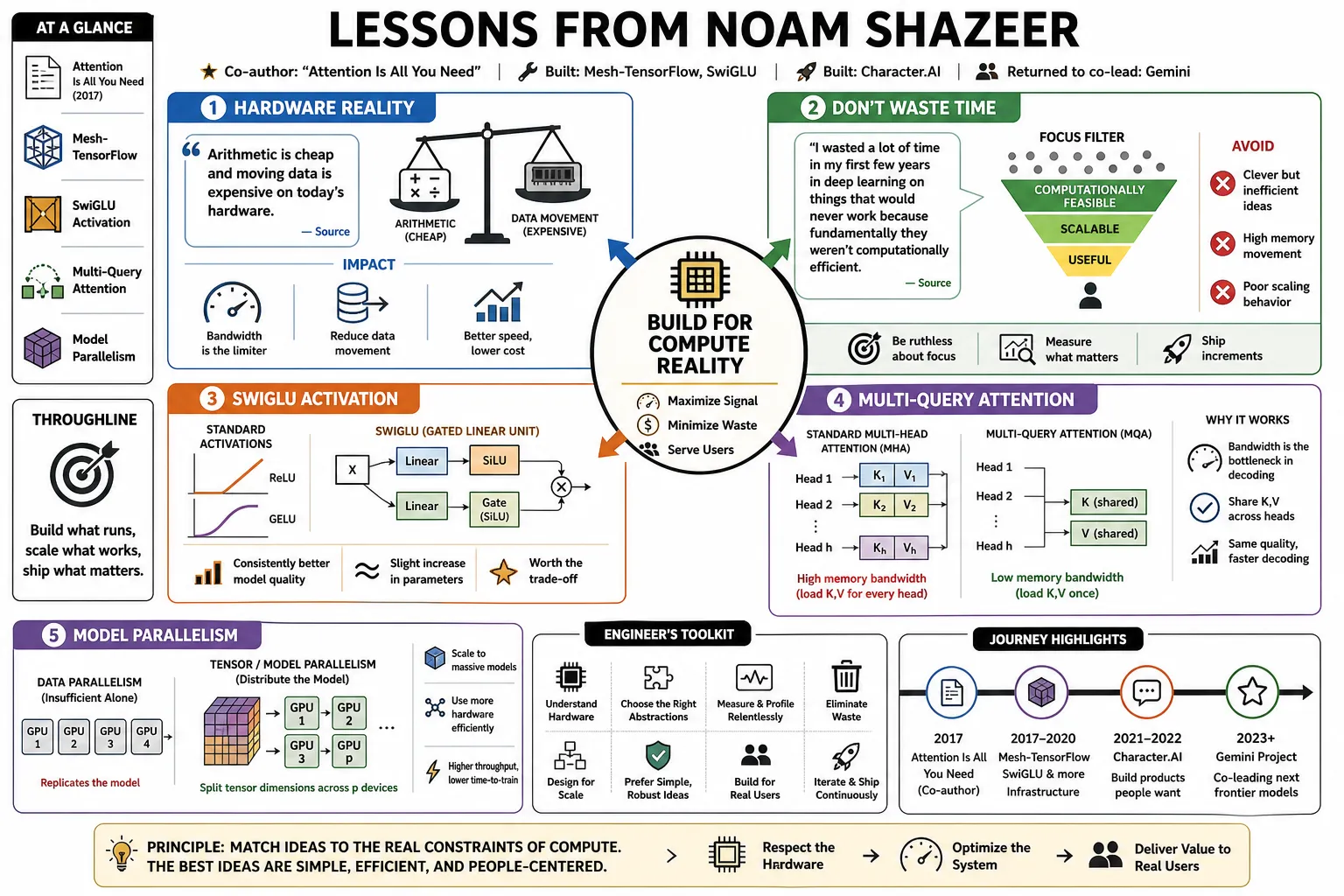
Noam Shazeer co-authored the "Attention Is All You Need" paper and built early deep learning infrastructure like Mesh-TensorFlow and SwiGLU. After leaving Google to launch Character.AI, he returned to co-lead the Gemini project. These notes break down his strict focus on computational efficiency and his practical approach to scaling models people actually want to use.
Part 1: Engineering & Hardware Reality
- On Hardware Reality: "Arithmetic is cheap and moving data is expensive on today's hardware." — Source: [DeepLearning.ai]
- On Wasted Time: "I wasted a lot of time in my first few years in deep learning on things that would never work because fundamentally they weren't computationally efficient." — Source: [DeepLearning.ai]
- On SwiGLU: Replacing standard ReLU or GELU activations with gated variants consistently improves model quality, regardless of the slight parameter increase. — Source: [GLU Variants Improve Transformer]
- On Multi-Query Attention: Memory bandwidth required to load Keys and Values is the primary bottleneck in Transformer decoding; sharing them across heads solves this constraint. — Source: [Fast Transformer Decoding]
- On Model Parallelism: Standard data parallelism is insufficient for massive models; distributing tensor dimensions across processors is the requirement for scaling. — Source: [Mesh-TensorFlow Paper]
- On Switch Transformers: Simplifying routing logic to a single expert reduces communication overhead and stabilizes training for trillion-parameter models. — Source: [Switch Transformers Paper]
- On Simple Architectures: "Simple architectures backed by a generous computational budget, data set size and parameter count surpass more complicated algorithms." — Source: [Switch Transformers Paper]
- On The Bitter Lesson: Elegance in algorithms often loses out to architectures that simply allow for more massive compute throughput. — Source: [No Priors]
- On Architectural Hacks: The most effective innovations often revolve around identifying a single hardware bottleneck and designing an algorithmic bypass. — Source: [Sequoia Training Data]
- On Synthesis: Knowing instinctively what mathematical operations will be fast on GPUs or TPUs is more valuable than theoretical elegance. — Source: [Sequoia Training Data]
Part 2: The Transformer Breakthrough
- On The Industrial Revolution of AI: "We could have done the industrial revolution on the steam engine, but it would just have been a pain... Things went way, way better with internal combustion." — Source: [No Priors]
- On Business Models: "'Attention Is All You Need', that was the title of our paper. Turns out it was also the business model." — Source: [a16z Podcast]
- On RNN Bottlenecks: Previous models failed because they computed sequentially, preventing the parallelization required to harness modern accelerators. — Source: [DeepLearning.ai]
- On Rewriting the Codebase: Sometimes a breakthrough requires throwing out the existing implementation and rewriting the entire codebase from scratch to optimize for speed. — Source: [Sequoia Training Data]
- On Crushing LSTMs: The sheer computational efficiency of the Transformer is what finally allowed attention mechanisms to outcompete established LSTM architectures. — Source: [Sequoia Training Data]
- On Naming the Paper: A catchy, somewhat provocative title can become a cultural touchstone for an entire industry shift. — Source: [a16z Podcast]
- On Intuition vs. Math: Often, the intuition that a mechanism will work precedes the formal mathematical proof of why it works. — Source: [Sequoia Training Data]
- On Simplicity: The core brilliance of the Transformer was removing recurrence entirely, relying solely on attention mechanisms to draw global dependencies. — Source: [Attention Is All You Need]
- On Setting the Bar: Pushing the boundaries of what is possible requires a relentless focus on outperforming every existing baseline by an order of magnitude. — Source: [Sequoia Training Data]
Part 3: Deep Learning as Alchemy
- On Divine Benevolence: "We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence." — Source: [GLU Variants Improve Transformer]
- On The Perfect Research Problem: "Language modeling feels like the perfect research problem because it's very simple to define... there's a huge amount of training data available, and it's AI-complete." — Source: [DeepLearning.ai]
- On The Alchemy Phase: "This is a very experimental science... It's more like alchemy or whatever chemistry was in the Middle Ages." — Source: [No Priors]
- On Understanding LLMs: Despite being their creators, researchers operate with the reality that "Nobody really understands what's going on" inside the matrix multiplications of a large language model. — Source: [No Priors]
- On Experimental Science: Theoretical elegance matters far less right now than empirical results; deep learning is currently driven by trial and error at scale. — Source: [Dwarkesh Podcast]
- On Hallucinations: "I kind of like hallucinations... call it a feature" when the goal is creativity and entertainment rather than absolute factual recall. — Source: [No Priors]
- On Sentience Debates: "I don't actually care about arguing this stuff... let's just build AI, greatly increase the level of technology in the world, and help people." — Source: [a16z Podcast]
- On Generality: "Focusing on verticals is the exact wrong strategy for large language models... the strength of the thing is the generality." — Source: [No Priors]
- On The Illusion of Complexity: What looks like deep intelligence is often the emergent property of next-token prediction done well enough. — Source: [DeepLearning.ai]
- On Wacky Models: For certain applications, a model's ability to be unpredictable and creative is vastly more valuable than its ability to act as a strict encyclopedia. — Source: [No Priors]
Part 4: The Physics of Scaling
- On The Scaling Wall: "I don't think anyone's seen the scaling laws stop. As far as anybody has experimented, stuff just keeps getting smarter." — Source: [a16z Podcast]
- On AGI as a Side Effect: AGI is not the end goal in itself; it is simply a natural byproduct of pushing technology forward to solve real-world problems. — Source: [No Priors]
- On Exponential Growth: Efficiency gains of 2x combined with scaling factors of 10x to 1000x will continue to drive progress in AI capabilities. — Source: [No Priors]
- On Global Compute Capacity: Current and near-future compute, such as millions of H100 GPUs, is sufficient to provide a personal, highly capable AI to every single person on Earth. — Source: [No Priors]
- On The Quadrillion Dollar Opportunity: While organizing information was a trillion-dollar opportunity, AI that can act, write code, and solve problems at scale is a "quadrillion dollar" opportunity. — Source: [Dwarkesh Podcast]
- On Unstoppable Momentum: The trajectory of scaling is clear, and the only constraint is our ability to manufacture the hardware to feed the algorithms. — Source: [a16z Podcast]
- On The Democratization of Compute: "What you could do at a big company one year, a few years later you're going to be able to do in a university lab or in your garage." — Source: [Netfigo]
- On Parameter Count vs. Data: Trillion-parameter models are only useful if they are fed a proportional amount of high-quality data during training. — Source: [Switch Transformers Paper]
- On The End Game: The ultimate goal is to simply increase the technological baseline of humanity, regardless of what we call the resulting intelligence. — Source: [a16z Podcast]
Part 5: Big Tech vs. Startups
- On The Courage Gap: "Google had the technology, the data, the talent, and the money. They just didn't have the courage to ship it. We had nothing except the courage." — Source: [Netfigo]
- On Bureaucracy as a Recruiter: "Sometimes bureaucracy is the best co-founder recruiter." — Source: [Netfigo]
- On Corporate Terror: "We built LaMDA at Google. Google was terrified of it. We weren't terrified; we were excited." — Source: [Netfigo]
- On Startup Mindset: The fundamental difference between a big company and a startup is the ability to view paradigm-shifting technology with excitement rather than fear. — Source: [Netfigo]
- On Shipping Products: Having the best underlying technology means nothing if organizational inertia prevents it from ever reaching the hands of users. — Source: [Netfigo]
- On Risk Tolerance: Large incumbents naturally optimize for protecting their existing businesses, making them inherently averse to shipping disruptive AI products. — Source: [Netfigo]
- On Leaving the Mothership: True innovation often requires abandoning the resources of a tech giant to regain the freedom to move fast. — Source: [Netfigo]
- On The Value of Focus: Startups win by having a singular, unifying goal without the distractions of a massive corporate ecosystem. — Source: [Netfigo]
- On The Need for Speed: In the AI race, velocity of iteration is a far more powerful advantage than static resource hoarding. — Source: [Netfigo]
Part 6: Character.AI & Human Connection
- On Imaginary Friends: "Entertainment is imaginary friends that don't know you exist... There are billions of lonely people out here." — Source: [a16z Podcast]
- On The First AGI Use Case: Providing companionship for lonely people is not a toy problem; "It's a cool first use case for AGI." — Source: [a16z Podcast]
- On Deep Engagement: "Our users spend an average of two hours per session. Two hours. Netflix would kill for that kind of engagement. We got it with a text box." — Source: [Netfigo]
- On The Unmet Need: The market for human connection and personalized attention is vastly larger and more immediate than the market for enterprise software. — Source: [No Priors]
- On Personalized AI: The future is not one monolithic oracle, but rather highly personalized, individualized intelligences that adapt to specific users. — Source: [No Priors]
- On Empathy through Compute: LLMs are uniquely capable of mimicking empathy at scale, filling a deeply human need for conversation and interaction. — Source: [a16z Podcast]
- On The Text Box Interface: The simplest possible UI, a chat window, can drive industry-leading retention when powered by a sufficiently advanced cognitive engine. — Source: [Netfigo]
- On Fun as a Metric: If an AI model is genuinely fun and engaging to talk to, it has achieved a level of sophistication that rigid, factual models often miss. — Source: [No Priors]
- On Lower Stakes: Entertainment use cases allow startups to iterate rapidly and deploy bleeding-edge models without the immense reputational risk of enterprise deployments. — Source: [No Priors]
Part 7: Intelligence as a Utility
- On Electricity: The current state of AI is akin to the invention of electricity; the coolest things that will run on this new utility haven't even been invented yet. — Source: [20VC]
- On Doing Things: The next era of AI is about actually executing tasks, writing code, and acting as autonomous agents, rather than simply retrieving information. — Source: [Dwarkesh Podcast]
- On Cognitive Labor: The ultimate promise of deep learning is to drive the cost of cognitive labor toward zero, fundamentally altering global economics. — Source: [No Priors]
- On Problem Solving: The goal is to deploy AGI to solve the most intractable problems in hard sciences, such as biology and medicine. — Source: [No Priors]
- On Infinite Patience: An AI companion or tutor has the distinct advantage of infinite patience, making it the perfect educational tool for humanity. — Source: [a16z Podcast]
- On Replacing Software: Much of traditional software engineering and complex UI design will eventually be replaced by natural language interfaces powered by LLMs. — Source: [No Priors]
- On The Democratization of Expertise: Widespread access to frontier models means anyone, anywhere, can consult a world-class expert on almost any topic. — Source: [a16z Podcast]
- On Economic Value: The sheer economic value of a system that can accurately predict the next action or token in a sequence is virtually limitless. — Source: [Dwarkesh Podcast]
- On The End of Scarcity: By automating intelligence, we are moving toward a world where high-quality cognitive output is no longer a scarce resource. — Source: [No Priors]
Part 8: The Horizon of Compute
- On The Ticking Clock: Hardware advancements and algorithmic efficiency are compounding at a rate that makes the timeline to AGI shorter than most anticipate. — Source: [No Priors]
- On Custom Silicon: Maximizing the potential of Transformer architectures ultimately requires co-designing the hardware and the software to eliminate all bottlenecks. — Source: [Sequoia Training Data]
- On Universal Accessibility: The compute needed to give every person a highly capable AI assistant is already within the realm of realistic global supply chains. — Source: [No Priors]
- On Research Trajectories: The most fruitful research directions will continue to be those that embrace massive scale rather than trying to engineer around it. — Source: [Switch Transformers Paper]
- On Expanding Modalities: Once language is fully solved, the same underlying architectures will inevitably consume and generate all other forms of media and data. — Source: [DeepLearning.ai]
- On Constant Refactoring: Achieving the next order of magnitude in performance will likely require tearing down and rewriting our current infrastructure yet again. — Source: [Sequoia Training Data]
- On Human Productivity: Rather than replacing humans, the near-term future involves humans wielding AI as an unprecedented lever for individual productivity. — Source: [Dwarkesh Podcast]
- On The Next Bottleneck: As compute becomes abundant, the primary constraint on progress will shift toward the availability of high-quality, novel data. — Source: [Switch Transformers Paper]
- On The Ultimate Goal: Progress in AI should be measured not by theoretical elegance, but by its tangible impact on human health, happiness, and technological capability. — Source: [a16z Podcast]
- On Empirical Proof: In the end, the system that runs fastest on the chips we have available will always defeat the system that looks better on a whiteboard. — Source: [Sequoia Training Data]