Lessons from Ruslan Salakhutdinov
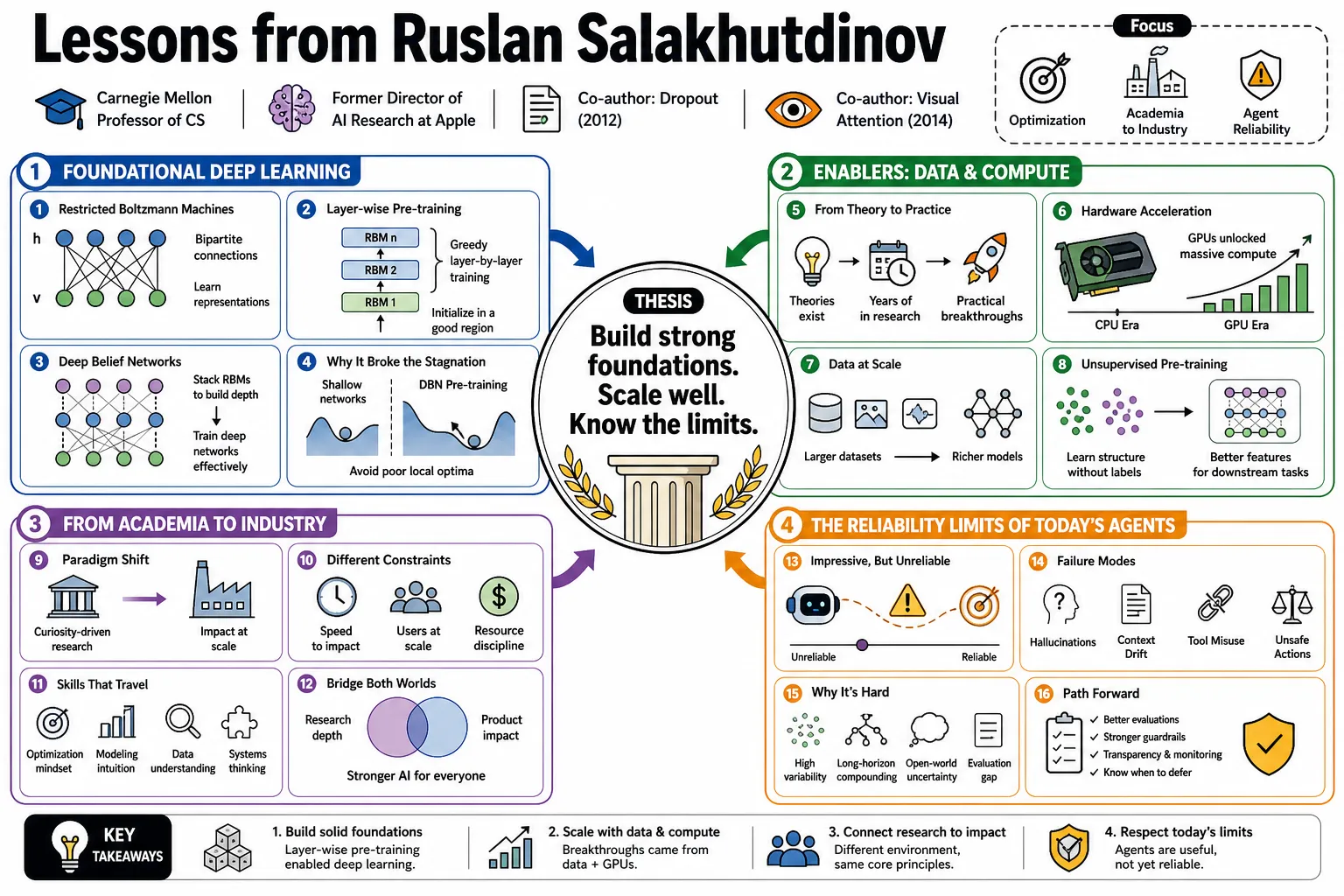
Ruslan Salakhutdinov, a Carnegie Mellon computer science professor and former Director of AI Research at Apple, co-authored early deep learning papers on Dropout and visual attention. This profile covers his work on neural network optimization, AI's shift from academia to industry, and the severe reliability limits of today's autonomous agents.
Part 1: Foundational Deep Learning
- On Restricted Boltzmann Machines: "Early deep learning breakthroughs relied heavily on training Restricted Boltzmann Machines layer by layer, effectively initializing weights in a region of parameter space that allowed gradient descent to succeed." — Source: [Carnegie Mellon University Research Profile]
- On Deep Belief Networks: "Stacking RBMs to form a Deep Belief Network proved that deep architectures could be trained effectively without getting stuck in poor local optima, overcoming decades of stagnation." — Source: [In-Sight Publishing Interview]
- On the limitations of early hardware: "The theoretical models for neural networks existed for years, but it wasn't until the combination of larger datasets and the computational power of GPUs that they became practically viable." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On unsupervised learning: "Pre-training models on massive amounts of unlabeled data was initially a necessity for deep networks, acting as a powerful regularizer before fine-tuning on labeled tasks." — Source: [Carnegie Mellon University Research Profile]
- On probabilistic graphical models: "Bridging deep learning with probabilistic graphical models allows systems to map inputs to outputs while explicitly modeling uncertainty and complex dependencies." — Source: [In-Sight Publishing Interview]
- On learning from Geoffrey Hinton: "Working in Hinton's lab taught me to focus on the underlying probabilistic structure of data rather than treating neural networks purely as black-box function approximators." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On generative models: "The ability of a network to generate realistic synthetic data is the strongest proof that it has actually learned the true underlying distribution of the training set." — Source: [Carnegie Mellon University Research Profile]
- On the resurgence of neural networks: "The shift was driven by demonstrating that deep architectures could extract hierarchical features directly from raw pixels, bypassing hand-engineered features entirely." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On parameter initialization: "Before the advent of techniques like batch normalization and improved optimizers, careful initialization through unsupervised pre-training was the only way to propagate gradients through deep networks." — Source: [Carnegie Mellon University Research Profile]
Part 2: Optimization and Overfitting
- On the core problem of overfitting: "Large neural networks are powerful but prone to overfitting, where they learn complex, idiosyncratic relationships based on noise in the training data rather than true underlying patterns." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On neuron co-adaptation: "Neurons in a deep network often develop co-adaptations, where a single unit becomes useful only in the specific context of other neurons, failing to learn robust, generally useful features on its own." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On the mechanics of Dropout: "By randomly dropping units and their connections during training, you force the network to learn redundant representations, as no individual neuron can rely on the presence of others to fix its errors." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On approximating ensembles: "Training a large network with dropout can be mathematically viewed as training an exponential number of different thinned networks that share parameters." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On test-time scaling: "Instead of averaging the predictions of all possible subnetworks at test time, you can approximate this ensemble effect by using a single, unthinned network with weights scaled down by the dropout probability." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On the evolutionary analogy: "Just as sexual reproduction recombines genes to prevent reliance on a fixed set of traits, dropout forces neurons to be robust by preventing them from becoming too dependent on specific partners." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On network capacity: "Techniques like Dropout allow us to train models with significantly more capacity than the dataset would normally support, without suffering the massive generalization penalties that usually follow." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
- On standardizing regularization: "Before Dropout, preventing overfitting in massive networks required complex, domain-specific penalties; Dropout provided a single scalar hyperparameter that worked across vision, speech, and text." — Source: [Carnegie Mellon University Research Profile]
- On generalization: "The ultimate test of an optimization technique is not how fast training error drops to zero, but how well the learned representations transfer to unseen examples drawn from the same distribution." — Source: [Dropout: A Simple Way to Prevent Neural Networks from Overfitting]
Part 3: Visual Attention and Multimodal Models
- On static image encoding: "Prior to attention mechanisms, encoding an entire image into a single static vector caused models to lose fine-grained details, especially when generating long, descriptive text." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On visual attention: "Implementing an attention mechanism allows the model to look at specific regions of an image that are relevant to the exact word it is currently generating." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On soft deterministic attention: "Soft attention is smooth and differentiable, meaning the model weights all parts of the image based on relevance and can be trained end-to-end using standard backpropagation." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On hard stochastic attention: "Hard attention makes a discrete decision about where to focus at each time step, mimicking human visual fixation, and is trained by maximizing a variational lower bound." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On spatial feature preservation: "By using convolutional feature maps rather than a flattened feature vector, the decoder retains access to the distinct geometric locations within the input image." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On model interpretability: "Plotting attention heatmaps demonstrated that the model naturally learned to align specific generated words, like 'bird', with the corresponding visual regions, offering a rare degree of transparency." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On cross-modal mapping: "The challenge of image captioning is translating from a dense array of pixel values into a sparse, highly structured sequence of discrete words." — Source: [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention]
- On bridging vision and NLP: "Successfully applying attention mechanisms—which were initially developed for machine translation—to computer vision tasks proved that architectural priors could be shared across distinct sensory domains." — Source: [Carnegie Mellon University Research Profile]
- On multimodal representations: "The future of representation learning is multimodal; models must learn to fuse audio, visual, and textual data in the same latent space without relying on perfectly aligned datasets." — Source: [In-Sight Publishing Interview]
Part 4: AI Agents and Long-Horizon Reasoning
- On autonomous agents: "The shift we are seeing now is from models that answer questions to agents that can take actions, interact with software, and execute multi-step plans." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On long-horizon tasks: "Planning over long time horizons requires an agent to maintain state, recognize dead ends, and backtrack, which is fundamentally harder than next-token prediction." — Source: [Carnegie Mellon University Research Profile]
- On multi-agent orchestration: "Multi-agent orchestration is replacing monolithic agents for complex work. You have a frontier model handling high-level planning, while smaller, specialized agents execute specific subtasks." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On structured reasoning: "To solve complex problems, neural networks need to be augmented with external knowledge bases and structured reasoning modules." — Source: [Carnegie Mellon University Research Profile]
- On partial observability: "Real-world environments are partially observable. Agents must learn to make decisions when they only have access to a fraction of the necessary information." — Source: [In-Sight Publishing Interview]
- On working memory: "One of the key bottlenecks for current agents is context windows acting as a poor substitute for true, persistent working memory." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On specialization: "Smaller models fine-tuned for a narrow tool-use task often outperform massive generalized models while being vastly cheaper to run in an orchestrated system." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On error recovery: "An intelligent agent is defined by its ability to recognize a failure state from the environment and formulate an alternative strategy." — Source: [Carnegie Mellon University Research Profile]
- On simulated environments: "Training agents in purely simulated environments is efficient, but the sim-to-real gap remains a massive hurdle when transferring those policies to the physical world." — Source: [In-Sight Publishing Interview]
- On deterministic outcomes: "When a human uses a software tool, they expect a deterministic outcome. When an LLM uses a tool, we currently have to accept a probabilistic outcome, which breaks traditional software engineering assumptions." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
Part 5: Reliability and Safety Guardrails
- On agent reliability: "I would never use any of the agent systems to book me a flight. Even if it's 80% correct, there's at least a 20% gap where it'll go and do something crazy." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On the trust threshold: "The fact of the matter is they would have to be almost 99.99% accurate for me to fully trust them with real-world financial or logistical actions." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On hardwiring guardrails: "When building agent architectures, teams should hardwire guardrails for destructive actions—you cannot rely on training the model to avoid doing them." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On systemic safety: "Safety cannot be an afterthought patched onto a model via prompting; it has to be integrated into the action space the agent is allowed to access." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On unpredictable edge cases: "The tail distribution of possible interactions in the real world is incredibly long, meaning an agent will inevitably encounter scenarios absent from its training data." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On human-in-the-loop: "For the foreseeable future, autonomous systems in high-stakes domains will require a human-in-the-loop to approve actions rather than monitor them." — Source: [In-Sight Publishing Interview]
- On verification: "It is currently much easier for a model to generate a complex plan than it is for us to formally verify that the plan is safe and optimal." — Source: [Carnegie Mellon University Research Profile]
- On alignment: "Aligning an AI is about ensuring its sequential decision-making process optimizes for human constraints." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On brittle systems: "A system that works perfectly 9 times out of 10 but fails catastrophically on the 10th is entirely useless for enterprise deployment." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On capability vs. reliability: "We have over-indexed on pushing the capability frontier of models at the expense of engineering robust reliability into the inference pipeline." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
Part 6: Robotics and Physical AI
- On physical manipulation: "Manipulating objects turns out to be such a difficult thing—especially dexterous manipulations, like when you have two hands and the ability to grab a cup and move it around." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On generalization in robotics: "I can train the model to do it for this specific cup, but being able to do it for any cup turns out to be extremely difficult." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On the trillion-dollar problem: "Whoever cracks this particular physical manipulation problem, where a robot can generalize to unseen objects in unstructured environments, I think it'll be the next trillion-dollar company." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On data scarcity: "Unlike text, where we can scrape the entire internet, robotics suffers from a severe data scarcity problem because physical data collection is slow and expensive." — Source: [Carnegie Mellon University Research Profile]
- On physics constraints: "Language models can hallucinate without immediate consequence, but a physical agent must strictly obey gravity, friction, and torque limits." — Source: [In-Sight Publishing Interview]
- On embodied intelligence: "Learning how the world works is much easier when you can physically interact with it and observe the results." — Source: [Carnegie Mellon University Research Profile]
- On sensor noise: "Robotic algorithms must be robust to sensor noise. The real world is messy, lighting changes, and sensors degrade, unlike clean academic datasets." — Source: [In-Sight Publishing Interview]
- On teleoperation: "Currently, the best way to gather high-quality robotics data is through human teleoperation, essentially having humans demonstrate the optimal physical policy." — Source: [DataFramed Podcast: How AI Agents Will Work While You Sleep]
- On Moravec's paradox: "We have solved high-level reasoning problems like chess and passing the bar exam, while the low-level sensorimotor skills of a one-year-old child remain completely out of reach for AI." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
Part 7: The Gap Between Industry and Academia
- On academic freedom: "In academia, I feel like you have more freedom to work on long-term problems that might not yield a commercial product for a decade." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On industry impact: "At the same time, the research you do in industry is also very exciting because, in many cases, you can impact millions of users directly if you develop a core AI technology." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On compute disparities: "The compute resources available at companies like Meta and Apple are orders of magnitude larger than what most universities can afford, completely changing what experiments are possible." — Source: [Creative Destruction Lab Conference]
- On shifting research cultures: "Industrial labs used to operate very openly, publishing aggressively, but they have become increasingly closed as the commercial stakes of foundational models have skyrocketed." — Source: [Carnegie Mellon University Research Profile]
- On open science: "Academia remains the primary driver of open science, ensuring that smaller institutions and independent researchers can understand and build upon the foundational mechanisms of AI." — Source: [In-Sight Publishing Interview]
- On Apple's AI transition: "When I joined Apple, a major priority was opening up the research culture, encouraging the team to publish papers and engage directly with the broader machine learning community." — Source: [Creative Destruction Lab Conference]
- On talent retention: "Universities face a massive challenge in retaining faculty because the financial and computational incentives offered by industry labs are almost impossible to match." — Source: [Heroes of Deep Learning: Andrew Ng interviews Ruslan Salakhutdinov]
- On engineering infrastructure: "In industry, 90% of the battle is building the data pipelines and infrastructure required to train the model at scale, not just designing the architecture." — Source: [Creative Destruction Lab Conference]
- On basic vs. applied research: "Industry excels at applied scaling and optimization, but academia is often where the weird, contrarian ideas that become the next paradigm shift are initially fostered." — Source: [In-Sight Publishing Interview]
- On collaboration: "The healthiest ecosystem is one where researchers can flow freely between university labs and corporate teams, cross-pollinating theoretical rigor with massive scale." — Source: [Carnegie Mellon University Research Profile]
Part 8: Regulation and the Future of AGI
- On AI regulation: "Regulation is entirely necessary to prevent the monopolization of foundational AI models and to manage the societal risks associated with their deployment." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On managing misinformation: "As generative models become flawless at mimicking human text and video, the volume of AI-generated misinformation will require both technological watermarking and regulatory intervention." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On healthcare applications: "Deploying AI in healthcare presents massive ethical dilemmas; the algorithms can find patterns humans miss, but accountability structures must be legally codified before widespread use." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On military use: "The integration of autonomous systems into military applications is one of the most pressing regulatory challenges of our time, requiring international treaties, not just corporate policies." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On Artificial General Intelligence: "AGI won't arrive as a single monolithic system that suddenly wakes up; it will be an incremental accumulation of highly capable, orchestrated agents that eventually cover all economically valuable tasks." — Source: [In-Sight Publishing Interview]
- On evaluation metrics: "We are rapidly running out of benchmarks; current models max out traditional academic tests, forcing us to constantly invent harder evaluations to measure progress." — Source: [Carnegie Mellon University Research Profile]
- On model interpretability: "Before we entrust critical societal infrastructure to neural networks, we must develop better tools to interrogate exactly why a model made a specific decision." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On societal transformation: "The economic dislocation caused by competent AI agents will require governments to rethink safety nets and labor policies long before we reach anything resembling true AGI." — Source: [Regulating AI Podcast: How AI Is Reshaping Industries and Society]
- On the pace of progress: "The velocity of AI research today is unprecedented; concepts that took a decade to mature in the 2000s are now being iterated upon and deployed in a matter of months." — Source: [In-Sight Publishing Interview]