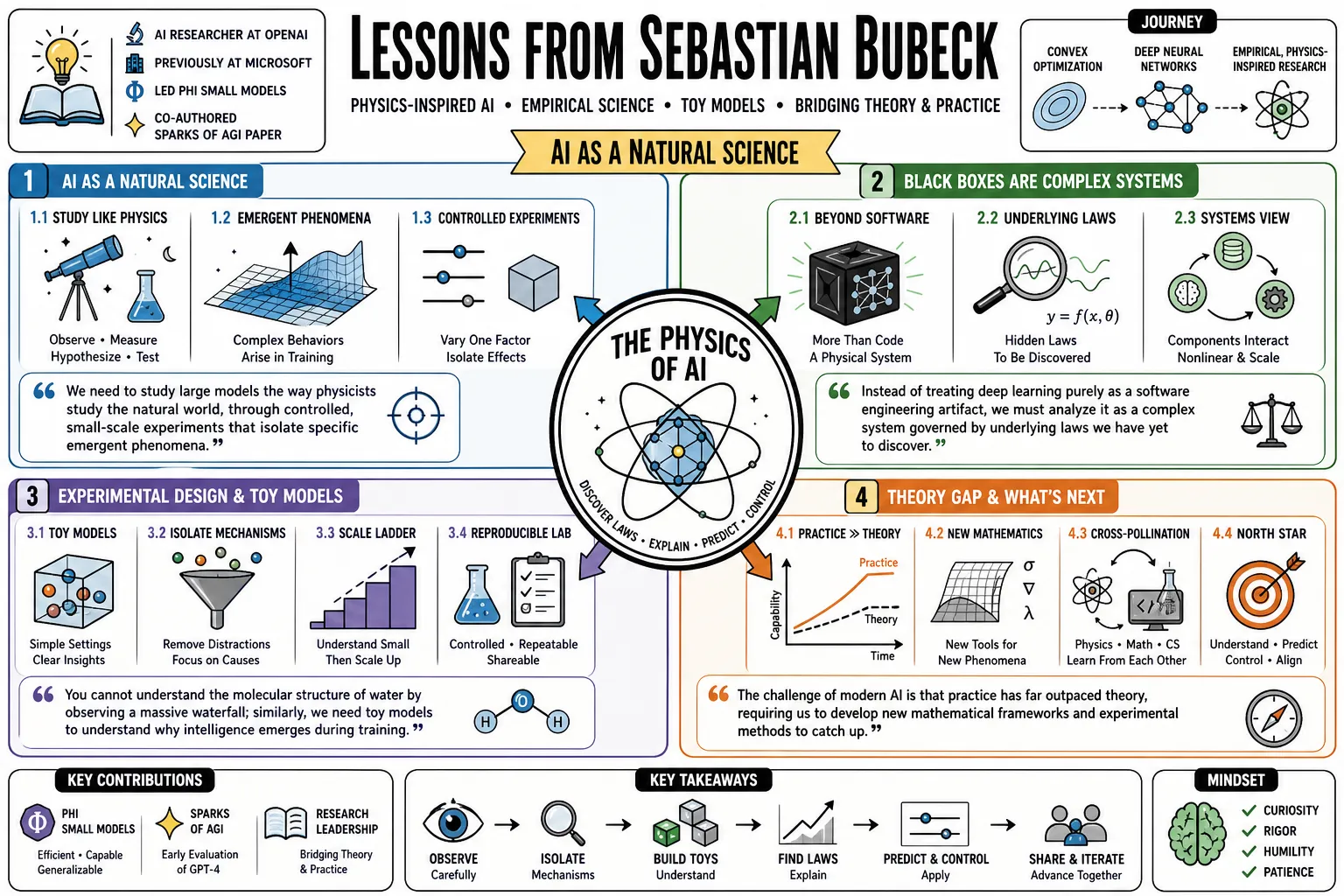
Lessons from Sebastian Bubeck
Sébastien Bubeck is an AI researcher at OpenAI, previously at Microsoft, whose work centers on the mathematical foundations of machine learning. He led the development of the "Phi" small language models and co-authored the "Sparks of AGI" paper evaluating an early version of GPT-4. This collection covers his shift from convex optimization to empirical, physics-inspired research on deep neural networks.
Part 1: The Physics of Artificial Intelligence
- On AI as a natural science: "We need to study large models the way physicists study the natural world, through controlled, small-scale experiments that isolate specific emergent phenomena." — Source: [Physics of AI Podcast]
- On black boxes: "Instead of treating deep learning purely as a software engineering artifact, we must analyze it as a complex system governed by underlying laws we have yet to discover." — Source: [Physics of AI Podcast]
- On experimental design: "You cannot understand the molecular structure of water by observing a massive waterfall; similarly, we need toy models to understand why intelligence emerges during training." — Source: [Physics of AI Podcast]
- On theoretical limits: "The challenge of modern AI is that practice has far outpaced theory, requiring us to build a new theoretical framework from the ground up." — Source: [Simons Institute Debate]
- On evaluating models: "Standard benchmarks are insufficient for measuring intelligence; we must probe models with creative, non-searchable questions that test for genuine understanding." — Source: [Sparks of AGI Presentation]
- On internal representations: "Because these models operate in a trillion-dimensional space, they are capable of developing abstract internal representations that go far beyond statistical pattern matching." — Source: [Sparks of AGI Presentation]
- On empirical rigorousness: "Applying the scientific method to AI means forming hypotheses about network behavior and designing specific data curricula to test them." — Source: [Physics of AI Podcast]
- On scale versus understanding: "Scaling laws tell us what will happen when we add compute, but they do not explain the structural reasons why a network learns a specific concept." — Source: [Simons Institute Debate]
- On mechanism design: "By building simplified mathematical models, we can trace how specific layers and parameters interact to produce what we observe as intelligence." — Source: [TWIML AI Podcast]
- On the future of theory: "We are currently living in the alchemy stage of AI; the goal of the physics of AI is to transition this field into chemistry." — Source: [Chasing Convex Bodies Podcast]
Part 2: Sparks of Artificial General Intelligence
- On early GPT-4: "We saw sparks of AGI because the model exhibited human-level intelligence across a startling variety of novel, difficult, and distinct tasks without prior specific training." — Source: [Sparks of AGI Paper]
- On defining intelligence: "Intelligence is not a single dimension; the model demonstrated early abilities in reasoning, planning, and theory of mind that are traditionally reserved for humans." — Source: [Sparks of AGI Presentation]
- On novel problem solving: "When asked to stack a book, nine eggs, a laptop, and a nail in a stable manner, the model devised a physical solution that required an intuitive understanding of the physical world." — Source: [Sparks of AGI Presentation]
- On the limitations of memorization: "The tasks we gave GPT-4 were specifically designed to be absent from the internet, proving it was constructing answers dynamically rather than retrieving them." — Source: [Sparks of AGI Paper]
- On coding as reasoning: "Programming requires a highly structured form of logical thinking, and the model's ability to translate abstract requirements into functioning code is a strong indicator of general intelligence." — Source: [Sparks of AGI Presentation]
- On tool use: "The transition toward AGI involves models recognizing their own limitations and learning to invoke external tools, like calculators or APIs, to solve complex problems." — Source: [Sparks of AGI Paper]
- On the term Sparks: "We intentionally used the word sparks to signify that while the capabilities are advanced, they are not yet a complete, reliable, or fully formed AGI system." — Source: [Sparks of AGI Presentation]
- On failure modes: "Despite its brilliance in abstract reasoning, the model can inexplicably fail on simple arithmetic or highly specific logical planning, revealing a fragmented form of cognition." — Source: [Sparks of AGI Paper]
- On theory of mind: "The model can navigate complex social scenarios and predict human emotional responses in ways that suggest a functional, if synthetic, theory of mind." — Source: [Sparks of AGI Presentation]
- On autoregressive constraints: "The fundamental architecture of predicting the next token creates inherent limits on planning; the model cannot think ahead in a traditional search-tree manner." — Source: [Simons Institute Debate]
Part 3: The Power of Small Language Models
- On model size: "With phi-1, we demonstrated that a model with only 1.3 billion parameters can achieve over 50% on HumanEval, outperforming models that are 1000x larger in parameter and dataset size." — Source: [Sébastien Bubeck X Announcement]
- On architectural efficiency: "Small models force us to optimize architecture and data, proving that sheer scale is not the only vector for improving artificial intelligence." — Source: [Phi-1 Release Notes]
- On targeted training: "By narrowing the domain to Python coding, we showed that a drastically smaller network could internalize logic and syntax if the signal-to-noise ratio in the data is high enough." — Source: [Textbooks Are All You Need]
- On democratization: "Creating highly capable small language models is essential for making AI accessible, allowing advanced reasoning to run locally on consumer hardware without massive GPU clusters." — Source: [Sébastien Bubeck on Phi-2]
- On local deployment: "The goal of the Phi series is to pack as much intelligence as possible into a footprint small enough to execute efficiently on edge devices and phones." — Source: [Sébastien Bubeck on Phi-2]
- On dense intelligence: "The parameter count is simply the capacity of the model; what matters is the density of knowledge we can effectively pack into those parameters." — Source: [Textbooks Are All You Need]
- On the ceiling of SLMs: "We are still exploring the upper bounds of what small models can achieve; every time we refine the data curriculum, the models punch further above their weight class." — Source: [Sébastien Bubeck on Phi-2]
- On inference costs: "Reducing the size of the model while maintaining performance is the most direct way to solve the massive inference cost and latency issues currently facing AI deployments." — Source: [Phi-1 Release Notes]
- On parameter efficiency: "A smaller, well-trained model often exhibits less hallucination in its specific domain because its limited capacity is filled entirely with high-quality, relevant associations." — Source: [Textbooks Are All You Need]
Part 4: Data Quality and Textbooks Are All You Need
- On synthetic data: "Training models on synthetic textbook data generated by larger models allows us to perfectly control the quality, clarity, and educational value of the training set." — Source: [Textbooks Are All You Need]
- On the limitations of web scraping: "Raw internet data is full of noise, contradictions, and poor formatting; models waste enormous parameter capacity just learning to filter out this garbage." — Source: [Textbooks Are All You Need]
- On pedagogical training: "We approached the training of Phi-1 as a pedagogical problem: how do you write the perfect textbook to teach a neural network to code?" — Source: [Physics of AI Podcast]
- On data curation: "The secret to outperforming massive models is extreme data curation; high-quality input directly translates to high-density intelligence." — Source: [Textbooks Are All You Need]
- On iterative generation: "You can use a highly capable model like GPT-4 to act as a tireless author, generating perfectly formatted, logical exercises to train smaller, more efficient networks." — Source: [Textbooks Are All You Need]
- On signal-to-noise ratio: "By maximizing the signal-to-noise ratio in the training corpus, the gradient updates during training become much more efficient, leading to faster and deeper convergence." — Source: [Textbooks Are All You Need]
- On formatting consistency: "When the training data is highly structured and consistent, the model spends less time learning syntax variations and more time learning the underlying logic." — Source: [Sébastien Bubeck X Announcement]
- On the future of datasets: "The era of simply scraping the entire web is giving way to an era of deliberately engineered datasets designed specifically for machine learning." — Source: [Physics of AI Podcast]
- On exercise diversity: "A good synthetic dataset must contain a vast diversity of distinct exercises to prevent the model from memorizing templates and force it to learn algorithmic reasoning." — Source: [Textbooks Are All You Need]
Part 5: Convex Optimization and Complexity
- On optimization limits: "The fundamental bounds of convex optimization define the absolute limits of how fast and how efficiently any machine learning algorithm can converge." — Source: [Convex Optimization: Algorithms and Complexity]
- On algorithmic design: "Understanding the lower bounds of complexity allows us to stop searching for impossibly fast algorithms and focus on designing methods that achieve optimal rates." — Source: [Convex Optimization: Algorithms and Complexity]
- On practical theory: "As Thomas Cover noted, theory is the first term in the Taylor series of practice; optimization theory provides the necessary starting point for building real-world ML systems." — Source: [Convex Optimization: Algorithms and Complexity]
- On multi-armed bandits: "The bandit problem fundamentally captures the tradeoff between exploration and exploitation, serving as the mathematical core for modern reinforcement learning." — Source: [Chasing Convex Bodies Podcast]
- On gradient descent: "First-order methods like gradient descent are the workhorses of deep learning because their computational complexity per iteration remains manageable even in extraordinarily high dimensions." — Source: [Convex Optimization: Algorithms and Complexity]
- On non-smooth functions: "Real-world machine learning often involves non-smooth landscapes; subgradient methods are mathematically necessary to navigate these spaces effectively." — Source: [Convex Optimization: Algorithms and Complexity]
- On acceleration: "Nesterov's accelerated gradient methods proved that we could fundamentally alter the convergence rate of optimization without needing to compute second-order derivatives." — Source: [Convex Optimization: Algorithms and Complexity]
- On dimension dependence: "The beauty of certain convex optimization algorithms is that their convergence rates are independent of the dimension, which is the exact property that makes them scalable for massive neural networks." — Source: [Convex Optimization: Algorithms and Complexity]
- On the gap between theory and practice: "While deep learning is highly non-convex, the tools, intuition, and convergence proofs we developed for convex optimization remain our best lens for understanding neural network dynamics." — Source: [Chasing Convex Bodies Podcast]
Part 6: Adversarial Robustness and Neural Networks
- On the necessity of size: "Our theoretical work suggests a universal law: for a neural network to be robust against adversarial perturbations, it must be significantly overparameterized." — Source: [A Universal Law of Robustness]
- On geometric constraints: "The susceptibility of neural networks to adversarial attacks is not a bug in the code, but a fundamental geometric property of fitting high-dimensional data smoothly." — Source: [A Universal Law of Robustness]
- On interpolation: "Models that interpolate the training data perfectly will invariably have sharp, non-smooth decision boundaries, leaving them vulnerable to tiny, adversarial shifts." — Source: [TWIML AI Podcast]
- On the cost of robustness: "There is a direct mathematical tradeoff: achieving adversarial robustness requires drastically more parameters than merely achieving high accuracy on a clean dataset." — Source: [A Universal Law of Robustness]
- On isoperimetry: "By applying the concept of isoperimetry from mathematics, we can prove that in high-dimensional spaces, smooth and accurate functions demand immense representational capacity." — Source: [A Universal Law of Robustness]
- On overparameterization: "The mystery of why modern deep learning requires billions of parameters is partially answered by the network's implicit attempt to find a smooth, robust fit in a complex landscape." — Source: [TWIML AI Podcast]
- On safety and scaling: "If robustness mathematically requires massive overparameterization, then building truly safe and reliable AI systems will fundamentally necessitate large-scale models." — Source: [A Universal Law of Robustness]
- On Lipschitz continuity: "Training networks to have a small Lipschitz constant, meaning their outputs change slowly relative to their inputs, is the mathematical key to defending against adversarial examples." — Source: [TWIML AI Podcast]
- On human perception: "Adversarial examples exploit the fact that neural networks represent visual data in a fundamentally different, and mathematically sharper, way than the human visual cortex." — Source: [TWIML AI Podcast]
- On the limits of regularization: "Standard regularization techniques are insufficient to solve adversarial vulnerability; the architecture itself must possess the requisite size to allow for smooth data fitting." — Source: [A Universal Law of Robustness]
Part 7: The Limitations and Boundaries of LLMs
- On deductive limits: "Language models are exceptionally good at pattern matching and synthesis, but they fundamentally struggle with deep, multi-step deductive reasoning." — Source: [Simons Institute Debate]
- On P vs NP: "Current LLM architectures are bounded by their autoregressive nature; they cannot solve computationally hard problems like those in NP without relying on external algorithms." — Source: [Simons Institute Debate]
- On backtracking: "A major limitation of next-token prediction is the inability to seamlessly backtrack when a logical path is proven wrong, which is essential for complex mathematical proofs." — Source: [Sparks of AGI Paper]
- On working memory: "Models have a limited working memory represented by their context window, which constrains their ability to hold and manipulate multiple abstract variables simultaneously." — Source: [Sparks of AGI Presentation]
- On hallucination: "Hallucinations occur because the model's fundamental objective is to generate plausible text, not to verify objective truth; it lacks an internal verification loop." — Source: [Sparks of AGI Paper]
- On compositional tasks: "While an LLM can write a poem and write a proof, asking it to write a proof in the form of a poem often exposes its inability to compose strict constraints reliably." — Source: [Sparks of AGI Presentation]
- On self-correction: "We observe that prompting models to think step by step forces them to explicitly externalize their computation, compensating for their inability to run hidden, recursive logic." — Source: [Simons Institute Debate]
- On out-of-distribution reasoning: "The true test of these models is how they perform on tasks that are definitively outside their training distribution; this is where the illusion of reasoning often breaks down." — Source: [Sparks of AGI Paper]
- On architectural evolution: "To move beyond current limitations, we will likely need new architectures that natively incorporate search, planning, and memory modules, rather than relying purely on feed-forward transformers." — Source: [Simons Institute Debate]
Part 8: The Future of AI and Scientific Discovery
- On mathematical partnerships: "We are entering an era where AI models are no longer tools for calculation, but active collaborators capable of contributing to original, research-level mathematics." — Source: [OpenAI Podcast Ep. 17]
- On discovering new algorithms: "The ability of models to translate abstract concepts into code means they will increasingly be used to discover novel algorithms and optimize scientific computing." — Source: [IPAM AI for Science Talk]
- On interdisciplinary bridges: "AI has the potential to act as a universal translator across scientific disciplines, finding patterns in biology that apply to chemistry, and vice versa." — Source: [IPAM AI for Science Talk]
- On accelerating science: "By automating the routine aspects of hypothesis generation and literature review, AI will fundamentally compress the timeline of scientific discovery." — Source: [OpenAI Podcast Ep. 17]
- On empirical mathematics: "With the help of large models, mathematics is becoming a more empirical science, where we can rapidly test conjectures and search for counterexamples using AI intuition." — Source: [OpenAI Podcast Ep. 17]
- On combinatorics: "The intersection of AI and combinatorics is particularly promising, as AI models excel at navigating massive discrete search spaces to find structural regularities." — Source: [IPAM AI for Science Talk]
- On scientific communication: "LLMs will revolutionize how science is communicated, allowing researchers to instantly translate dense mathematical proofs into accessible explanations across different fields." — Source: [Physics of AI Podcast]
- On automated reasoning: "The ultimate goal for AI in science is the development of robust, automated theorem provers that combine the creative intuition of LLMs with the absolute certainty of formal logic." — Source: [Simons Institute Debate]
- On human intuition: "Even as AI systems become more capable, the uniquely human ability to define the right questions and select the most meaningful mathematical frameworks will remain the core of scientific progress." — Source: [OpenAI Podcast Ep. 17]