Shreya Shankar is a computer science researcher at UC Berkeley, transitioning to an assistant professorship at Carnegie Mellon University in 2027. She focuses on building reliable data systems for machine learning, most notably creating DocETL, an open-source declarative system for processing unstructured data. This collection surveys her work across AI evaluation, MLOps, and human-computer interaction, highlighting her practical approach to solving production-level engineering problems.
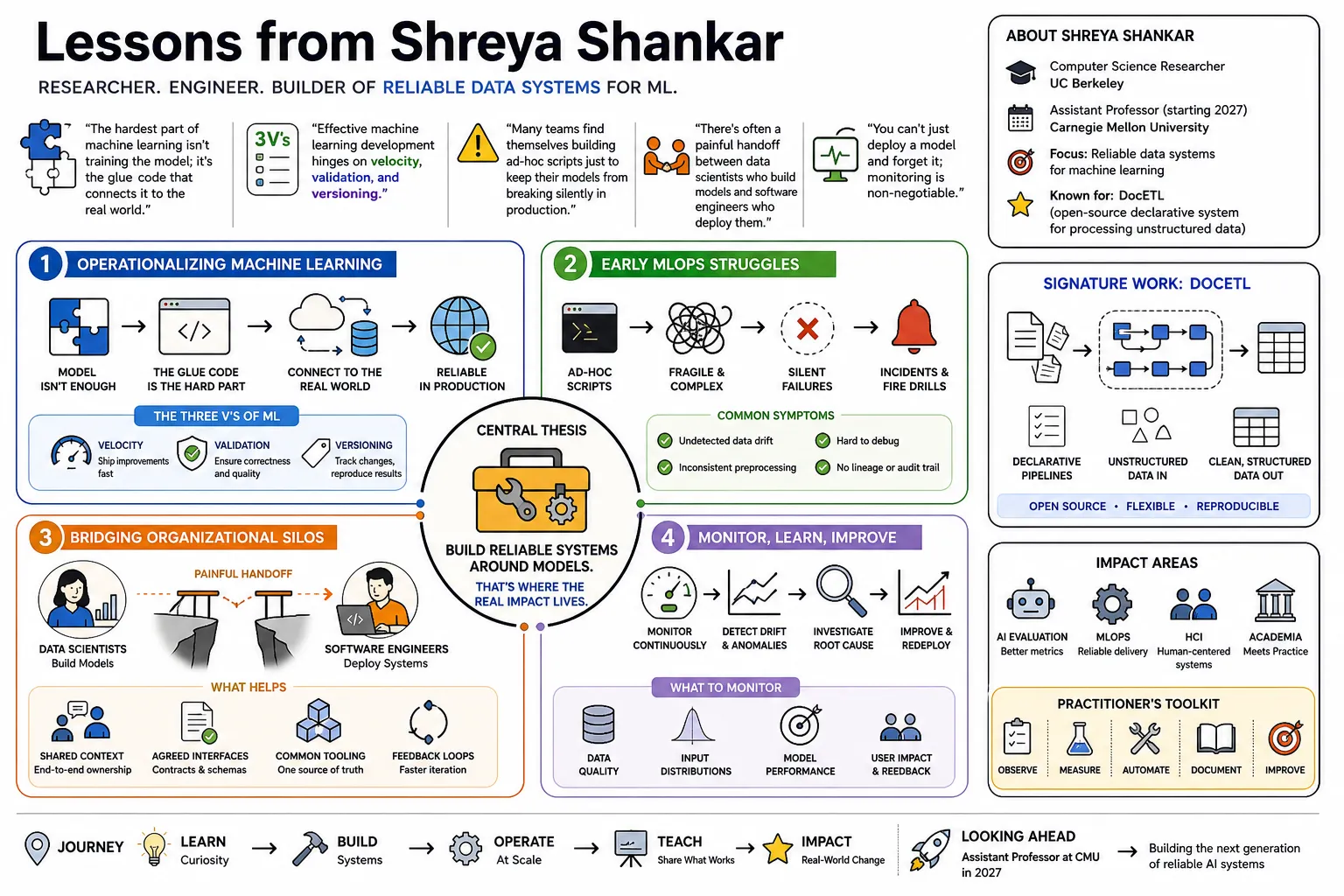
Part 1: Operationalizing Machine Learning
- On the friction of deployment: "The hardest part of machine learning isn't training the model; it's the glue code that connects it to the real world." — Source: [Latent.Space]
- On the three V's of ML: "Effective machine learning development hinges on velocity, validation, and versioning." — Source: [Latent.Space]
- On early MLOps struggles: "Many teams find themselves building ad-hoc scripts just to keep their models from breaking silently in production." — Source: [Gradient Dissent]
- On organizational silos: "There's often a painful handoff between data scientists who build models and software engineers who deploy them." — Source: [The Gradient Podcast]
- On the necessity of monitoring: "You can't just deploy a model and forget it; the real world changes, and your data distributions will shift." — Source: [Gradient Dissent]
- On engineering debt in ML: "Machine learning systems accumulate technical debt faster than traditional software if you don't aggressively manage data dependencies." — Source: [Latent.Space]
- On the reality of Jupyter notebooks: "Notebooks are great for exploration, but terrible for reproducibility and production readiness." — Source: [The Gradient Podcast]
- On defining success: "A model with high accuracy in validation is useless if it introduces unacceptable latency in the application." — Source: [Gradient Dissent]
- On debugging models: "Debugging machine learning is fundamentally different from software debugging; you are debugging the data and the objective, more than the code." — Source: [Latent.Space]
- On the tooling ecosystem: "We need tools that map to how practitioners actually work, rather than forcing them into rigid, theoretical workflows." — Source: [The Gradient Podcast]
Part 2: The Evolution of AI Evaluation
- On the purpose of evals: "Rigorous evaluation is what separates enduring AI products from early prototypes that eventually fade away." — Source: [sh-reya.com]
- On vanity metrics: "Beware of vanity dashboards that look impressive but don't actually tell you if the model is solving the user's problem." — Source: [sh-reya.com]
- On the spectrum of evaluation: "Evaluation isn't one-size-fits-all; it ranges from continuous dogfooding to highly structured, rigorous benchmarks." — Source: [sh-reya.com]
- On building internal tools: "Teams should feel empowered to build their own evaluation tools tailored to their specific domains." — Source: [sh-reya.com]
- On continuous improvement: "An evaluation framework should drive action and iteration, more than output a static score." — Source: [sh-reya.com]
- On LLM subjectivity: "Evaluating large language models is uniquely difficult because the outputs are open-ended and highly context-dependent." — Source: [TWIML AI Podcast]
- On domain expertise: "When a task is well-represented in training, sometimes relying on domain experts to dogfood the product is the most efficient evaluation method." — Source: [sh-reya.com]
- On democratizing evals: "We need to teach engineers and PMs the principles of evaluation so it becomes a standard part of product development." — Source: [sh-reya.com]
- On failure modes: "Capturing and categorizing failure modes systematically is often more informative than tracking overall accuracy." — Source: [TWIML AI Podcast]
- On evaluating agents: "Agentic systems require benchmarking more than the final output, but the trajectory of steps taken to get there." — Source: [TWIML AI Podcast]
Part 3: Data Quality and Observability
- On data as the foundation: "Your model will only ever be as good as the data pipeline that feeds it." — Source: [The Gradient Podcast]
- On silent failures: "The most dangerous bugs in ML systems don't throw errors; they quietly degrade performance due to bad data." — Source: [Gradient Dissent]
- On unstructured data: "Processing unstructured data reliably is the next major frontier for enterprise AI." — Source: [sh-reya.com]
- On data validation: "We need strong schemas and assertions for data, just like we have unit tests for code." — Source: [Latent.Space]
- On tracking provenance: "Understanding exactly which data points influenced a specific model decision is important for debugging and trust." — Source: [The Gradient Podcast]
- On the cost of bad data: "Fixing data quality issues upstream is orders of magnitude cheaper than trying to correct model behavior downstream." — Source: [Gradient Dissent]
- On real-time observability: "Batch monitoring is no longer sufficient; we need real-time visibility into the health of ML pipelines." — Source: [The Gradient Podcast]
- On feature stores: "Feature stores only solve part of the problem if the underlying data generation process is flawed." — Source: [Latent.Space]
- On managing complexity: "As data pipelines grow more complex, declarative approaches help abstract away the brittle, manual logic." — Source: [TWIML AI Podcast]
Part 4: Building DocETL and Declarative Systems
- On the motivation for DocETL: "I built DocETL because writing custom scripts to process complex documents with LLMs was tedious and error-prone." — Source: [TWIML AI Podcast]
- On declarative processing: "By allowing users to declare what they want, the system can optimize how to extract it, saving both time and API costs." — Source: [sh-reya.com]
- On handling complex documents: "Standard chunking strategies often destroy the context necessary for LLMs to extract meaningful insights from long documents." — Source: [TWIML AI Podcast]
- On optimization under the hood: "DocETL uses query rewriting and prompt optimization to ensure high-quality extraction without manual tuning." — Source: [sh-reya.com]
- On the cost of LLM calls: "A major barrier to enterprise LLM adoption is the unpredictable cost of running large-scale data processing pipelines." — Source: [TWIML AI Podcast]
- On open-source impact: "Making DocETL open-source was essential to see how real organizations push the boundaries of unstructured data." — Source: [sh-reya.com]
- On schema evolution: "Declarative systems need to gracefully handle situations where the target schema changes based on what the LLM discovers." — Source: [TWIML AI Podcast]
- On abstraction layers: "We need an abstraction layer for LLM pipelines that separates the logic of extraction from the mechanics of API calls." — Source: [sh-reya.com]
- On map-reduce for LLMs: "Applying traditional map-reduce concepts to LLM operations requires careful consideration of context windows and token limits." — Source: [TWIML AI Podcast]
Part 5: Human-Computer Interaction in AI
- On consistency over brilliance: "The big unlock for AI adoption is making the model feel dependable under real workflow pressure, more than impressive in isolated prompts." — Source: [sh-reya.com]
- On the babysitting tax: "Developers often experience a psychological cost when forced to constantly babysit and fact-check autonomous agents." — Source: [sh-reya.com]
- On model alignment: "Excessive safety layers can sometimes leave models feeling confused or insecure, leading to incoherent responses." — Source: [sh-reya.com]
- On human-centered design: "AI systems must be designed around how humans actually work, rather than forcing humans to adapt to the model's quirks." — Source: [The Gradient Podcast]
- On trust in AI: "Trust is built through predictable behavior and clear explanations of failure, more than high accuracy metrics." — Source: [Latent.Space]
- On user frustration: "Users are less annoyed by a model saying 'I don't know' than by a model confidently providing formatting errors." — Source: [sh-reya.com]
- On linguistic tells: "LLMs often struggle with clarity, selecting grammatical subjects that don't match the main idea or using orphaned demonstratives." — Source: [sh-reya.com]
- On iterative workflows: "The best AI tools support an iterative back-and-forth, allowing the human to guide the model toward the right outcome." — Source: [The Gradient Podcast]
- On the illusion of autonomy: "We shouldn't sell full autonomy when the reality is that a human-in-the-loop is still required for quality assurance." — Source: [sh-reya.com]
Part 6: The Reality of Autonomous Agents
- On agent fragility: "Agents look great in demos but often fail unpredictably when confronted with the messy reality of production environments." — Source: [TWIML AI Podcast]
- On compounding errors: "In multi-step agent workflows, a small hallucination early on can derail the entire process." — Source: [TWIML AI Podcast]
- On state management: "Effective agents require strong memory and state management to recover gracefully from unexpected API errors." — Source: [The Gradient Podcast]
- On the need for guardrails: "We cannot deploy agents without strict declarative guardrails that constrain their action space." — Source: [sh-reya.com]
- On evaluating tool use: "Benchmarking an agent's ability to use external tools requires dynamic environments, more than static datasets." — Source: [TWIML AI Podcast]
- On the limits of prompting: "You can't prompt-engineer your way out of a fundamentally flawed agent architecture." — Source: [sh-reya.com]
- On human oversight: "Designing systems that escalate to a human when the agent is uncertain is a feature, not a bug." — Source: [Latent.Space]
- On predictable latency: "Agents that take wildly variable amounts of time to complete tasks create a poor user experience." — Source: [TWIML AI Podcast]
- On task scoping: "Agents succeed when given narrowly scoped, well-defined tasks, rather than vague, open-ended directives." — Source: [sh-reya.com]
Part 7: Bridging Industry and Academia
- On grounded research: "Academic research is most impactful when it addresses the actual pain points experienced by practitioners in the industry." — Source: [Latent.Space]
- On leaving industry: "I moved to academia because I wanted the freedom to solve foundational problems rather than just putting out immediate fires." — Source: [Latent.Space]
- On qualitative studies: "Interviewing engineers about their daily struggles revealed insights that we couldn't have found through quantitative metrics alone." — Source: [Gradient Dissent]
- On theoretical models: "A beautifully mathematical model is useless if it requires infrastructure that no company actually possesses." — Source: [The Gradient Podcast]
- On open-source as a bridge: "Releasing research as usable open-source software is the fastest way to validate its utility in the real world." — Source: [sh-reya.com]
- On moving fast: "Academia can learn from the velocity of industry, while industry can benefit from the rigor of academia." — Source: [Latent.Space]
- On defining problems: "The hardest part of research isn't solving the problem; it's defining a problem that actually matters." — Source: [Datacast]
- On cross-pollination: "We need more researchers spending time in industry trenches to understand how systems fail at scale." — Source: [The Gradient Podcast]
- On long-term thinking: "The academic environment provides the space to build systems like DocETL that require deep, long-term architectural thinking." — Source: [TWIML AI Podcast]
Part 8: Navigating a Career in Tech and AI
- On building intuition: "The best way to understand machine learning systems is to build them from scratch and watch them break." — Source: [Datacast]
- On startup experience: "Working at an early-stage startup forces you to understand the entire stack, from data ingestion to model deployment." — Source: [Datacast]
- On sharing knowledge: "Writing about your failures and what you learned is just as valuable as publishing successful research papers." — Source: [sh-reya.com]
- On imposter syndrome: "The field moves so fast that everyone feels like they are falling behind; the key is to focus on fundamentals." — Source: [Datacast]
- On mentorship: "Finding mentors who will give you honest feedback on your code and your writing is critical for growth." — Source: [Latent.Space]
- On interdisciplinary work: "The most interesting problems in AI right now sit at the intersection of systems engineering and human-computer interaction." — Source: [The Gradient Podcast]
- On adapting to change: "You can't be rigidly attached to a specific tool or framework; you have to be attached to solving the underlying problem." — Source: [Latent.Space]
- On diverse perspectives: "Building strong AI systems requires teams with diverse backgrounds, more than homogeneous groups of ML researchers." — Source: [Datacast]
- On continuous learning: "I spend a significant amount of time just reading code and documentation from other projects to see how they tackle hard problems." — Source: [sh-reya.com]
- On the future of the field: "We are moving away from an era of building larger models to an era of building more reliable and integrated systems." — Source: [The Gradient Podcast]