Lessons from Quoc Le
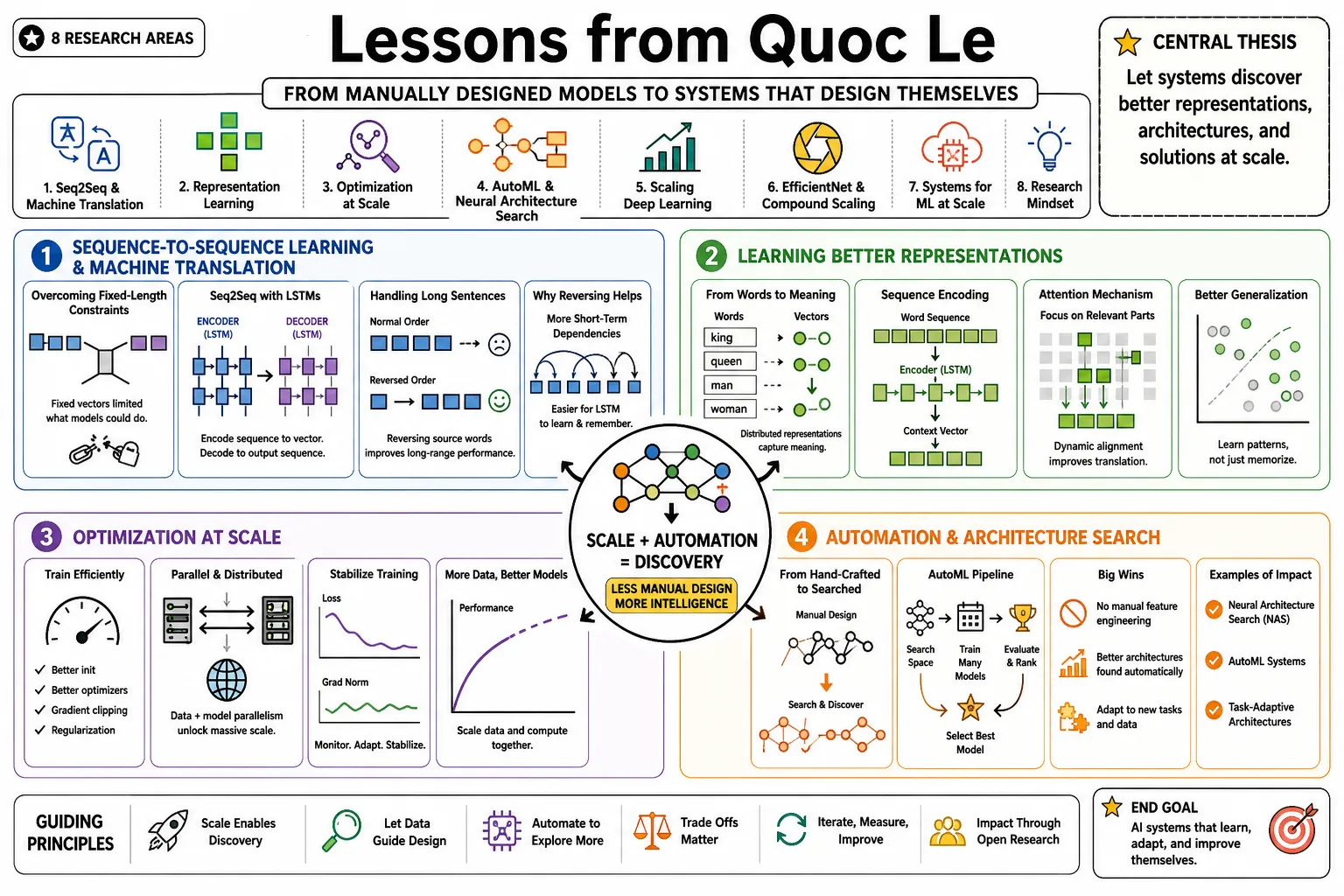
Google DeepMind researcher Quoc Le helped develop sequence-to-sequence learning, AutoML, and EfficientNet. His work pushed machine learning away from manually designed models and toward systems that figure out their own architectures. This collection organizes his insights across eight research areas, breaking down the mechanics of scaling artificial intelligence.
Part 1: Sequence-to-Sequence Learning & Machine Translation
- On overcoming fixed-length constraints: "Before seq2seq, deep neural networks were severely limited because they required inputs and targets to be encoded with vectors of fixed dimensionality." — Source: [NeurIPS 2014]
- On sequence prediction: "By using a multilayer Long Short-Term Memory network to map the input sequence to a vector, and another deep LSTM to decode it, we fundamentally changed how translation models are built." — Source: [Sequence to Sequence Learning Paper]
- On handling long sentences: "A key breakthrough in sequence learning was discovering that reversing the order of the words in all source sentences significantly improved the LSTM's performance on long sentences." — Source: [Sequence to Sequence Learning with Neural Networks]
- On establishing short-term dependencies: "Reversing the source sentence introduces many short-term dependencies to the data, making the optimization problem much easier for the underlying model." — Source: [Google Research]
- On end-to-end translation: "The goal of neural machine translation was to build a single, large neural network that reads a sentence and outputs a correct translation, bypassing complex traditional pipelines." — Source: [Google Brain Technical Report]
- On Google Neural Machine Translation: "Scaling sequence-to-sequence models allowed us to deploy GNMT, replacing older phrase-based translation systems with a model that learns from large amounts of bilingual text." — Source: [GNMT Technical Report]
- On zero-shot translation: "When a neural translation model is trained on multiple language pairs simultaneously, it develops an internal representation that allows it to translate between language pairs it has never explicitly seen." — Source: [Google AI Blog]
- On decoding efficiency: "To deploy large seq2seq models in production, developing efficient beam search heuristics and inference accelerators was just as important as the model architecture itself." — Source: [Google DeepMind Publication]
- On architecture depth: "Deep LSTMs significantly outperformed shallow LSTMs in translation tasks, showing that depth in recurrent networks is required for capturing complex linguistic structures." — Source: [NeurIPS 2014]
- On the legacy of seq2seq: "The sequence-to-sequence framework provided a universal approach that later influenced text summarization, speech recognition, and modern language modeling." — Source: [NeurIPS Test of Time Award]
Part 2: Neural Architecture Search & AutoML
- On automating design: "The process of designing neural network architectures requires extensive expertise and time. AutoML asks whether we can use algorithms to automatically discover these architectures instead." — Source: [AutoML Introduction]
- On reinforcement learning for architecture search: "We framed the architecture search as a reinforcement learning problem where a recurrent network controller generates the structural hyperparameters of neural networks." — Source: [Neural Architecture Search with Reinforcement Learning]
- On surpassing human design: "By allowing a controller to propose architectures and evaluating their accuracy, the algorithm can discover novel network topologies that outperform human-designed counterparts on benchmarks like CIFAR-10." — Source: [Google Brain Research]
- On computational cost: "Early architecture search methods required thousands of GPU days. Making these methods practical meant developing approaches like parameter sharing and differentiable architecture search." — Source: [ENAS Paper]
- On transferring architectures: "A required validation of Neural Architecture Search was showing that architectural cells discovered on small datasets could successfully scale and transfer to massive datasets like ImageNet." — Source: [Learning Transferable Architectures]
- On AutoML Zero: "With AutoML Zero, we pushed the boundary further by starting from empty programs and using evolutionary algorithms to discover complete machine learning algorithms using only basic mathematical operations." — Source: [AutoML-Zero Research]
- On discovering fundamental concepts: "It was fascinating to observe evolutionary algorithms independently rediscover fundamental concepts like gradient descent and backpropagation from scratch through random mutation and selection." — Source: [TWIML AI Podcast]
- On democratizing machine learning: "The ultimate promise of AutoML is to make high-performance machine learning accessible to developers who do not have a PhD in deep learning." — Source: [Kaggle Coffee Chat]
- On evolutionary algorithms vs reinforcement learning: "While reinforcement learning was effective for architecture search, evolutionary methods offer a highly scalable alternative for exploring massive, unconstrained search spaces." — Source: [Regularized Evolution Search]
- On the future of algorithm discovery: "The shift is moving from researchers hand-crafting models to researchers hand-crafting the search spaces and algorithms that will find the models." — Source: [Heroes of NLP Interview]
Part 3: Word and Document Embeddings (Doc2Vec)
- On limitations of bag-of-words: "Traditional bag-of-words models lose the ordering of words and ignore semantics. We needed a representation that could capture the context of variable-length texts." — Source: [Distributed Representations of Sentences]
- On Paragraph Vectors: "Paragraph Vector operates by asking the model to predict the next word in a context, given the surrounding words and a dense vector representing the document itself." — Source: [ICML 2014]
- On vector arithmetic for meaning: "Just as word vectors capture analogies, document vectors map the continuous semantic space of entire paragraphs, grouping texts with similar meaning closely together." — Source: [Distributed Representations Paper]
- On unsupervised text representation: "The power of the paragraph vector algorithm is that it is completely unsupervised, allowing it to learn representations from massive unlabeled text corpora without manual annotation." — Source: [Doc2Vec Methodology]
- On sentiment analysis: "When applied to tasks like sentiment analysis, document embeddings significantly outperformed traditional methods because they inherently captured the subtle contextual shifts in reviews." — Source: [Stanford Research Project]
- On the memory mechanism: "The document vector acts as a memory that remembers what is missing from the current context, acting as a topic or structural guide for the word prediction." — Source: [ICML 2014 Presentation]
- On distributed memory vs distributed bag of words: "We found that concatenating the Distributed Memory model with the Distributed Bag of Words model yielded the most consistent representations across diverse text types." — Source: [Paragraph Vector Analysis]
- On fixed-length representations: "Mapping variable-length paragraphs into fixed-length vectors provided a standard format that could be easily fed into conventional classifiers like logistic regression or support vector machines." — Source: [Google Brain History]
- On early natural language processing: "Creating dense representations of documents was a technical stepping stone between early word embeddings and the contextualized language models we rely on today." — Source: [Heroes of NLP]
Part 4: Efficient Scaling & EfficientNet
- On arbitrary scaling: "Historically, researchers scaled up convolutional networks arbitrarily by adding layers, making them wider, or increasing image resolution. We needed a principled method." — Source: [EfficientNet Paper]
- On compound scaling: "EfficientNet introduced a compound scaling method that uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients." — Source: [EfficientNet: Rethinking Model Scaling]
- On balancing dimensions: "If the input image is bigger, the network needs more layers to increase the receptive field and more channels to capture the finer-grained patterns." — Source: [Google AI Blog]
- On search-driven baselines: "We used Neural Architecture Search to design a strong baseline network, EfficientNet-B0, and then applied our compound scaling to it." — Source: [ICML 2019]
- On efficiency versus accuracy: "The result of compound scaling was a family of models that achieved state-of-the-art accuracy while being significantly smaller and faster than previous models like ResNet or Inception." — Source: [EfficientNet Release]
- On transferring efficiency: "The efficiency of these architectures is not restricted to ImageNet; EfficientNets transfer exceptionally well to other datasets, reducing parameters while maintaining high accuracy." — Source: [Learning Transferable Architectures]
- On EfficientNetV2: "To improve training speed further, EfficientNetV2 combined neural architecture search with scaling, specifically optimizing for training speed and parameter efficiency using fused convolution layers." — Source: [EfficientNetV2 Research]
- On progressive learning: "We coupled EfficientNetV2 with a progressive learning approach, which dynamically increases image size and regularization during training to speed up the process." — Source: [EECS Colloquium Talk]
- On hardware-aware design: "Designing architectures must account for hardware realities. Optimizing for floating point operations is insufficient if memory access bottlenecks the accelerator." — Source: [Google Brain Hardware Research]
Part 5: Semi-Supervised Learning & Noisy Student
- On the value of unlabeled data: "There is a massive amount of unlabeled data available. The challenge is effectively using it to improve the performance of models trained on carefully curated labeled datasets." — Source: [Self-training with Noisy Student]
- On the Noisy Student Training method: "We trained an EfficientNet model on ImageNet, then used it as a teacher to generate pseudo-labels for 300 million unlabeled images, and finally trained a larger student model on this combined data." — Source: [CVPR 2020]
- On the necessity of noise: "The required element of the Noisy Student approach is injecting noise—dropout, stochastic depth, and data augmentation—into the student model during training, forcing it to learn harder representations than the teacher." — Source: [Noisy Student Paper]
- On iterative improvement: "This process can be repeated. The student becomes the new teacher, generating better pseudo-labels for the unlabeled data, creating a cycle of self-improvement." — Source: [Google Research Blog]
- On robustness: "Models trained with the Noisy Student method exhibit remarkable robustness to adversarial perturbations, image corruption, and domain shifts." — Source: [Robustness Analysis in Noisy Student]
- On Meta Pseudo Labels: "Instead of relying on fixed pseudo-labels from a teacher, Meta Pseudo Labels continuously adapts the teacher network using feedback from the student's performance on a validation set." — Source: [Meta Pseudo Labels Research]
- On bridging the gap: "Semi-supervised learning techniques bridge the gap between human learning, which requires very few labels, and traditional supervised deep learning, which is heavily data-dependent." — Source: [TWIML AI Podcast]
- On scaling semi-supervised methods: "The effectiveness of pseudo-labeling scales strongly with the size of the student model. To absorb the vast amount of knowledge in millions of unlabeled images, the student network must be large." — Source: [Self-training with Noisy Student]
- On the limitations of supervised learning: "Supervised learning alone hits an asymptote. To push capabilities further, algorithms must actively extract structure from uncurated data." — Source: [EECS Colloquium]
Part 6: Conversational AI & Meena
- On open-domain dialogue: "Most conversational agents are designed for specific tasks. Our goal with Meena was to build an open-domain chatbot that could chat about virtually anything naturally." — Source: [Towards a Human-like Open-Domain Chatbot]
- On the Sensibleness and Specificity Average: "To measure progress in conversational models, we introduced SSA, which evaluates whether a response makes logical sense in context and whether it is specific rather than a generic deflection." — Source: [Meena Research Paper]
- On the problem of generic responses: "A flaw in early chatbots was their reliance on safe, generic responses like 'I don't know' or 'That's nice.' Specificity is required for human-like engagement." — Source: [Google AI Blog]
- On scaling sequence models for chat: "Meena is essentially an evolved sequence-to-sequence model consisting of an Evolved Transformer encoder and decoder, scaled up to 2.6 billion parameters." — Source: [Towards a Human-like Open-Domain Chatbot]
- On perplexity correlating with human judgment: "We discovered a strong correlation between the model's perplexity—how well it predicts the next word—and its performance on human evaluation metrics like SSA." — Source: [Meena Metric Analysis]
- On learning from social media: "Training on massive amounts of public domain social media conversations allowed the model to internalize the natural flow, humor, and varied contexts of human dialogue." — Source: [Towards a Human-like Open-Domain Chatbot]
- On multi-turn context: "A true conversational agent must maintain coherence over multiple turns. We designed Meena's architecture to process up to seven turns of context to generate its response." — Source: [Google Brain Research]
- On the foundation of LaMDA: "The architectural scaling and evaluation methodologies established with Meena directly paved the way for more advanced conversational systems like LaMDA." — Source: [Google Conversational AI Timeline]
- On safety and factuality: "While maximizing sensibleness and specificity creates engaging chatbots, aligning these models to remain factually accurate and safe requires distinct tuning phases beyond pre-training." — Source: [Towards a Human-like Open-Domain Chatbot]
Part 7: System 2 Thinking & Advanced Reasoning
- On the shift to reasoning: "We are moving from AI that relies heavily on System 1 pattern matching to System 2 thinking, where models perform deliberate, step-by-step reasoning." — Source: [System 1 to System 2 Thinking Talk]
- On Chain-of-Thought prompting: "By prompting a large language model to output its intermediate reasoning steps, we unlocked its ability to solve complex arithmetic and symbolic tasks it previously failed at." — Source: [Chain-of-Thought Reasoning Paper]
- On self-consistency: "Instead of taking a single decoding path, self-consistency samples multiple diverse reasoning paths and selects the most consistent answer, improving reasoning accuracy." — Source: [Self-Consistency Improves Chain of Thought]
- On test-time compute: "System 2 thinking implies that a model should be able to spend more compute time on a hard problem at inference time, scaling performance through search and verification." — Source: [DeepMind Reasoning Research]
- On mathematical theorem proving: "Systems like AlphaGeometry show the power of combining a neural language model for intuitive idea generation with a symbolic engine for rigorous logical deduction." — Source: [AlphaGeometry Announcement]
- On the limits of autoregressive generation: "Generating answers token-by-token limits complex planning. Advanced reasoning requires mechanisms that allow a model to backtrack, revise, and verify its steps before outputting a final answer." — Source: [System 1 vs System 2 AI]
- On reinforcement learning for logic: "To reach Olympiad-level mathematical reasoning, models must be trained via reinforcement learning to explore logical proofs, rewarding successful paths in highly constrained environments." — Source: [AlphaProof Project]
- On the Talker-Reasoner model: "A robust AI agent should separate its communicative functions from its deep-planning functions, mirroring how human cognition separates intuition from deep calculation." — Source: [Talker-Reasoner Architecture]
- On unlocking latent capabilities: "Chain-of-thought does not teach the model new facts; it unlocks latent reasoning capabilities that were acquired during pre-training but inaccessible via standard prompting." — Source: [Chain-of-Thought Research]
Part 8: Career Philosophy & Large-Scale Systems
- On the early days of deep learning: "In the beginning, we wanted to see what would happen if we trained neural networks on unprecedented amounts of data, like millions of frames of YouTube videos." — Source: [Building High-level Features]
- On the 'Google Cat' experiment: "Discovering that a neural network had spontaneously learned the concept of a 'cat' without explicit labels was a pivotal moment in demonstrating the power of unsupervised scaling." — Source: [ICML 2012]
- On computing power: "Progress in deep learning has been fundamentally tied to the scaling of hardware. Distributed computing clusters were the prerequisite for moving from theoretical models to practical breakthroughs." — Source: [Google Brain Systems Research]
- On the nature of research: "A research career as a whole will take a long time to make really significant progress. Be patient and focus on the marathon." — Source: [Medium Profile & Advice]
- On algorithmic simplicity: "Often, the most powerful models are built on simple, scalable mathematical foundations rather than highly complex, handcrafted rules." — Source: [AutoML Zero Analysis]
- On empirical validation: "In deep learning, intuition is useful, but rigorous empirical validation at scale is the only way to prove a concept's viability." — Source: [Heroes of NLP]
- On moving past paradigms: "When we worked on sequence-to-sequence, the prevailing paradigm was phrase-based translation. Progress required being willing to completely abandon the established pipeline." — Source: [GNMT Development]
- On human limitations in design: "Humans are biased toward symmetric, conceptually elegant architectures. Automated search often finds asymmetric, counter-intuitive designs that simply perform better." — Source: [Neural Architecture Search Context]
- On continuous learning: "The field moves incredibly fast. What was considered a solved problem or a standard architecture five years ago is often completely replaced." — Source: [Kaggle Coffee Chat]
- On the goal of AI: "The ultimate trajectory of this research is building systems that can automatically learn, reason, and adapt to any domain without requiring explicit human intervention." — Source: [System 2 AI Keynote]