Lessons from Sergey Levine
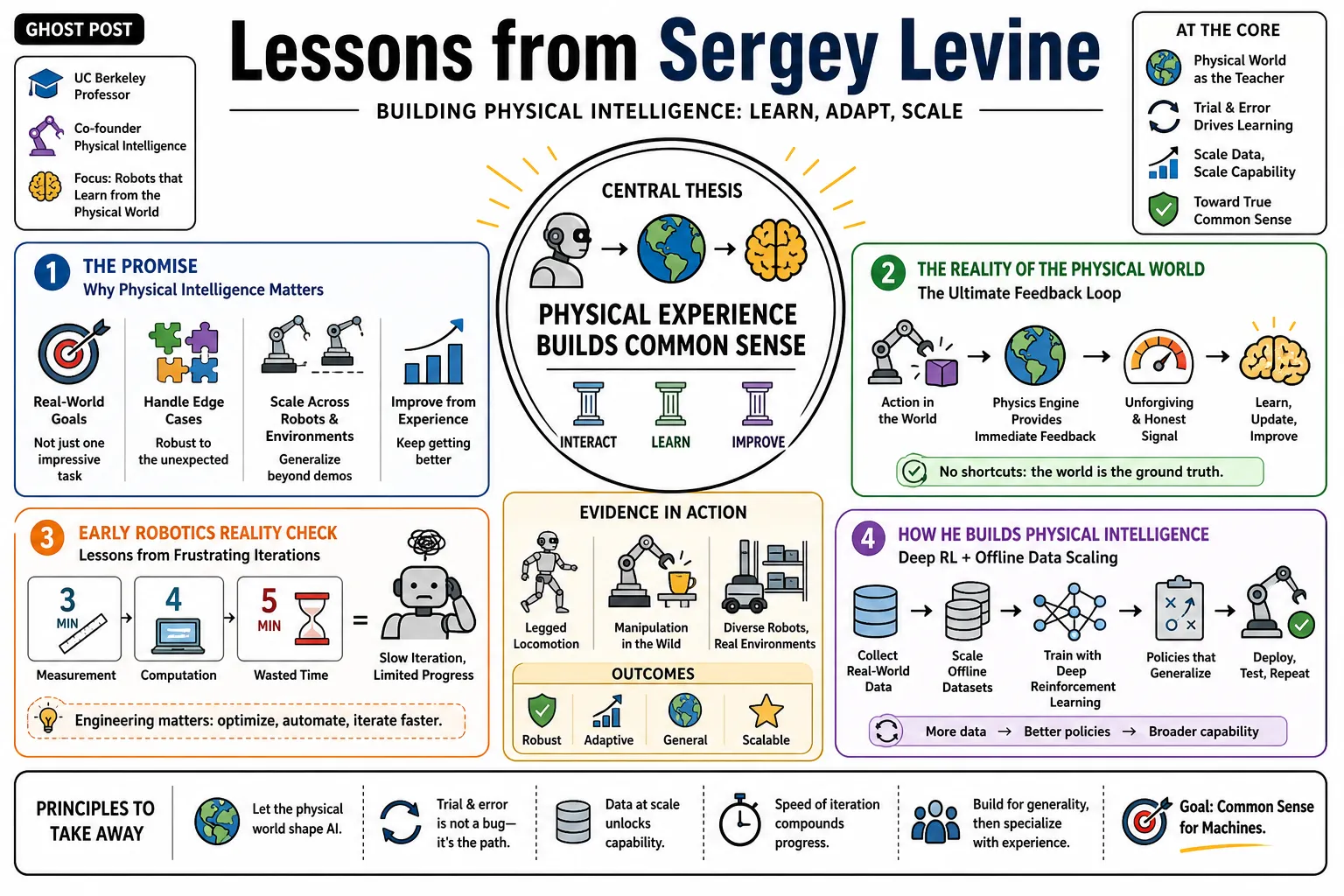
Sergey Levine, a UC Berkeley professor and co-founder of Physical Intelligence, focuses on making robots learn through trial and error instead of rigid programming. His research into deep reinforcement learning and offline data scaling explores how machines can acquire physical intuition. This collection details his view that building actual common sense into AI requires it to interact directly with the physical world.
Part 1: The Promise and Challenge of Physical Intelligence
- On the ultimate goal: "The hardest part in robotics is not getting a machine to do one impressive task on camera. It is building systems that can improve from real-world experience, handle edge cases, and scale across different robots and environments." — Source: [Automate.org Interview]
- On the reality of the physical world: "The physical world forces AI out of its sterile digital environment. If a system makes a mistake in reality, the physics engine of the real world provides immediate, unforgiving feedback." — Source: [Lex Fridman Podcast #108]
- On early robotics frustrations: "It takes 3 minutes of measurement, 4 minutes of computation, and 5 minutes were wasted because we did this in MATLAB and didn't optimize our code very well." — Source: [Cornell Tech Talk]
- On the nature of intelligence: "Intelligence is fundamentally tied to interaction. Passive observation of text or video is useful, but true understanding requires an agent to act and see the consequences of its actions." — Source: [Learning and Control Substack]
- On the new bottleneck: "Basic motor skills are improving fast. The harder problem now is judgment. That kind of common sense remains one of the biggest unsolved challenges in physical AI." — Source: [Automate.org Interview]
- On generalization in robotics: "While vision and NLP systems generalize well because of vast internet datasets, robots historically failed to generalize because they were trained on narrow, task-specific lab data." — Source: [Dwarkesh Podcast]
- On the definition of success: "A successful robotic system is not one that never fails, but one that knows how to recover from its failures autonomously." — Source: [The Gradient Podcast]
- On hardware vs. software: "The physical capabilities of robot hardware have been sufficient for complex tasks for decades; the missing piece has always been the software capable of processing unstructured sensor data into reliable control." — Source: [Robot Brains Podcast]
- On general-purpose machines: "We are moving away from the era of purpose-built machines that only do one task in a factory, toward general-purpose physical agents that can adapt to the chaotic environments of human homes." — Source: [Physical Intelligence Blog]
- On the zone of proximal development: "The best learning happens when a system is challenged just beyond what it can already do. For robots, that means creating environments where they can succeed, fail, adapt, and improve." — Source: [Automate.org Interview]
Part 2: Deep Reinforcement Learning in Robotics
- On the appeal of RL: "Reinforcement learning is attractive because it offers a mathematical framework for an agent to discover behaviors from scratch, driven purely by a reward signal rather than explicit human instructions." — Source: [Lex Fridman Podcast #108]
- On the bitter lesson in robotics: "The history of AI suggests that methods relying on computation and raw data eventually outperform methods relying on human-engineered features. Robotics will be no exception." — Source: [Lex Fridman Podcast #108]
- On end-to-end learning: "Mapping pixels directly to motor torques without intermediate human-designed representations allows the neural network to find more efficient solutions than a human engineer could explicitly program." — Source: [BAIR Blog]
- On exploration: "One of the central challenges of RL in the real world is safe exploration; a robot cannot try millions of random arm movements without eventually breaking itself or its environment." — Source: [The Gradient Podcast]
- On reward design: "Specifying what a robot should do is often harder than it seems. If you tell a robot to clean a room by minimizing the amount of dirt it sees, it might close its eyes to solve the problem." — Source: [Learning and Control Substack]
- On the sample efficiency problem: "Traditional deep RL algorithms were designed for video games where data is infinite. Applying them to physical robots requires algorithms that can learn from orders of magnitude fewer attempts." — Source: [Eye on AI Podcast]
- On continuous control: "Unlike board games with discrete moves, robots operate in continuous space and time, requiring distinct algorithmic architectures to handle fluid, uninterrupted motion." — Source: [Lex Fridman Podcast #108]
- On imitation vs. reinforcement: "While imitation learning is great for getting a robot to perform a task quickly, reinforcement learning is necessary if you want the robot to surpass human performance or discover novel solutions." — Source: [Robot Brains Podcast]
- On self-supervised practice: "A promising path for RL is allowing robots to propose their own goals, practice them overnight, and wake up more capable without requiring a human to manually reset the environment." — Source: [Dwarkesh Podcast]
Part 3: The Imperative of Data and Scaling
- On the data flywheel: "If we can make robots capable enough that they are worth deploying, the data flywheel enabled by fleets of useful deployed robots will lead to datasets of embodied experience that dwarf anything that can be collected from the web." — Source: [Learning and Control Substack]
- On data driving generalization: "In domains where generalization has been studied successfully, invariably good generalization stems from access to large, diverse, and representative datasets. Can we transplant this lesson into the world of reinforcement learning?" — Source: [Reinforcement Learning with Large Datasets]
- On the limitation of lab data: "A robot trained exclusively in a pristine university lab will fail the moment it encounters the varying lighting, cluttered backgrounds, and unpredictable physics of a normal kitchen." — Source: [Dwarkesh Podcast]
- On cross-embodiment data: "To achieve true scale, we need foundation models that can digest data from many different types of robots like arms, quadrupeds, and humanoids, rather than building a separate model for each specific hardware iteration." — Source: [Physical Intelligence Blog]
- On internet data vs. physical data: "Internet text teaches an AI about facts and human reasoning, but it lacks the physical grounding required to know how hard to grip a slippery glass without breaking it." — Source: [Eye on AI Podcast]
- On teleoperation: "High-quality teleoperation is currently the fastest way to bootstrap robotic datasets, allowing humans to guide robots through tasks to provide the initial behavioral cloning data." — Source: [Robot Brains Podcast]
- On data diversity: "It is often better to have a messy, diverse dataset of a robot attempting tasks in hundreds of different environments than a perfectly clean dataset of a robot succeeding in only one environment." — Source: [BAIR Blog]
- On the economics of robot data: "The initial cost of gathering robotic data is high, but once the models pass a threshold of utility, the data gathering becomes a byproduct of economic use, creating an exponential curve of capability." — Source: [Dwarkesh Podcast]
- On sharing data: "The robotics community has historically been fragmented, with everyone building their own small datasets. Progress will accelerate when the field standardizes around massive, shared data repositories like ImageNet did for vision." — Source: [The Gradient Podcast]
- On the scale of human experience: "A human child absorbs thousands of hours of rich, multimodal, interactive data before they can tie their shoes. We should not expect robots to learn complex physical tasks from a few minutes of video." — Source: [Lex Fridman Podcast #108]
Part 4: Offline Reinforcement Learning
- On the premise of offline RL: "The goal of offline RL is to learn a policy purely from static datasets of previously logged experience, without requiring the agent to interact with the environment during training." — Source: [Learning and Control Substack]
- On the distribution shift problem: "The core challenge of offline RL is that the model will try to evaluate actions it has never seen in the dataset, often overestimating their value and failing catastrophically when deployed." — Source: [BAIR Blog]
- On turning RL into supervised learning: "By making RL work on static datasets, we can utilize the same massive compute infrastructure and scaling laws that drove the success of large language models." — Source: [The Gradient Podcast]
- On learning from sub-optimal data: "A key advantage of offline RL is that the algorithm can stitch together successful segments from mostly failed attempts to construct a strategy that is better than any single trajectory in the dataset." — Source: [Lex Fridman Podcast #108]
- On the safety advantage: "Offline RL is inherently safer for real-world robotics because the training phase does not require executing unverified, exploratory neural network outputs on fragile physical hardware." — Source: [Eye on AI Podcast]
- On conservatism in algorithms: "To make offline RL work, algorithms must be pessimistic about the unknown. They must penalize actions that are not supported by the data distribution to avoid delusional optimism." — Source: [BAIR Blog]
- On combining datasets: "Offline RL allows us to pool decades of logged robotic interaction data from different labs and tasks into a single giant pre-training run." — Source: [Dwarkesh Podcast]
- On the paradigm shift: "Moving from online to offline RL shifts the focus of the researcher from managing delicate hardware experiments to managing massive data pipelines and compute clusters." — Source: [Robot Brains Podcast]
- On fine-tuning: "The ideal workflow is to pre-train a massive model using offline RL on a diverse dataset, and then perform a brief phase of online RL in the target environment to adapt to specific local conditions." — Source: [The Gradient Podcast]
Part 5: Sim-to-Real vs. Real-World Experience
- On the allure of simulation: "Simulation is incredibly tempting because compute is cheaper and faster than physical robots, but simulations are always an approximation of reality." — Source: [Lex Fridman Podcast #108]
- On the reality gap: "The slight differences in friction, sensor noise, and contact dynamics between the simulator and the real world often cause policies trained purely in sim to fail instantly on hardware." — Source: [BAIR Blog]
- On domain randomization: "We can bridge the sim-to-real gap by randomly altering the physics and visuals of the simulation during training, forcing the network to learn consistent strategies that can survive the transition to reality." — Source: [Robot Brains Podcast]
- On the limits of simulation: "Everything that people can do themselves ultimately was learned from embodied experience, and even seemingly abstract tasks ultimately ground out in physical events that are governed by the same physical laws that mediate robotic interaction." — Source: [Learning and Control Substack]
- On deformable objects: "While simulating rigid bodies like blocks is largely solved, simulating the physics of folding laundry, manipulating fluids, or peeling vegetables remains computationally prohibitive and highly inaccurate." — Source: [Dwarkesh Podcast]
- On the necessity of real data: "Ultimately, there is no substitute for real-world interaction. A model that has only ever operated in simulation is akin to someone who read a book about swimming trying to jump into the ocean." — Source: [Eye on AI Podcast]
- On hybrid approaches: "The most effective current systems often use simulation for initial pre-training to learn basic representations, followed by extensive fine-tuning on real-world hardware." — Source: [The Gradient Podcast]
- On over-fitting to the simulator: "If an RL agent is left in a simulator for too long, it will eventually discover and exploit bugs in the physics engine rather than learning the intended behavior." — Source: [Lex Fridman Podcast #108]
- On the cost of building simulators: "Hand-engineering a highly accurate simulator for a complex task often takes more human labor than simply building a real-world data collection pipeline for the same task." — Source: [Learning and Control Substack]
- On the future of sim: "Simulation will always be a valuable tool for safety testing and initial validation, but the core foundation models for robotics will be predominantly trained on massive amounts of real-world video and proprioceptive data." — Source: [Physical Intelligence Blog]
Part 6: Embodied AI and the Roots of Common Sense
- On robotics as a path to reasoning: "I’m going to slightly dodge that question and say that I think maybe actually it’s the other way around is that studying robotics can help us understand how to put common sense into our AI systems." — Source: [Happy Scribe Transcripts]
- On emergent understanding: "One way to think about common sense is that common sense is an emergent property of actually having to interact with the world." — Source: [Happy Scribe Transcripts]
- On the grounding problem: "Language models can generate plausible text about how to cook an egg, but they lack the grounded physical intuition of what an egg actually feels like when it cracks." — Source: [Lex Fridman Podcast #108]
- On predicting the future: "A fundamental component of common sense is the ability to predict the physical consequences of an action before taking it, like knowing that a glass placed on the edge of a table might fall." — Source: [Learning and Control Substack]
- On multi-modal perception: "True embodied AI must seamlessly integrate vision, proprioception, touch, and audio to build a complete representation of its environment, much like humans do instinctively." — Source: [Robot Brains Podcast]
- On physical intuition vs. logic: "Much of what we call human intelligence is not high-level abstract logic, but a deep, subconscious physical intuition about how the material world operates." — Source: [Dwarkesh Podcast]
- On the limitations of text: "Text is a highly compressed, low-bandwidth representation of human experience. Uncompressing that into reliable physical action requires models that understand the silent, unwritten rules of physics." — Source: [Eye on AI Podcast]
- On continuous learning: "An embodied agent cannot be static; its common sense must continually update as it encounters novel physical properties and objects in the real world." — Source: [The Gradient Podcast]
- On defining embodiment: "Embodiment is more than having a physical chassis; it is about the feedback loop of action and perception, where the agent's choices directly alter the data it receives next." — Source: [Lex Fridman Podcast #108]
Part 7: Foundation Models for Robotics
- On the goal of foundation models: "The robotics industry needs its own GPT moment: a single, massive model that can control a wide variety of hardware platforms across entirely different physical environments without starting from scratch." — Source: [Dwarkesh Podcast]
- On action chunking: "Modern robot models often predict entire sequences of actions at once, rather than single steps, to ensure smooth movement and overcome the latency of network inference." — Source: [Physical Intelligence Blog]
- On using language models: "We can use the vast semantic knowledge embedded in existing LLMs to help robots break down high-level human commands into sequences of achievable physical steps." — Source: [Robot Brains Podcast]
- On the challenge of vocabulary: "Language has a discrete, shared vocabulary, but robotics lacks a universal vocabulary of movement. Different robots have different joints, motors, and degrees of freedom." — Source: [Learning and Control Substack]
- On cross-training: "A robotic foundation model trained simultaneously on robotic arm manipulation and quadruped locomotion might discover shared underlying principles of physics and balance that improve performance on both." — Source: [BAIR Blog]
- On open-vocabulary manipulation: "We want robots that can follow instructions to pick up novel objects they have never explicitly been trained on, simply by understanding the semantic relationship between the verbal command and the visual input." — Source: [The Gradient Podcast]
- On self-correction: "A true foundation model for robotics will go beyond executing a trajectory blindly; it will continuously monitor its own progress visually and physically, correcting its grip if an object starts to slip." — Source: [Eye on AI Podcast]
- On compute requirements: "Training general-purpose physical models requires infrastructure comparable to that used for frontier language models, processing petabytes of video and sensor telemetry." — Source: [Physical Intelligence Blog]
- On fine-tuning efficiency: "A mature robotic foundation model should be capable of learning a new factory task or household chore with only a few minutes of human demonstration, rather than weeks of coding." — Source: [Dwarkesh Podcast]
Part 8: The Future of Autonomous Systems
- On the timeline for home robots: "While factory automation is here, building a robot that can reliably navigate the chaos of an unmapped human living room and fold laundry will require significant breakthroughs in physical generalization." — Source: [Dwarkesh Podcast]
- On the role of researchers: "The role of the AI researcher is shifting from designing clever algorithms to designing clever systems for autonomous data collection and scalable training architectures." — Source: [Lex Fridman Podcast #108]
- On safety in the home: "The safety of physical AI cannot be guaranteed by rigid mathematical proofs; it must be learned through extensive experience, much like humans learn to interact safely with sharp objects." — Source: [Learning and Control Substack]
- On human-robot collaboration: "The near future is not full autonomy, but collaborative systems where robots handle the repetitive physical work and humans provide high-level judgment and interventions when the model is uncertain." — Source: [Robot Brains Podcast]
- On the intelligence explosion in robotics: "Once robots are deployed at scale, the data they collect will be used to train the next generation of models, creating a rapid feedback loop of physical capability that will outpace hardware iterations." — Source: [Eye on AI Podcast]
- On the democratization of robotics: "When software becomes the dominant factor, the cost of robotics will plummet. Cheap, mass-produced hardware driven by highly intelligent, generalized software will make robots accessible to small businesses." — Source: [The Gradient Podcast]
- On overcoming the Moravec paradox: "High-level reasoning is easy for computers, while low-level sensorimotor skills are incredibly hard. Deep RL and massive data scaling are our best tools to finally solve the hard half of this paradox." — Source: [Lex Fridman Podcast #108]
- On unglamorous progress: "The path to artificial general intelligence will not be paved by a single algorithmic breakthrough, but by the tedious, unglamorous engineering work of making real-world data pipelines stable and consistent." — Source: [BAIR Blog]
- On the ultimate impact: "Giving AI physical agency will transform our relationship with computation. Rather than only organizing our digital information, AI will be able to organize and manipulate the physical reality we inhabit." — Source: [Physical Intelligence Blog]