Oriol Vinyals is a Vice President of Research at Google DeepMind and a lead developer of the Gemini model. He is known for co-authoring the "Sequence to Sequence" paper, which formed the basis of modern machine translation, and for directing the AlphaStar and Gato projects. This compilation organizes his insights on language modeling, reinforcement learning, and generalist AI across his career.
Part 1: Sequence to Sequence Learning & NLP
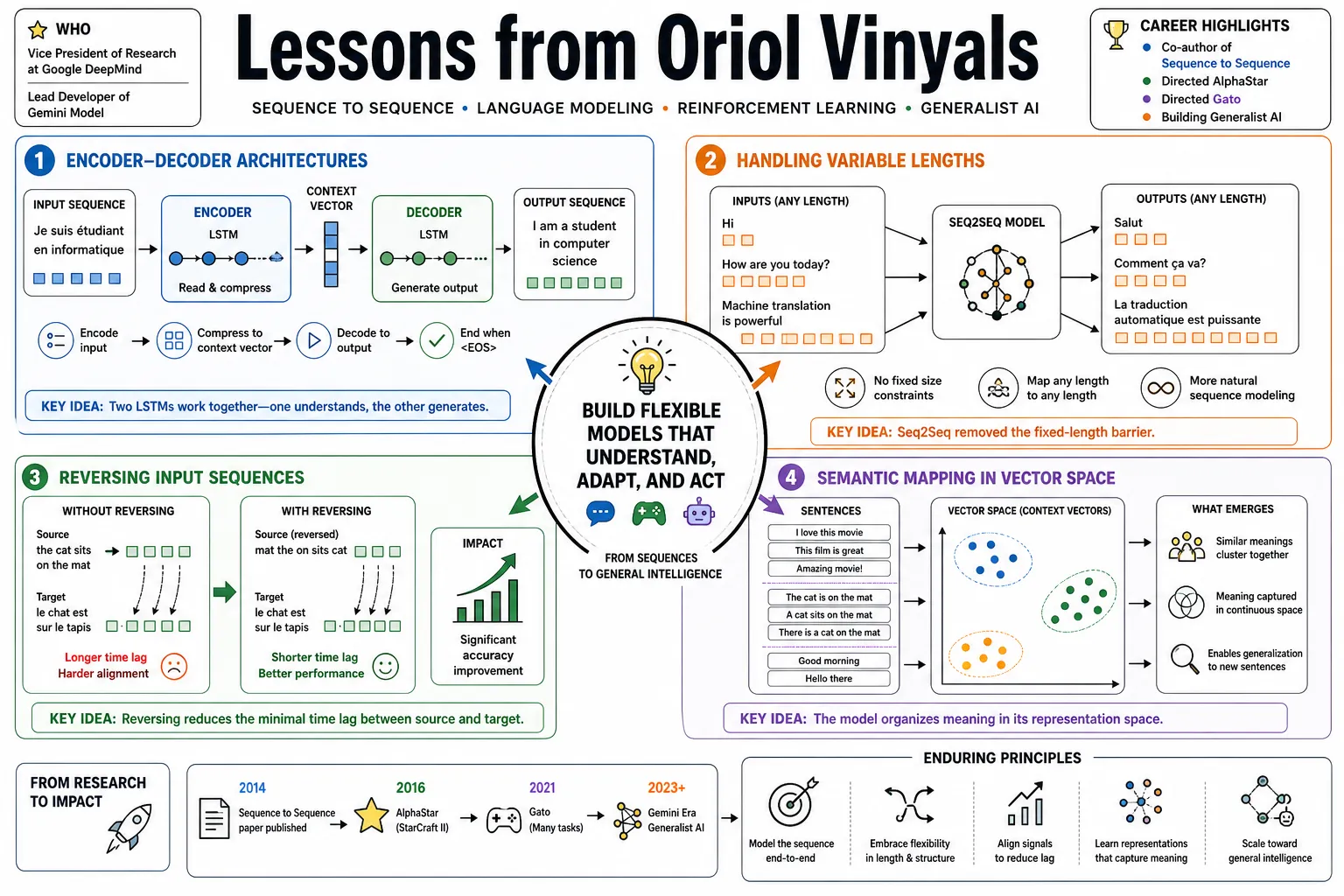
- On Encoder-Decoder Architectures: "The model uses two separate Long Short-Term Memory networks: one processes the input sequence to compress it into a vector, and the other takes this context vector to generate the output." — Source: [arXiv]
- On Handling Variable Lengths: "Deep Neural Networks typically required fixed-size inputs and outputs, but the Seq2Seq framework allowed models to map input sequences of any length to output sequences of any length." — Source: [NeurIPS]
- On Reversing Input Sequences: "Reversing the order of words in the input sentence significantly improved performance by reducing the minimal time lag between the source and target." — Source: [arXiv]
- On Semantic Mapping: "The model naturally clustered sentences with similar meanings together in the vector space, regardless of whether they were in active or passive voice." — Source: [GitHub]
- On Scalability of LSTMs: "Deep LSTMs can effectively handle long-range dependencies in text, which had been a major hurdle for previous recurrent neural networks." — Source: [arXiv]
- On Grammar Parsing: "Sequence to Sequence can be used for syntactic parsing, treating grammar structures almost like a foreign language." — Source: [ResearchGate]
- On Pointer Networks: "A variation of Seq2Seq can be designed to solve combinatorial optimization problems like the Traveling Salesman Problem." — Source: [NeurIPS]
- On End-to-End Language Tasks: "Training an end-to-end neural net fully using stochastic gradient descent simplified traditional NLP pipelines." — Source: [arXiv]
- On Outperforming Older Systems: "By achieving a BLEU score of 34.8 on the WMT'14 task, it outperformed traditional phrase-based Statistical Machine Translation systems of the time." — Source: [arXiv]
- On Information Compression: "Compressing a sentence into a single, fixed-length vector representation forces the model to capture the core meaning before translating." — Source: [arXiv]
Part 2: AlphaStar & Reinforcement Learning in Games
- On Grand Challenges: "I thought well this sounds impossible. And it probably is impossible to do the full thing... but I could see some stepping stones." — Source: [Lex Fridman Podcast]
- On Game Complexity: "StarCraft is way harder than Go. Philosophically and mathematically speaking." — Source: [Lex Fridman Podcast]
- On Required Environments: "Environments must be challenging and interesting for our agents to become interesting in them." — Source: [Lex Fridman Podcast]
- On AI Fairness: "While AlphaStar has excellent and precise control, it doesn't feel superhuman... Overall, it feels very fair—like it is playing a 'real' game of StarCraft." — Source: [DeepMind Blog]
- On Human Scale vs RL: "The scale of humans that play Blizzard games is almost on the scale of a large-scale DeepMind RL experiment." — Source: [YouTube]
- On Imperfect Information: "StarCraft II was chosen because it requires real-time decision-making, long-term planning, and managing imperfect information like the fog of war." — Source: [DeepMind Blog]
- On Winning vs Imitating: "Reinforcement learning allows models to figure out what it means to win, moving beyond mere imitation of human data." — Source: [Lex Fridman Podcast]
- On Action Spaces: "The challenges of training agents in environments with massive action spaces require moving beyond traditional board game algorithms." — Source: [Lex Fridman Podcast]
- On Games as Proving Grounds: "Video games serve as the perfect proving ground for AI due to their constrained but highly complex rule sets." — Source: [Lex Fridman Podcast]
Part 3: Gato & Generalist Agents
- On Unified Brains: "Gato basically can be thought of as inputs: images, text, video, actions... it's this brain that essentially you give it any sequence of these observations and modalities and it outputs the next step." — Source: [Lex Fridman Podcast]
- On Algorithmic Simplicity: "You're just optimizing these weights via a very simple gradient... it's almost the most boring algorithm you could imagine." — Source: [Lex Fridman Podcast]
- On the Core Recipe: "The recipe hasn't changed too much: there is a transformer model... its own objective that you train it to do is to predict what the next anything is." — Source: [OpenReview]
- On Tokenizing Everything: "Anything means: what's the next action? What's the next observation? You think of this really as a sequence of bytes." — Source: [Lex Fridman Podcast]
- On Multi-Embodiment: "The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more." — Source: [DeepMind Research]
- On Contextual Output: "The model decides based on its context whether to output text, joint torques, button presses, or other tokens." — Source: [DeepMind Research]
- On Model Evolution: "We should not be training models from scratch every few months... there should be some sort of way in which we can grow models much like as a species." — Source: [Lex Fridman Podcast]
- On Iterative Building: "Building from the previous iterations allows us to stop discarding the vast amounts of computational effort spent on older models." — Source: [Lex Fridman Podcast]
- On Generalist Adaptation: "Training an agent which is generally capable on a large number of tasks is possible; and this general agent can be adapted with little extra data to succeed at an even larger number of tasks." — Source: [Lex Fridman Podcast]
- On Dataset Mixing: "By mixing datasets from robotics, games, and language, the model learns a more robust representation of intelligence than a specialist ever could." — Source: [Lex Fridman Podcast]
Part 4: Show and Tell & Multimodality
- On the Image Captioning Challenge: "Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing." — Source: [CMU Publication]
- On Image as Language: "It is natural to use a CNN as an image 'encoder', by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences." — Source: [CV Foundation]
- On End-to-End Generation: "We present an end-to-end system for the problem. It is a neural net which is fully trainable using stochastic gradient descent." — Source: [arXiv]
- On Pipeline Inefficiencies: "End-to-end generation systems are superior to traditional pipeline systems that use separate object detectors or simply pick existing captions from a database." — Source: [arXiv]
- On Accessibility Applications: "Being able to automatically describe the content of an image could help visually impaired people better understand the content of images on the web." — Source: [Peking University]
- On the NIC Architecture: "NIC, our model, is based end-to-end on a neural network consisting of a vision CNN followed by a language generating RNN. It generates complete sentences in natural language from an input image." — Source: [CV Foundation]
- On Target Likelihood: "The model was designed to maximize the likelihood of the target description sentence given the training image." — Source: [arXiv]
- On Language Fluency: "A major goal was ensuring the fluency of the language it learns solely from image descriptions, moving away from the rigid, canned descriptions of earlier AI." — Source: [arXiv]
- On Modality Translation: "Treating the image as the source language and the caption as the target language reframes vision as a translation task." — Source: [arXiv]
Part 5: AlphaCode & AI for Software Engineering
- On Initial Skepticism: "I must say in early 2021 that we could achieve a level of performance that we achieved which is not perfect but it starts to be at human level... I really was quite skeptical." — Source: [ResearchGate]
- On Domain Difficulty: "I chose AlphaCode because it represents kind of a very difficult accomplishment I think from what we thought it was possible or not... achieving the level of the degree of performance in these coding competitions." — Source: [ResearchHub]
- On Problem Solving vs Translation: "Going from 'what the problem is' to 'how to solve the problem' is a great leap that requires understanding and reasoning about the problem, as well as a deep comprehension of a wide range of algorithms." — Source: [Google APIs]
- On Automated Code Evaluation: "It’s nice that you have this way to automatically know if your model is better or not because you can evaluate it without any subjectiveness... if it passes all the tests, you hope that your code is correct." — Source: [ResearchGate]
- On Transforming Tooling: "Developing AI systems that can effectively model and understand code can transform these tools and the way we interact with them." — Source: [Google APIs]
- On Code as a Stepping Stone: "Systems that can generate code are not only useful, but also stepping stones that can lead to greater understanding of AI and how it relates to programming." — Source: [Medium]
- On Competitive Milestones: "Reaching the top 54.3% of participants marks the first time an AI has reached a competitive human level in this domain." — Source: [Medium]
- On Algorithm Invention: "Competitive programming requires inventing an algorithm, which is significantly more complex than simple code completion." — Source: [ResearchHub]
- On Objective Metrics: "The ability to run unit tests provides a stark, undeniable metric of success that language generation often lacks." — Source: [ResearchGate]
Part 6: Gemini & Scaling Limits
- On Merging Teams: "Earlier in the year there was an effort to merge the two projects [Google Brain and legacy DeepMind]. That's when sort of Jeff [Dean] and I came together... to create the very first Gemini model." — Source: [YouTube]
- On the Gemini Mission: "The goal of Gemini itself is to create an awesome core model to power the technology that of course LLMs today are powering all around the world." — Source: [YouTube]
- On Continuing Scaling Returns: "Contra the popular belief that scaling is over... the team delivered a drastic jump. The delta between 2.5 and 3.0 is as big as we've ever seen. No walls in sight!" — Source: [OfficeChai]
- On Post-Training Opportunities: "Post-training: Still a total greenfield. There's lots of room for algorithmic progress and improvement." — Source: [OfficeChai]
- On Architectural Tricks: "Gemini has got better but not only because we scaled... we have other innovations like other tricks, techniques, details about how to order the data... to the details of the architecture." — Source: [YouTube]
- On Infinite Context: "Infinite context length is coming eventually... seeing the use cases just emerge even internally when we were first just trying the model... that seems very trivial now in hindsight." — Source: [YouTube]
- On Working Memory: "Computers certainly have advantages we should build on its strengths... the fact that they can have literally [the whole web] in memory." — Source: [YouTube]
- On Diminishing Naive Returns: "The first 10 minutes that you spend tidying, it's going to make a massive difference. But once you're like 7 hours in, that extra 10 minutes, it's not going to make any difference at all." — Source: [36kr AI]
- On Foundation V1: "It’s a new era for us. We’re breaking ground from a research perspective. This is V1. It’s just the beginning." — Source: [YouTube]
Part 7: AGI, Sentience & Philosophy
- On Redefining AGI: "I’m not sure it matters that we achieved AGI... it’s going to be a distribution of things that these models can do or can’t do. We need to be ready to not be too fixated on AGI." — Source: [YouTube]
- On the Secret Lab Perspective: "If 10 years ago... I would have been given the models today... I would have claimed, oh, yeah, that comes from a future where AGI basically either has happened or I can see that this is very close to it." — Source: [YouTube]
- On Sentience vs Tooling: "There is a philosophical debate on whether neural networks can be considered 'beings' versus tools, especially as they become more autonomous." — Source: [Lex Fridman Podcast]
- On Passive Observers: "Current models are mostly passive observers; the potential lies in agents that experience and optimize their own lifetimes." — Source: [Lex Fridman Podcast]
- On Specialization vs Generality: "If the problem is worth it, then let's obviously specialize... we might see more and more bootstrapping from Gemini... to a specific solution that the model is going to be throwaway except for cracking protein folding or figuring out nuclear fusion." — Source: [YouTube]
- On Redefining Human Talent: "Adapting to constant change is now a more highly valued talent than, for example, calculating 500-digit numbers." — Source: [Ara.cat]
- On Tool Proficiency as Talent: "If someone today uses an AI tool very well and the result they obtain is excellent, that too is a talent." — Source: [Ara.cat]
- On Critical Thinking Security: "We need knowledge to be able to question what AI tells us, re-evaluate, correct, and be critical. In the future, it won't make mistakes, but it does now." — Source: [Ara.cat]
- On Agentic Scaling Laws: "The next major step is giving models a digital body—moving from passive language models to autonomous agents that can plan, reason, and interact with the world." — Source: [36kr AI]
- On Unexpected Abilities: "The emergence of unexpected abilities in models like Flamingo and Chinchilla suggests that scale unlocks latent reasoning skills." — Source: [Lex Fridman Podcast]
Part 8: Research Methodology & Engineering Practices
- On Test-Time Compute: "Scaling through test-time compute, allowing models to 'think' longer during inference, is a new frontier for problem-solving." — Source: [36kr AI]
- On End-to-End Tradeoffs: "While end-to-end systems are mathematically elegant, they require massive datasets to overcome the lack of explicit, hand-coded rules." — Source: [arXiv]
- On Reinforcement Learning as the Next Law: "RL is the mechanism that figures out what it means to win or solve a problem, effectively creating a new scaling law for intelligence." — Source: [36kr AI]
- On Meta-Learning: "AI must 'learn to learn' and adapt to new tasks with minimal data if it is to mimic true biological adaptability." — Source: [Lex Fridman Podcast]
- On Data Ordering: "Tricks, techniques, and details about how to order the data are just as vital as raw compute in achieving intelligence." — Source: [YouTube]
- On Discarding Compute: "It is incredibly inefficient to throw away the weights and learnings of previous massive models when starting the next generation." — Source: [Lex Fridman Podcast]
- On Breaking Conventional Rules: "Reversing the input sequence in Seq2Seq proved that standard intuitions about data presentation are sometimes wrong in deep learning." — Source: [arXiv]
- On Cross-Pollination of Teams: "Bringing together different research cultures—like DeepMind and Google Brain—was essential to building Gemini's foundational stack." — Source: [YouTube]
- On Unsubjective Evaluation: "When building code-generation or game-playing agents, having an environment that tells you immediately if you succeeded removes researcher bias." — Source: [ResearchGate]