Marco Tulio Ribeiro is a computer scientist and researcher at Microsoft Research, known for his work in machine learning interpretability and NLP evaluation. He created LIME and CheckList, which are tools that force developers to examine why models make decisions rather than relying solely on accuracy metrics. This profile catalogs his insights on debugging language models, human AI collaboration, and the practical realities of academic writing.
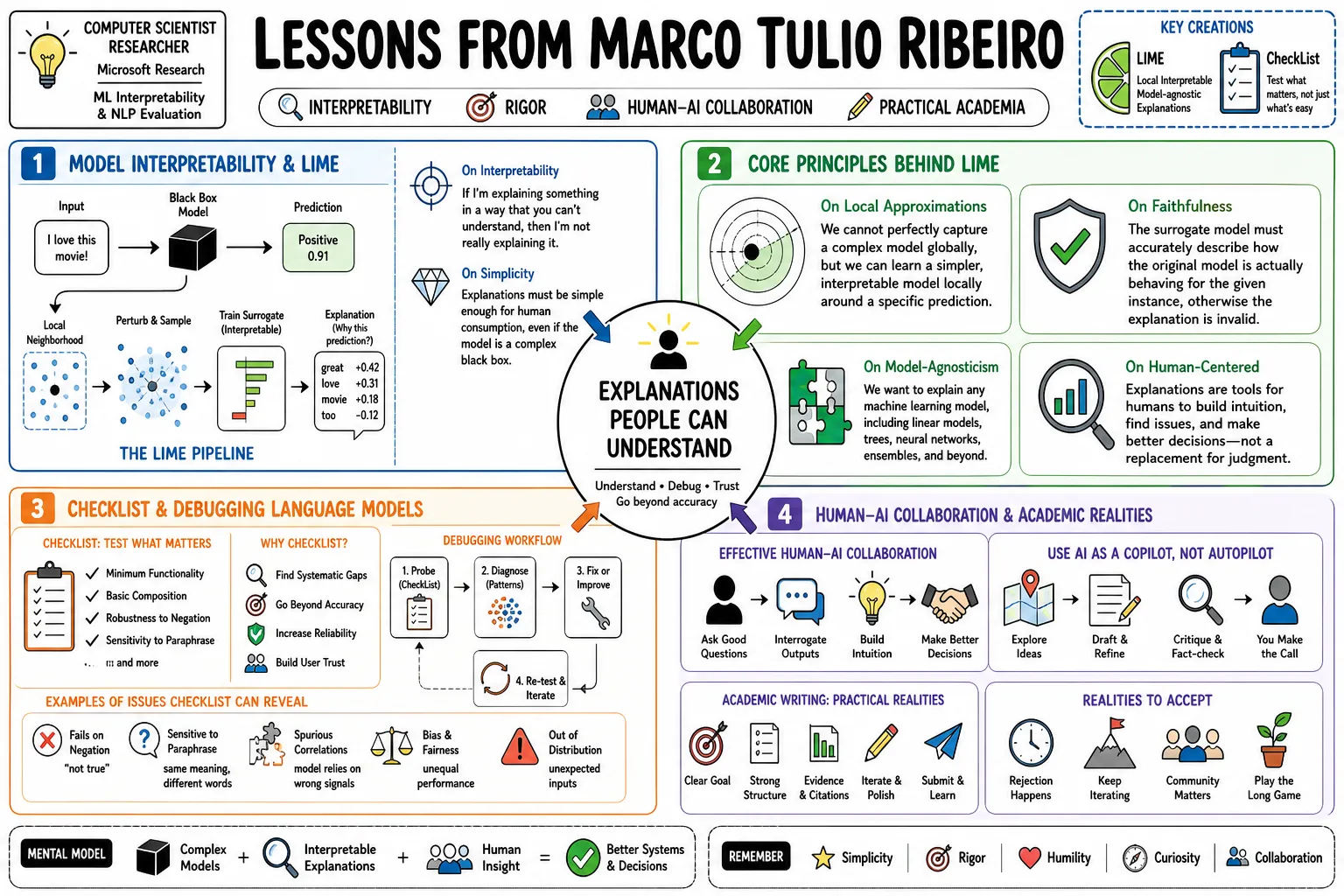
Part 1: Model Interpretability and LIME
- On Interpretability: "If I’m explaining something in a way that you can’t understand, then I’m not really explaining it." — Source: [Stanford MLSys Seminar]
- On Simplicity: "Explanations must be simple enough for human consumption, even if the underlying model is a highly complex black box." — Source: [Why Should I Trust You?]
- On Local Approximations: "We cannot perfectly capture a complex model globally, but we can learn a simpler, interpretable model locally around a specific prediction." — Source: [Why Should I Trust You?]
- On Faithfulness: "The surrogate model must accurately describe how the original model is actually behaving for the given instance, otherwise the explanation is invalid." — Source: [KDD 2016 Presentation]
- On Model-Agnosticism: "We want to explain any machine learning model, including those we have yet to invent, to allow for fair comparisons across different architectures." — Source: [Stanford MLSys Seminar]
- On Deployment Decisions: "Understanding the reasons behind predictions is fundamental when choosing whether to deploy a new model into the real world." — Source: [Why Should I Trust You?]
- On Actionable Insights: "An explanation is only useful if it provides the user with enough context to take an informed action based on the model's prediction." — Source: [Stanford MLSys Seminar]
- On Surrogate Boundaries: "If the approximation error is terrible, we must be honest and admit that we cannot explain that particular example." — Source: [Stanford MLSys Seminar]
- On Algorithmic Transparency: "Providing a complex decision tree might be technically accurate, but it fails the test of interpretability if a human cannot parse it." — Source: [KDD 2016 Presentation]
- On Feature Importance: "By perturbing the input and watching how the output changes, we can identify which specific features drove the model's decision." — Source: [Why Should I Trust You?]
Part 2: The Husky versus Wolf Problem
- On False Trust: "Humans have a strong tendency to trust models prematurely, often inventing logical reasons for a correct prediction even when the model used flawed logic." — Source: [Stanford MLSys Seminar]
- On Spurious Correlations: "A model trained to differentiate huskies from wolves may simply learn to detect snow in the background, completely ignoring the animal." — Source: [Why Should I Trust You?]
- On Black-Box Dangers: "High accuracy on a test set can mask severe underlying flaws, making blind trust in black-box models dangerous." — Source: [KDD 2016 Presentation]
- On Human Evaluation: "When humans are shown exactly what features a model relied on, they are much better at identifying when the model is failing." — Source: [Why Should I Trust You?]
- On Clever Hans Effect: "Machine learning models often act like the Clever Hans horse, picking up on unintended cues in the data rather than learning the actual task." — Source: [Stanford MLSys Seminar]
- On Debugging Reliance: "Without explanations, developers have no systematic way to identify why their model is making correct predictions for the wrong reasons." — Source: [Why Should I Trust You?]
- On User Psychology: "Users want to believe the AI is smart, so they will project human reasoning onto a model's output unless explicitly shown evidence to the contrary." — Source: [Human-Centered AI Seminar]
- On Dataset Bias: "The husky versus wolf problem is a failure of the training data, but it is the lack of interpretability that hides this failure from the researcher." — Source: [Why Should I Trust You?]
- On Trust Prerequisites: "Understanding the 'why' behind a model's decision is not an optional feature; it is a strict requirement for trusting the system." — Source: [KDD 2016 Presentation]
Part 3: Behavioral Testing and CheckList
- On Behavioral Testing: "Evaluating NLP models requires a behavioral testing framework inspired by software engineering, rather than relying solely on static datasets." — Source: [NLP Highlights Episode 114]
- On the CheckList Framework: "We need a task-agnostic methodology that allows developers to write unit tests for language models, just as they would for standard code." — Source: [Beyond Accuracy]
- On Minimum Functionality: "Minimum Functionality Tests are simple, targeted unit tests designed to check if a model possesses basic linguistic capabilities." — Source: [Beyond Accuracy]
- On Invariance Tests: "An NLP model's prediction should remain invariant when subjected to label-preserving perturbations, such as changing a character's name." — Source: [Beyond Accuracy]
- On Directional Expectations: "We can test models by applying perturbations where we expect the prediction to change in a specific, predictable direction." — Source: [NLP Highlights Episode 114]
- On Commercial Models: "When subjected to behavioral testing, even commercial models from major tech companies exhibit surprising failures on basic linguistic tasks." — Source: [Beyond Accuracy]
- On Matrix Evaluation: "CheckList organizes tests into a matrix of linguistic capabilities and test types, providing a structured map of a model's strengths and weaknesses." — Source: [Beyond Accuracy]
- On Shifting Paradigms: "We must move away from the assumption that independent and identically distributed test sets are sufficient for evaluating language models." — Source: [NLP Highlights Episode 114]
- On Developer Workflows: "Behavioral testing forces developers to explicitly define what behaviors they expect from their models before deploying them." — Source: [Beyond Accuracy]
- On Bug Discovery: "Structured behavioral tests regularly uncover bugs that would never be found by simply observing top-line accuracy metrics." — Source: [Beyond Accuracy]
Part 4: Moving Beyond Accuracy Metrics
- On the Accuracy Trap: "In NLP, many models achieve upwards of ninety percent accuracy on widely used benchmark test sets, and yet they still make simple mistakes." — Source: [Beyond Accuracy]
- On Goodhart's Law: "When accuracy on a specific benchmark becomes the target, it ceases to be a good measure of the model's actual linguistic understanding." — Source: [NLP Highlights Episode 114]
- On Solving Datasets: "The pretrain-finetune paradigm often results in models that are solving the dataset rather than actually solving the underlying task." — Source: [Beyond Accuracy]
- On Real-World Performance: "High scores on a leaderboard do not translate to reliability when the model encounters the messiness of real-world text." — Source: [Marco Tulio Ribeiro Medium]
- On Static Benchmarks: "Static test sets are inherently limited because they only test what the dataset creators happened to include, missing edge cases." — Source: [NLP Highlights Episode 114]
- On Aggregate Metrics: "A single aggregate accuracy score hides the specific sub-populations or linguistic phenomena where the model fails completely." — Source: [Beyond Accuracy]
- On Overestimating AI: "We overestimate the intelligence of our models because our evaluation metrics are too narrow to expose their brittleness." — Source: [Stanford MLSys Seminar]
- On the Illusion of Progress: "Beating the previous benchmark by one percent does not necessarily mean the model is actually better at language." — Source: [NLP Highlights Episode 114]
- On Granular Evaluation: "We need granular evaluations that break down language into discrete capabilities like negation, vocabulary, and named entity recognition." — Source: [Beyond Accuracy]
Part 5: Human-AI Collaboration and Debugging
- On AdaTest: "We can create a test-debug cycle by having humans and language models collaborate to find bugs in NLP models." — Source: [AdaTest Paper]
- On LLM Generators: "Large language models are excellent at generating a high volume of potential tests, vastly scaling up the debugging process." — Source: [AdaTest Paper]
- On Human Steering: "While language models generate the tests, the human user must steer the process by selecting valid tests and organizing them into coherent topics." — Source: [AdaTest Paper]
- On Adaptive Debugging: "Debugging should be adaptive, where the system learns from the tests the human approves to generate increasingly relevant failure cases." — Source: [AdaTest Paper]
- On the Cost of Manual Testing: "Writing behavioral tests entirely by hand is time-consuming; AI collaboration makes comprehensive testing feasible for small teams." — Source: [Marco Tulio Ribeiro Medium]
- On Auditing AI: "Auditing LLMs requires expert-level prompt templates to systematically uncover failure modes that random testing would miss." — Source: [AdaTest++ Paper]
- On In-Context Curation: "Humans can significantly improve a model's performance on specific tasks by iteratively curating in-context examples." — Source: [ScatterShot Research]
- On Synergy: "The human provides the domain expertise and the definition of a bug, while the model provides the scale and variation." — Source: [AdaTest Paper]
- On Fixing Bugs: "Finding a bug is only half the battle; the adaptive testing framework also helps generate the data needed to patch the model." — Source: [AdaTest Paper]
- On Continuous Evaluation: "Model evaluation is not a one-time step but a continuous, interactive loop between the human auditor and the AI system." — Source: [Marco Tulio Ribeiro Medium]
Part 6: Counterfactuals and Augmentation
- On Polyjuice: "Polyjuice provides a general-purpose counterfactual generator that allows users to control the type and location of text perturbations." — Source: [Polyjuice Paper]
- On Counterfactual Limits: "Simple perturbations like word swaps are insufficient for evaluating complex language tasks; we need more context-aware changes." — Source: [Polyjuice Paper]
- On Explaining via Change: "One of the best ways to explain a prediction is to show a counterfactual to reveal what minimal change to the input would flip the model's decision." — Source: [Polyjuice Paper]
- On Data Augmentation: "Generated counterfactuals can be fed back into the training process to create models that are more capable of handling linguistic variation." — Source: [Polyjuice Paper]
- On Fluency: "Counterfactual generators must prioritize fluency, ensuring that the perturbed text remains grammatically correct and natural." — Source: [Polyjuice Paper]
- On Fine-Tuning for Control: "By fine-tuning models like GPT-2 on paired sentence datasets, we can teach the system to apply specific structural changes on command." — Source: [Polyjuice Paper]
- On Evaluating Robustness: "Counterfactual testing reveals whether a model has learned the true causal factors of a task or just superficial correlations." — Source: [Polyjuice Paper]
- On Targeted Perturbations: "Researchers need the ability to specify that a generator should alter the sentiment of a sentence without changing its core subject." — Source: [Polyjuice Paper]
- On Human-Readable Explanations: "A well-crafted counterfactual serves as an intuitive explanation that requires no technical knowledge for an end user to understand." — Source: [Polyjuice Paper]
Part 7: Prompt Engineering and Language Models
- On Prompt Boundaries: "Prompt engineering often fails because language models struggle to distinguish between the instruction and the data within the prompt." — Source: [Marco Tulio Ribeiro Medium]
- On Prompts as Code: "We must treat prompts like software code, applying the same rigor of version control, modularity, and systematic testing." — Source: [Marco Tulio Ribeiro Medium]
- On the Guidance Library: "Using tools like the Guidance library allows developers to impose strict syntax and constraints, forcing models to generate programmatically parseable output." — Source: [Guidance GitHub Repository]
- On Prompt Hacking: "The field needs to move past ad-hoc prompt hacking and develop reproducible methodologies for controlling language models." — Source: [Marco Tulio Ribeiro Medium]
- On Tokenization Biases: "The way text is tokenized can introduce hidden biases in how a model interprets a prompt, leading to unexpected behavior." — Source: [Marco Tulio Ribeiro Medium]
- On Instruction Following: "Providing clear syntax and structural boundaries in a prompt drastically improves a model's ability to follow complex instructions." — Source: [Marco Tulio Ribeiro Medium]
- On Output Constraints: "To build reliable applications, developers must be able to constrain the model's output space to specific formats, like valid JSON." — Source: [Guidance GitHub Repository]
- On Iterative Refinement: "Drafting a good prompt is an iterative process of testing edge cases and refining the wording based on model failures." — Source: [Marco Tulio Ribeiro Medium]
- On Template Design: "Expert-level prompt templates require a deep understanding of how the model's attention mechanism allocates weight to different parts of the context." — Source: [Marco Tulio Ribeiro Medium]
Part 8: The Research and Writing Process
- On Writing as Discovery: "Writing is not just transcribing thoughts; it is a discovery process that forces you to uncover flaws in your reasoning." — Source: [Marco Tulio Ribeiro Medium]
- On Hierarchical Structure: "Effective writing happens at multiple levels from the sentence to the paragraph to the section, and each requires dedicated attention." — Source: [Marco Tulio Ribeiro Medium]
- On Outlines: "Writing without an outline leads to disorganized, stream-of-consciousness text that frustrates the reader." — Source: [Marco Tulio Ribeiro Medium]
- On Iterative Drafting: "You must accept a cycle of writing, outlining, reading, and rewriting; the first draft is never the final product." — Source: [Marco Tulio Ribeiro Medium]
- On Incomplete Knowledge: "A realistic writing process assumes that you do not possess all the necessary information when you begin drafting." — Source: [Marco Tulio Ribeiro Medium]
- On Idea Generation: "Generating research ideas requires exposing yourself to practical problems rather than just reading theoretical papers." — Source: [Marco Tulio Ribeiro Medium]
- On Evaluating Ideas: "When evaluating a research idea, you must be problem-oriented, asking if the issue is actually worth solving before designing a solution." — Source: [Marco Tulio Ribeiro Medium]
- On Thesis Topics: "The best research topics often emerge organically from the friction encountered during hands-on internships or applied projects." — Source: [Marco Tulio Ribeiro Medium]
- On Reader Empathy: "Re-outlining your own text is the best way to determine if a reader will actually be able to follow your argument." — Source: [Marco Tulio Ribeiro Medium]