Lessons from Prafulla Dhariwal
Prafulla Dhariwal is an OpenAI research scientist who led the multimodal development of GPT-4o and co-authored the paper showing diffusion models beat GANs at image generation. His engineering covers text-to-image systems, generative audio, and reinforcement learning optimization. This profile collects his technical insights to explain how modern AI architectures are actually built and scaled.
Part 1: Generative Modeling Foundations
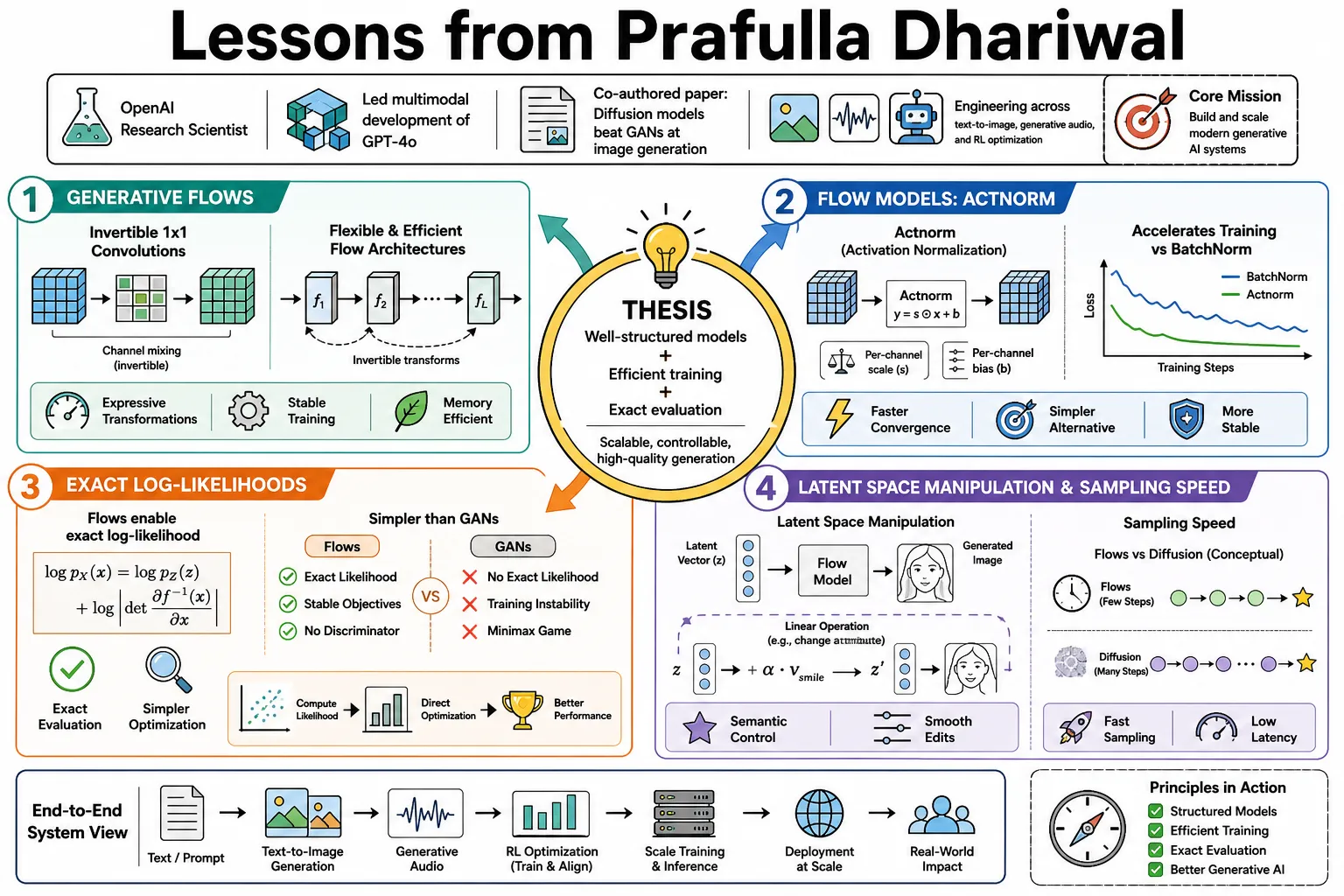
- On Generative Flows: "Invertible 1x1 convolutions offer a straightforward way to create flexible and efficient generative flow architectures." — Source: [Glow Paper]
- On Flow Models: "Actnorm, an activation normalization step, accelerates the training of flow-based models by acting as a simpler alternative to batch normalization." — Source: [Glow Paper]
- On Exact Log-Likelihoods: "Flow-based generative models allow for exact log-likelihood evaluation, which simplifies the optimization process compared to adversarial methods." — Source: [Glow Paper]
- On Latent Space Manipulation: "By operating in a well-structured latent space, models can perform semantic manipulations like changing attributes of a face through simple linear operations." — Source: [Glow Paper]
- On Sampling Speed in Flows: "One of the structural advantages of generative flows is that they allow for fast, exact sampling without requiring an iterative denoising process." — Source: [Glow Paper]
- On Early Generative Challenges: "Before diffusion became standard, the field struggled to find models that were both easy to train and capable of generating high-fidelity outputs." — Source: [OpenAI Research Blog]
- On Model Controllability: "The ability to condition generative outputs on specific attributes or text is what transitions a theoretical model into a practical tool." — Source: [OpenAI Research Blog]
- On Evaluation Metrics: "Relying on standard metrics like FID gives researchers a common ground to compare generative models, even when their underlying architectures are fundamentally different." — Source: [Diffusion Models Beat GANs]
- On Architectural Simplicity: "Often, simplifying the mathematical formulation of a generative model leads to more stable training dynamics and better final performance." — Source: [Improved Denoising Diffusion]
Part 2: Advancing Diffusion Models
- On Beating GANs: "Diffusion models can achieve image sample quality superior to the best generative adversarial networks if the underlying architecture is properly scaled and tuned." — Source: [Diffusion Models Beat GANs]
- On Classifier Guidance: "Using a separate classifier to guide the diffusion process allows models to explicitly balance sample diversity against visual fidelity." — Source: [Diffusion Models Beat GANs]
- On Adversarial Training: "GANs often suffer from mode collapse and training instability; diffusion models avoid these issues by using a straightforward likelihood-based objective." — Source: [Diffusion Models Beat GANs]
- On Noise Schedules: "Learning the variance of the reverse diffusion process, rather than keeping it fixed, significantly improves the log-likelihood and requires fewer sampling steps." — Source: [Improved Denoising Diffusion]
- On U-Net Architectures: "Scaling the U-Net backbone, specifically by increasing the width and applying attention mechanisms at multiple resolutions, directly improves diffusion model performance." — Source: [Diffusion Models Beat GANs]
- On Sample Diversity: "Unlike GANs that tend to memorize or collapse onto specific modes, diffusion models naturally cover the entire data distribution." — Source: [Improved Denoising Diffusion]
- On Truncation in Diffusion: "Classifier guidance acts similarly to the truncation trick used in GANs, giving users a dial to control how safe or diverse the generated images are." — Source: [Diffusion Models Beat GANs]
- On Training Stability: "Because diffusion models are trained to denoise rather than to fool a discriminator, their optimization landscape is much smoother and more predictable." — Source: [Diffusion Models Beat GANs]
- On Gradient Scaling: "Scaling the gradients from a classifier during the denoising steps forces the model to prioritize the conditioning label, producing highly accurate samples." — Source: [Diffusion Models Beat GANs]
- On the Shift in Generative AI: "Demonstrating that diffusion could outperform GANs on standard benchmarks catalyzed the transition toward diffusion-based architectures in the industry." — Source: [Diffusion Models Beat GANs]
Part 3: Building Multimodal Systems (GPT-4o)
- On Natively Multimodal AI: "Training a single model across text, vision, and audio natively prevents the latency and information loss inherent in stitching separate models together." — Source: [GPT-4o Announcement]
- On Real-Time Interaction: "To achieve conversational responsiveness, a model must process audio inputs and generate audio outputs with latencies comparable to human reaction times." — Source: [GPT-4o Announcement]
- On Capturing Audio Nuance: "Separate speech-to-text models lose tone, emotion, and background noise. A natively multimodal model processes these signals directly." — Source: [GPT-4o Announcement]
- On Modality Integration: "When vision, audio, and text share the same neural representation, the model can reason about a visual scene while simultaneously speaking about it." — Source: [GPT-4o Announcement]
- On the Multimodal Lead Role: "Building GPT-4o required aligning research teams across different domains to ensure the architecture could handle diverse data types without degrading performance in any single area." — Source: [Sam Altman on X]
- On Tokenizing Reality: "Expanding the token vocabulary to effectively compress and represent audio and visual data is a core requirement for efficient multimodal training." — Source: [GPT-4o Announcement]
- On Latency Bottlenecks: "Previous voice assistants used a pipeline of transcription, text processing, and text-to-speech, which introduced compounding delays. End-to-end models bypass this entirely." — Source: [GPT-4o Announcement]
- On Expressive Outputs: "A model trained directly on audio can output laughter, varied pacing, and emotional intonation, creating a much more natural user experience." — Source: [GPT-4o Announcement]
- On Interruption Handling: "For an AI to feel conversational, it must be able to process incoming audio streams continuously and stop generating output the moment a user interrupts." — Source: [GPT-4o Announcement]
- On the Future of Interfaces: "Natively multimodal models point toward a future where we interact with computers using the same senses and speeds we use to interact with the physical world." — Source: [GPT-4o Announcement]
Part 4: Speed and Consistency Models
- On Iterative Sampling: "The primary drawback of standard diffusion models is their slow sampling speed, which relies on hundreds of sequential denoising steps." — Source: [Consistency Models]
- On Consistency Models: "By training a model to map any point on a diffusion trajectory directly to the origin, we can generate high-quality images in a single step." — Source: [Consistency Models]
- On Distillation: "Consistency models can be distilled from pre-trained diffusion models, retaining their generation quality while drastically reducing the computational cost of sampling." — Source: [Consistency Models]
- On Zero-Shot Editing: "Like standard diffusion models, consistency models support zero-shot data editing tasks such as inpainting and colorization, but execute them much faster." — Source: [Consistency Models]
- On Real-Time Applications: "Achieving one-step or two-step generation makes it possible to deploy generative image models in real-time applications where latency is strictly constrained." — Source: [Consistency Models]
- On Training Without Distillation: "It is possible to train consistency models in isolation without relying on a pre-existing diffusion model, making them a standalone family of generative models." — Source: [Consistency Models]
- On the Self-Consistency Property: "The core mathematical intuition is self-consistency: the model's prediction of the clean image should remain identical regardless of how much noise was added to the input." — Source: [Consistency Models]
- On Compute Trade-offs: "Consistency models shift the computational burden from inference time back to training time, which is preferable for consumer-facing tools." — Source: [Consistency Models]
- On Multi-Step Generation: "While one step is fast, consistency models allow users to perform multiple steps to incrementally refine the image, offering flexibility between speed and quality." — Source: [Consistency Models]
Part 5: Text-to-Image and GLIDE
- On Classifier-Free Guidance: "Classifier-free guidance provides a way to achieve the benefits of classifier guidance without the overhead of training a separate image classification model." — Source: [GLIDE Paper]
- On Prompt Alignment: "Models trained with classifier-free guidance adhere much more closely to complex text prompts than models trained with standard conditioning." — Source: [GLIDE Paper]
- On Editing with GLIDE: "Text-conditional diffusion models can perform targeted image editing, allowing users to paint over an area and describe what should appear there in text." — Source: [GLIDE Paper]
- On Human Evaluation: "When users compare generative models, they often prefer outputs that strongly match the text prompt over outputs that only maximize photorealism." — Source: [GLIDE Paper]
- On CLIP vs. Classifier-Free: "While CLIP guidance can steer an image toward a prompt, classifier-free guidance directly integrated into the diffusion process yields superior visual results." — Source: [GLIDE Paper]
- On DALL-E 2's Prior: "In hierarchical text-to-image models, using a prior model to map text embeddings to image embeddings significantly improves the structural coherence of the final image." — Source: [DALL-E 2 System Card]
- On Unconditional Generation: "Mixing unconditional training examples with conditional ones allows a single model to act as both a targeted generator and a generic prior." — Source: [GLIDE Paper]
- On Compositionality: "The true test of a text-to-image model is its ability to compose disparate concepts, like a specific texture on an unusual object, without blurring them together." — Source: [GLIDE Paper]
- On Artifact Reduction: "Careful tuning of guidance scales is necessary because pushing the guidance parameter too high can introduce unnatural artifacts and oversaturation." — Source: [GLIDE Paper]
Part 6: Generative Audio and Jukebox
- On Raw Audio Complexity: "Generating raw audio is inherently difficult because a single second of CD-quality music contains tens of thousands of individual data points." — Source: [Jukebox Paper]
- On VQ-VAE for Audio: "Applying Vector Quantized Variational Autoencoders to audio allows us to compress continuous sound waves into discrete tokens." — Source: [Jukebox Paper]
- On Hierarchical Modeling: "To generate coherent music over long timeframes, you must model audio at multiple resolutions, separating local acoustic details from high-level musical structure." — Source: [Jukebox Paper]
- On Autoregressive Transformers: "Once audio is compressed into discrete tokens, autoregressive transformers can predict the next token to compose music, much like language models predict the next word." — Source: [Jukebox Paper]
- On Capturing Vocals: "Unlike symbolic music generators that only output MIDI notes, modeling raw audio captures the nuance of human vocals, instruments, and recording conditions." — Source: [Jukebox Paper]
- On Conditioning Audio: "Providing artist and genre labels during training allows the model to steer the generated music toward specific stylistic signatures." — Source: [Jukebox Paper]
- On Lyric Alignment: "By feeding lyrics into the top level of the hierarchical transformer, the model learns to align synthesized vocals with the provided text." — Source: [Jukebox Paper]
- On Long-Range Dependencies: "The primary limitation in generative music is maintaining thematic consistency; a model must remember a chorus melody minutes after it was first introduced." — Source: [Jukebox Paper]
- On Upsampling Quality: "Generating music involves predicting the low-resolution structure first, and then using separate models to upsample the audio back to a high fidelity." — Source: [Jukebox Paper]
Part 7: Reinforcement Learning (PPO)
- On RL Instability: "Standard policy gradient methods in reinforcement learning often suffer from destructively large policy updates that ruin the agent's performance." — Source: [PPO Paper]
- On Proximal Policy Optimization: "PPO strikes a balance between ease of tuning, sample complexity, and ease of implementation by clipping the objective function." — Source: [PPO Paper]
- On Trust Regions: "Instead of using complex mathematical constraints like KL divergence to limit policy updates, simple clipping provides a reliable surrogate objective." — Source: [PPO Paper]
- On Sample Efficiency: "By allowing multiple epochs of minibatch updates on the same collected data, PPO extracts more learning value from every environment interaction." — Source: [PPO Paper]
- On Simplicity in Algorithms: "An algorithm that is simpler to code and requires fewer hyperparameters is often adopted faster by the research community than a theoretically optimal but complex one." — Source: [PPO Paper]
- On Continuous Control: "PPO performs exceptionally well on continuous control tasks, making it highly applicable to robotics and complex physics simulations." — Source: [PPO Paper]
- On Shared Architectures: "In environments with visual inputs, sharing the neural network layers between the policy function and the value function improves training efficiency." — Source: [PPO Paper]
- On Entropy Bonuses: "Adding an entropy term to the loss function encourages the agent to explore its environment rather than converging prematurely on a suboptimal strategy." — Source: [PPO Paper]
- On Generalization in RL: "The ultimate goal of algorithms like PPO is to provide a default reinforcement learning method that works out-of-the-box across a wide variety of environments." — Source: [PPO Paper]
Part 8: Scaling Laws and Model Architecture
- On Model Scaling: "Increasing the parameter count of language models predictably improves their performance across almost all downstream tasks." — Source: [GPT-3 Paper]
- On Few-Shot Learning: "Massive language models learn to perform new tasks directly from a few examples provided in their prompt, without requiring specialized fine-tuning." — Source: [GPT-3 Paper]
- On Compute Allocation: "The most effective way to advance AI capabilities is to systematically scale compute, data size, and model size in tandem." — Source: [GPT-3 Paper]
- On Memorization vs. Generalization: "As models grow larger, researchers must rigorously filter training data to ensure the model is generalizing patterns rather than just memorizing internet text." — Source: [GPT-3 Paper]
- On Dataset Contamination: "Evaluating massive models requires strict checks to confirm that the testing benchmarks were not inadvertently included in the training dataset." — Source: [GPT-3 Paper]
- On Task Agnosticism: "The strength of large autoregressive models lies in their general-purpose nature; they are not trained for translation or coding, yet they perform both well." — Source: [GPT-3 Paper]
- On Architectural Consistency: "Many of the recent breakthroughs in AI have come not from novel architectures, but from applying the transformer architecture at an unprecedented scale." — Source: [GPT-3 Paper]
- On Predictable Performance: "The relationship between the amount of compute used for training and the model's final loss follows a predictable power law." — Source: [GPT-3 Paper]
- On System Engineering: "Training state-of-the-art models is as much a challenge of distributed systems engineering and infrastructure as it is of algorithmic design." — Source: [OpenAI Research Blog]
- On the AI Research Trajectory: "The focus of modern AI has shifted from designing highly specialized models to building single, massive models capable of absorbing arbitrary modalities." — Source: [Sam Altman on X]