source: [Allen School Distinguished Lecture (2024)]
- On learned evaluation: "We are moving toward a paradigm where we use learned models to evaluate other models, which introduces new challenges regarding bias and meta-evaluation." — Source: [Allen School Distinguished Lecture (2024)]
- On qualitative analysis: "Researchers must look at the actual outputs of their models. Staring at loss curves and aggregate metrics provides incomplete information about model behavior." — Source: [EMNLP 2019 Keynote]
- On dynamic benchmarks: "Static datasets degrade in utility over time due to data contamination; we need dynamic benchmarks that evolve to accurately measure progress." — Source: [Allen School Distinguished Lecture (2024)]
- On memorization vs generalization: "High test accuracy often masks the fact that large models are simply memorizing the training distribution rather than learning generalizable rules." — Source: [Allen School Distinguished Lecture (2024)]
- On the cost of evaluation: "As models become more capable, the human labor required to reliably evaluate them becomes the primary bottleneck in AI research." — Source: [Allen School Distinguished Lecture (2024)]
- On beyond accuracy metrics: "We should be evaluating models on their calibration, resilience to adversarial perturbations, and sample efficiency, moving away from relying on top-1 accuracy." — Source: [Allen School Distinguished Lecture (2024)]
Part 7: AI Hype, Existential Risk, and Real World Issues
- On existential risk narratives: "Narratives about AGI and extinction frequently distract from the real-world problems caused by current AI systems." — Source: [Personal Blog (2024)]
- On immediate harms: "We need more focus on the lack of regulation regarding immediate harms, such as bias, misinformation, and the displacement of labor." — Source: [Personal Blog (2024)]
- On the risk agenda: "The risk agenda should not be defined solely by a few influential figures; we need a broad, democratic discussion about what AI harms actually matter." — Source: [Personal Blog (2024)]
- On AI hallucinations: "Hallucinations in language models are closely connected to their ability to be creative; you cannot easily suppress one without hindering the other." — Source: [Technically Optimistic Podcast]
- On marginalized languages: "The development of AI heavily favors high-resource languages, and we must actively work to ensure marginalized languages are not left behind in the neural translation era." — Source: [Technically Optimistic Podcast]
- On open source AI: "Open research and open-source models are essential to prevent the consolidation of power and knowledge within a few large technology companies." — Source: [Technically Optimistic Podcast]
- On regulating AI: "Regulation should focus on specific applications and deployment contexts, like healthcare or finance, rather than attempting to regulate the underlying mathematics of algorithms." — Source: [Personal Blog (2024)]
- On AGI timelines: "Speculating on timelines for Artificial General Intelligence is largely unproductive; we have concrete technical hurdles to overcome today." — Source: [Technically Optimistic Podcast]
- On beneficial applications: "Instead of worrying about rogue AI, we should direct funding and talent toward using these tools to solve climate modeling, material science, and disease." — Source: [Personal Blog (2024)]
Part 8: Coding Agents, Education, and the Next Generation
- On classroom adoption: "I found it surprising that 80% of my 200 computer science students had never installed a coding agent on their machines." — Source: [Super Data Science Ep. 977]
- On teaching fundamentals: "Even with AI writing code, students must learn the fundamental concepts of computer science to verify, debug, and architect systems effectively." — Source: [Super Data Science Ep. 977]
- On adapting curricula: "We have to adapt our curricula to the reality that students will use these tools; assessing them purely on syntax recall is no longer viable." — Source: [Super Data Science Ep. 977]
- On AI assistance in research: "Coding agents will speed up the mechanical parts of research, allowing PhD students to spend more time thinking about experimental design and theory." — Source: [Super Data Science Ep. 977]
- On the future of programming: "Programming is shifting from writing lines of code to specifying constraints and evaluating the outputs generated by language models." — Source: [Super Data Science Ep. 977]
- On student reluctance: "Some students are hesitant to use AI tools because they fear it will prevent them from learning, which shows a healthy, albeit cautious, approach to education." — Source: [Super Data Science Ep. 977]
- On mentorship: "As a professor, my role is increasingly about guiding students on what problems are worth solving, moving beyond teaching them how to implement specific algorithms." — Source: [The Gradient Podcast Ep. 59]
- On the evolution of computer science: "Computer science is becoming a more empirical discipline, where studying the behavior of complex AI systems resembles experimental physics as much as it does mathematics." — Source: [The Gradient Podcast Ep. 59]