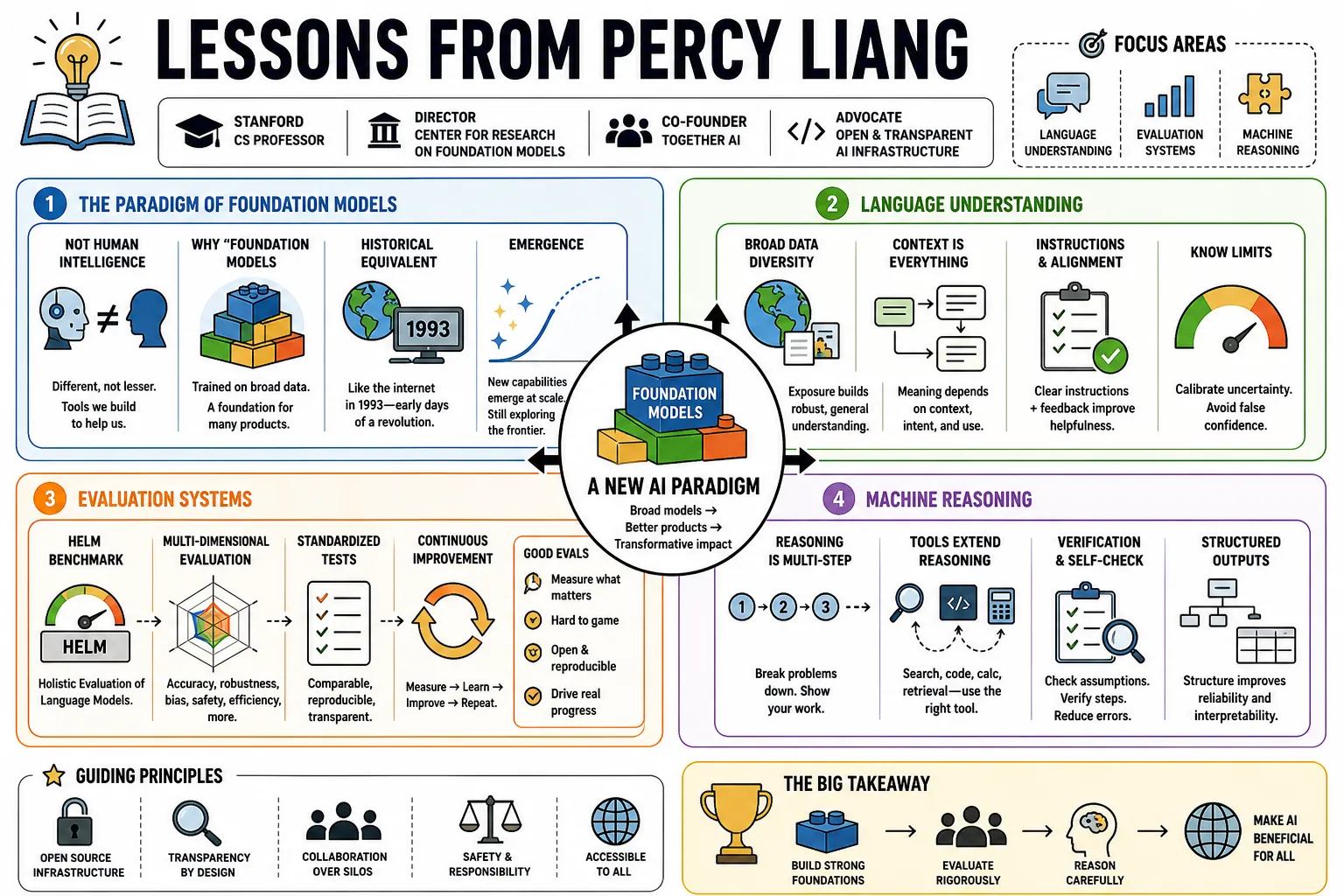
Percy Liang defined the concept of foundation models and built the HELM benchmark to evaluate them. A Stanford computer science professor, director of the Center for Research on Foundation Models, and Together AI co-founder, he advocates for transparent, open-source AI infrastructure. This profile collects his perspectives on language understanding, evaluation systems, and machine reasoning.
Part 1: The Paradigm of Foundation Models
- On the distinction between ML and human intelligence: "I think it's absolutely right to think of machine learning AI as not chasing human intelligence, but more — they're a different thing... tools that we build to help us." — Source: [Behind the Tech]
- On naming the era: "The term large language models doesn't really underscore the importance... we called it foundation models, because we felt like there's a paradigm shift where we all of a sudden have these huge models trained on broad data, which served as a foundation for developing other products." — Source: [Stanford Engineering]
- On historical equivalents: "AI today is kind of like where we were with the internet in 1993. We were at the beginning of a revolution that would change the world." — Source: [AI2050]
- On emergence: He notes that emergence catches researchers by surprise—the fact that simply training a model to predict the next token can result in answering questions and summarizing text. — Source: [Stanford CRFM]
- On the risks of homogenization: "Now almost all NLP models are built on top of BERT, or maybe one of a few of these foundation models... So there's this incredible homogenization that's happening." — Source: [Fast Company]
- On systemic failure: Foundation models create a single point of failure, meaning any defects, biases, or security vulnerabilities are blindly inherited by downstream tasks. — Source: [Fast Company]
- On changing goals: "While humans used to be the paragon for general intelligence, I don't think it is productive to use humans as the goal post anymore, as the standards for AI should be higher in some ways." — Source: [Schmidt Sciences]
- On the role of academia: While industry commands the vast compute resources, academia must provide the scientific standards and exploration that companies overlook in the rush to productize. — Source: [No Priors Podcast]
- On automation in education: "I want to emphasize that a lot of AI is also going to automate really bad ways of teaching. So [we need to] think about it as a way of creating new types of teaching." — Source: [Stanford HAI]
Part 2: Redefining Evaluation and Benchmarking
- On benchmarks as guides: "Benchmarks serve as the North Star for the AI community, providing clear targets to aim for." — Source: [HubSpot Blog]
- On encoding values: "Benchmarking is more than just measurement—it encodes values. Benchmarks determine what the community prioritizes." — Source: [HubSpot Blog]
- On the crisis of evaluation: "The pace of innovation is happening so quickly that we're not able to measure... we're living in a crisis in our ability to measure model quality." — Source: [HubSpot Blog]
- On holistic measurement: To evaluate language models effectively, researchers must acknowledge incompleteness, use multi-metric measurement, and enforce standardization across all models. — Source: [HELM Paper]
- On broader metrics: Evaluation must extend beyond raw accuracy to encompass robustness, fairness, bias, toxicity, and efficiency. — Source: [Princeton AI]
- On transparency: "Transparency is the vital first step... Many language models exist, but they are not compared on a unified standard." — Source: [Stanford University]
- On democratic alignment: The evaluation process needs to be more democratic so that the values a model reflects represent what people actually want, not just the decisions of a few people behind closed doors. — Source: [Stanford Engineering]
- On evaluation as a distinct discipline: "Evaluation has now... become more of a first-class citizen in a way that it was just not before. It was always: you train a model, you evaluate." — Source: [Lex Fridman Podcast]
- On the purpose of testing: "We should start by thinking about the goals of evaluation: is it to provide feedback and incentives for improving a system or is it to assess the absolute quality of a system?" — Source: [NIST Panel]
- On factual boundaries: "I would push back on saying that the hallucinations in itself is fundamentally bad... what are the notion of facts is also a little bit hazy. Now in a given application, there turns out to be things that you should say and things that the language model should not output." — Source: [Stanford Engineering]
Part 3: The Mechanics of Semantic Parsing and NLP
- On the definition of semantic parsing: "Semantic parsers map natural language into logical forms, the classic representation for many important linguistic phenomena." — Source: [Communications of the ACM]
- On logical forms: "We can think of the logical form as a program that is executed to yield the desired behavior." — Source: [Communications of the ACM]
- On the core problem of semantics: "How do you map a natural language utterances into some sort of executable program or meaning representation?" — Source: [Behind the Tech]
- On the history of the field: Early rule-based natural language understanding systems were sophisticated but brittle; the modern resurgence uses logical representations paired with statistical learning. — Source: [JHU Seminar]
- On learning from denotations: It is possible to learn a semantic parser purely from question-answer pairs, treating the intermediate logical form as a latent variable rather than requiring expensive manual annotation. — Source: [MIT AI]
- On bootstrapping parsers: By generating a canonical formal language and having users paraphrase it into natural language, developers can rapidly build semantic parsers for entirely new domains overnight. — Source: [ACL Anthology]
- On lambda dependency-based compositional semantics: λ-DCS was designed as a compact formal language to represent the semantics of natural language more efficiently than traditional lambda calculus. — Source: [OpenReview]
- On structural understanding: Modern large language models still struggle with compositional semantics, exposing gaps in their ability to understand the deep logical structure of language. — Source: [Lex Fridman Podcast]
- On evaluating language understanding: The modern twist on classic linguistic representation is dealing with the statistical and computational issues introduced by learning semantic parsers directly from data. — Source: [Communications of the ACM]
Part 4: Navigating the Open Source vs. Closed Model Debate
- On the fallacy of closed security: "Security by obscurity has always been frowned upon as something that can't be relied on. Malicious, incentivized actors often use that obscurity to get early access to zero-days." — Source: [Together Talks]
- On internet-scale infrastructure: "If you look at the history of computer security... we should build the entire internet ecosystem on Open Standards like SSL... where everyone can stare at each other." — Source: [Together Talks]
- On true open source: Current open weight models are not truly open source because the critical recipes—the training data, code, and evaluation logs—remain secret. — Source: [Together AI Blog]
- On building a Linux for AI: The mission is to create a decentralized, transparent ecosystem for foundation models that prevents the capture of AI by a few closed-source corporations. — Source: [Redpoint Podcast]
- On decentralizing compute: Distributed training across disparate networks and data centers is essential so that frontier research is not confined to a single massive supercomputer. — Source: [Together AI Tech Blog]
- On architectural efficiency: Memory-aware attention mechanisms like FlashAttention drastically reduce the bottlenecks of Transformers, making it viable for the broader community to train and run large models. — Source: [ArXiv]
- On open development: It is critical to practice open development, where every experiment, success, and failure is preregistered and visible to the community in real-time. — Source: [Marin Lab]
- On the transparency index: The AI industry is trending toward dangerous secrecy regarding training data and labor practices, necessitating a formal index to track and audit corporate transparency. — Source: [Stanford HAI]
- On global accessibility: Open-source models are essential for reducing English-language bias and making advanced AI accessible to developers worldwide. — Source: [No Priors Podcast]
- On data efficiency: Rigorous, open scientific tuning of data recipes can lead to massive increases in data efficiency, allowing state-of-the-art performance with a fraction of the traditional data volume. — Source: [Together AI Research]
Part 5: Reliability and Distribution Shifts
- On average-case failure: "Standard machine learning produces models that are accurate on average but degrade dramatically when the test distribution of interest deviates from the training distribution." — Source: [WILDS Benchmark]
- On the limits of scale: "We have found many surprises in our quest for robustness: for example, that the 'more data' and 'bigger models' strategy that works so well for average accuracy sometimes fails out-of-domain." — Source: [MLR Press]
- On redefining reliability: "What is one to do with an 80 percent reliable system? ... The conventional metric for success—average accuracy—is not a good interface for AI safety." — Source: [ADT Mag]
- On uncertainty as safety: "Safe deployment requires AI systems that expose uncertainty to humans... ensuring that an AI understands, and is able to communicate, its limits." — Source: [Stanford Engineering]
- On real-world fragility: Distribution shifts that happen naturally—such as deploying a medical model in a new hospital—consistently degrade system accuracy in ways standard testing fails to capture. — Source: [ICML]
- On ignored data shifts: Despite being ubiquitous in real-world deployments, practical distribution shifts have historically been under-represented in the benchmark datasets favored by the ML community. — Source: [WILDS Benchmark]
- On the failure of robust algorithms: Standard training methods often outperform specialized robustness algorithms on real-world in-the-wild data, highlighting the need for fundamentally new approaches. — Source: [ResearchGate]
- On mission-critical risk: "I think it's really important that we focus on the issue of robustness, especially when these systems are going out into more mission-critical situations like self-driving cars or medical diagnostics." — Source: [Behind the Tech]
- On debugging predictions: Influence functions provide a mathematical framework for debugging model reliability by identifying the exact training points that caused a potentially unsafe prediction. — Source: [ICML]
Part 6: Simulating Society and Generative Agents
- On pure exploration: "I think that was a really fun project because it was pure kind of exploration. It was like, 'We don’t know what’s going to happen, let’s build it and see and simulate.'" — Source: [The AI Podcast]
- On believability versus validity: "While generative agents was about creating believable simulations... if you could get simulations that were actually valid in the sense that they reflected something in reality, then you unlock a lot of different new vistas." — Source: [Redpoint Ventures]
- On digital twins: "For the first time, because we have these models, you can actually simulate something in much greater detail than was ever possible... allowing you to run policy experiments [on a] digital twin of society." — Source: [TWiML AI Podcast]
- On emergent social dynamics: When agents are equipped with a memory stream, reflection, and planning capabilities, they naturally exhibit complex social behaviors like spreading information and coordinating events. — Source: [Generative Agents Paper]
- On the limits of sandbox games: While creating agents that simply look human is sufficient for video games, the true scientific potential lies in modeling specific real-world populations for sociological research. — Source: [Stanford Research]
- On architectural importance: The success of generative agents relies less on the raw scaling of the underlying foundation model and more on the cognitive architecture—specifically how memory and interaction are structured. — Source: [Lex Fridman Podcast]
- On simulating interaction: Language models act as a cognitive engine, but the environment and the structured memory retrieval are what actually ground the agents in a continuous social reality. — Source: [ArXiv]
- On policy testing: Validated social simulations could eventually allow researchers to test the downstream effects of urban planning or economic policies before implementing them in the real world. — Source: [The AI Podcast]
- On autonomous agents: The transition from static prompt-response chatbots to autonomous agents capable of long-term problem-solving requires entirely new evaluation metrics focused on trajectories rather than static answers. — Source: [Together AI Blog]
Part 7: Test-Time Compute and Reasoning
- On the next paradigm: "From a research perspective, I think this signals sort of a change that I think we'll see going in the future. And I think the idea of test-time compute—it's been around, but as with many things, it needs a certain kind of scale for it to sink in for people." — Source: [Redpoint Podcast]
- On the limits of early reasoning products: While test-time compute is a research breakthrough, early implementations were often slow and difficult to integrate into practical user experiences. — Source: [The AI Podcast]
- On scaling inference: "Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance... setting the stage for a new scaling paradigm." — Source: [s1 Paper]
- On budget forcing: "We seek the simplest approach to achieve test-time scaling... 1,000 examples + budget forcing." — Source: [s1 Paper]
- On suppressing early termination: By suppressing a model's end-of-thought tokens and forcing it to generate a "Wait" token, researchers can force the model to think longer and arrive at better answers. — Source: [ArXiv]
- On System 2 thinking: Test-time compute represents the transition from fast, intuitive token prediction (System 1) to slow, deliberate, multi-step reasoning (System 2). — Source: [Together AI Blog]
- On latent reasoning: Complex reasoning capabilities are often already latent in pre-trained models; they do not necessarily require millions of reinforcement learning steps to unlock. — Source: [s1 Paper]
- On data quality for reasoning: A mere 1,000 highly curated reasoning traces can be sufficient to train a model that matches the reasoning capabilities of much larger, RL-heavy systems. — Source: [ACL Anthology]
- On sequential scaling: Letting a single model think deeper sequentially is generally a more effective strategy for solving complex problems than running parallel generations and taking a majority vote. — Source: [Stanford CRFM]
- On the bitter lesson: While raw compute and data scaling have driven recent progress, achieving true logical reasoning requires a return to structural and algorithmic innovations at inference time. — Source: [Lex Fridman Podcast]
Part 8: The Pursuit of Reproducible Research
- On capturing pipelines: "Worksheets allow you to capture complex research pipelines in a reproducible way and create 'executable papers' where researchers attempting to reproduce the results should be able to execute the experiment within the same environment." — Source: [CodaLab Documentation]
- On the mission of reproducibility: "In general, I am a strong proponent of efficient and reproducible research. I created CodaLab Worksheets... to maintain the full provenance of an experiment from raw data to final results." — Source: [Stanford Faculty Profile]
- On collaborative ecosystems: The goal of computational research platforms is to establish a collaborative ecosystem where experiments are conducted efficiently and can be universally verified. — Source: [Microsoft Faculty Summit]
- On the lack of provenance: The current machine learning research process suffers from a severe lack of provenance, making it incredibly difficult for peers to reuse or validate published findings. — Source: [The Gradient Podcast]
- On executable papers: Shipping academic papers as executable environments ensures that the scientific community can instantly verify, modify, and build upon the precise code and data used in the study. — Source: [Generally Intelligent Podcast]
- On true reproducibility: Reproducibility is not simply about posting source code on GitHub; it requires sharing the complete, immutable computational environment and the historical execution graph. — Source: [Simons Foundation]
- On immutability in research: For an experiment to be truly reproducible, the underlying data and code must be fixed and immutable, preventing silent updates from altering historical results. — Source: [CodaLab Documentation]
- On transparency of the process: Every single step, from raw data ingestion to the generation of the final evaluation plot, must be transparently visible to independent reviewers. — Source: [Stanford CRFM]
- On the common task method: The AI community advances fastest when researchers compete and collaborate on shared, rigorously standardized benchmarks with fully reproducible execution pipelines. — Source: [Simons Foundation]