Lessons from Brendan Gregg
Brendan Gregg is the performance engineer behind Flame Graphs and the USE method. At Joyent, Netflix, and Intel, he built practical tools to help developers track down software bottlenecks and measure latency. This collection outlines his core approaches to finding system limits and debugging infrastructure with hard evidence.
Part 1: Systems Thinking and Methodology
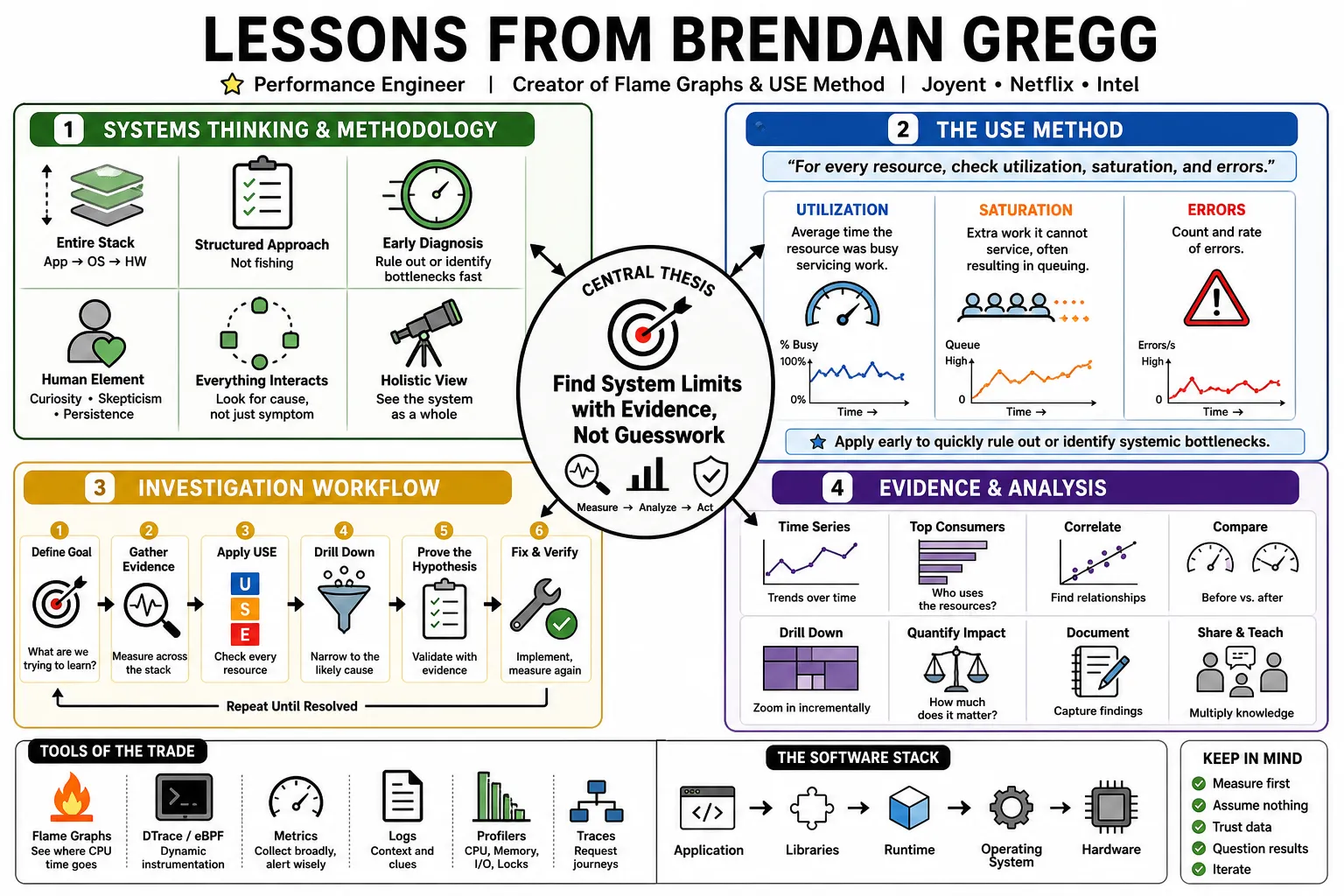
- On the USE Method: "For every resource, check utilization, saturation, and errors." — Source: [The USE Method]
- On defining utilization: "Utilization is the average time the resource was busy servicing work." — Source: [The USE Method]
- On defining saturation: "Saturation is the degree to which the resource has extra work it cannot service, often resulting in queuing." — Source: [The USE Method]
- On early diagnosis: "The USE method is intended to be used early in an investigation to quickly rule out or identify systemic bottlenecks." — Source: [The USE Method]
- On structured approaches: "Performance analysis needs a structured approach rather than fishing for problems." — Source: [Software Engineering Radio Ep. 225]
- On system scope: "Systems performance is the study of the entire software stack, from the application down to the hardware." — Source: [Software Engineering Radio Ep. 225]
- On the human element: "The deep holistic analysis connecting hardware, kernel, and application behavior remains a deeply human endeavor." — Source: [Velocity Conference Keynote]
- On eliminating work: "The best optimization is eliminating unnecessary work entirely. Don't do it." — Source: [Performance Mantras]
- On scheduling work: "Use asynchronous processing or batching to move work out of the critical path. Do it later." — Source: [Performance Mantras]
- On caching: "Do it, but don't do it again. Use caching to avoid repeating expensive operations." — Source: [Performance Mantras]
Part 2: The Illusion of Metrics and CPU
- On misleading metrics: "CPU utilization is wrong. It includes time the CPU spends stalled waiting for memory I/O." — Source: [CPU Utilization is Wrong]
- On stalled instructions: "A system can show 90 percent utilization while the CPU is actually idle 70 percent of the time waiting for data." — Source: [CPU Utilization is Wrong]
- On true execution: "Use Hardware Performance Counters to measure Instructions Per Cycle to understand if a workload is CPU-bound or memory-bound." — Source: [Linux Performance Tools]
- On queuing theory: "Beyond 60 percent utilization, the average response time doubles. By 80 percent, it has tripled." — Source: [Systems Performance: Enterprise and the Cloud]
- On load averages: "Load averages are a historical metric that can give you a quick sense of system demand, but they don't tell you why it is high." — Source: [Linux Load Averages: Solving the Mystery]
- On memory statistics: "Memory is often the hidden bottleneck; you must distinguish between active memory and filesystem cache." — Source: [Systems Performance: Enterprise and the Cloud]
- On missing metrics: "If the dashboard is green but users are complaining, the dashboard is missing the relevant metric." — Source: [Performance Anti-Patterns]
- On basic tooling accuracy: "Before jumping into complex machine learning for performance, ensure your basic system metrics and observability are accurate." — Source: [Brendan Gregg's Blog]
- On hardware capacity: "The real performance of any computer hardware in production is the result of the hardware, software, and tuning like a three-stage rocket." — Source: [Brendan Gregg's Blog]
Part 3: eBPF and Kernel Tracing
- On eBPF superpowers: "eBPF allows for running sandboxed programs in the Linux kernel without changing kernel source code or loading modules." — Source: [BPF Performance Tools]
- On low overhead tracing: "eBPF enables deep tracing with negligible performance impact, often less than 0.1 percent." — Source: [BPF Performance Tools]
- On crisis prevention: "eBPF can help eliminate 'Blue Fridays' by stopping system outages and performance crises before they escalate." — Source: [The Changelog Ep. 673]
- On custom instrumentation: "Necessity is the mother of good BPF tools. Focus on solving something no other tool can." — Source: [USENIX LISA 2021]
- On dynamic tracing: "Dynamic tracing lets you instrument any software event in production without recompilation." — Source: [DTrace: Dynamic Tracing in Oracle Solaris, Mac OS X and FreeBSD]
- On kernel visibility: "BPF provides a microscope into the operating system, allowing you to track every disk I/O or TCP connection." — Source: [BPF Performance Tools]
- On tool evolution: "In 2014, I had no tools for this problem. In 2024, I have too many tools for this problem." — Source: [Brendan Gregg's Blog]
- On resolving issues quickly: "Our methodology is to solve any performance issue reported on Monday by Friday using eBPF superpowers." — Source: [The Changelog Ep. 673]
- On performance profiles: "You can use `perf_events` to identify resource consumption in ways other tools simply cannot." — Source: [SCALE 13x Interview]
Part 4: Flame Graphs and Visualization
- On the origin of Flame Graphs: "I invented flame graphs when working on a MySQL performance issue and needed to understand CPU usage quickly and in depth." — Source: [Flame Graphs Origin]
- On solving the data problem: "The regular profilers and tracers had produced walls of text, so I was exploring visualizations." — Source: [Flame Graphs Origin]
- On structural design: "By reordering the stack traces alphabetically and merging identical frames, you create a hierarchical visualization." — Source: [Flame Graphs Origin]
- On defining the tool: "Flame graphs are a visualization for sampled stack traces, which allows hot code-paths to be identified quickly." — Source: [Flame Graphs Origin]
- On visual interpretation: "The width of each box represents the frequency of that code path in the profile." — Source: [Flame Graphs Origin]
- On mixed-mode profiling: "Mixed-mode flame graphs allow you to see both Java and kernel-level stack traces in a single view." — Source: [Java Flame Graphs]
- On frame pointers: "Modifying the Java Hotspot VM to return frame pointers enabled accurate stack profiling on Linux." — Source: [SCALE 13x Interview]
- On analyzing perturbations: "FlameScope allows for analyzing short-lived performance spikes by sub-sampling profile data." — Source: [FlameScope Announcement]
- On off-CPU time: "Off-CPU flame graphs show you where your application is spending time blocked on I/O, locks, or timers." — Source: [Off-CPU Flame Graphs]
- On accessibility: "The goal of these visualizations is to democratize performance analysis so anyone can spot the bottleneck." — Source: [USENIX LISA Award Interview]
Part 5: Performance Engineering Strategy
- On return on investment: "A new performance team can likely find enough optimizations to halve infrastructure spend in their first couple of years." — Source: [When to Hire a Computer Performance Engineering Team]
- On early intervention: "Having a one-hour meeting with a performance engineering team can save months of engineering effort." — Source: [When to Hire a Computer Performance Engineering Team]
- On architectural flaws: "Early performance analysis prevents developers from building on flawed architectural assumptions." — Source: [Systems Performance: Enterprise and the Cloud]
- On longevity of the skill: "As long as performance matters, the skill of performance engineering will matter." — Source: [Brendan Gregg's Blog]
- On company culture: "The performance team's role is not to gatekeep, but to empower developers with the tools to solve their own issues." — Source: [Netflix Performance Culture]
- On self-service tooling: "Building tools like Vector allows developers to generate flame graphs with a single click, without needing to SSH into servers." — Source: [Vector Profiling Tool]
- On cloud abstraction: "Virtualization creates challenges for performance analysis because the hardware layer is abstracted away from the tenant." — Source: [Software Engineering Radio Ep. 225]
- On continuous profiling: "Measure early and often, but do not just throw fireballs of slow, bloated code into the world and hope to fix it later." — Source: [Brendan Gregg's Blog]
- On optimizing complexity: "Don't do it yet. Do not optimize until you have a perfectly clear and unoptimized solution." — Source: [Optimization Rules]
Part 6: Benchmarking Reality
- On active benchmarking: "Active benchmarking requires analyzing the system using observability tools while the benchmark is actually running." — Source: [Active Benchmarking]
- On passive benchmarking: "Passive benchmarking is a fire-and-forget approach that leads to misleading data because it ignores background noise." — Source: [Active Benchmarking]
- On benchmarketing: "Benchmarketing is the practice of selectively choosing benchmarks to produce impressive-looking results for marketing." — Source: [Active Benchmarking]
- On validating limits: "Ask yourself: Did it break limits? Did you exceed the theoretical maximum of the hardware?" — Source: [Benchmarking Checklist]
- On hidden errors: "If a benchmark result is suspiciously fast, ask if it errored out. The code might just be failing quickly." — Source: [Benchmarking Checklist]
- On practical thresholds: "Why not double? If a performance change didn't double performance, you must question if it is worth the added complexity." — Source: [Benchmarking Checklist]
- On real-world relevance: "Verify whether the bottleneck you are testing in the lab is actually a bottleneck in the real world." — Source: [Benchmarking Checklist]
- On verifying targets: "You use tools like `top`, `iostat`, or `perf` during execution to verify that you are measuring the intended component, not filesystem cache." — Source: [Active Benchmarking]
- On reproducibility: "A benchmark must be reproducible. If you cannot get the same result twice, you haven't measured anything useful." — Source: [Benchmarking Checklist]
Part 7: Anti-Patterns and Common Pitfalls
- On the Streetlight Anti-Method: "The Streetlight Anti-Method is looking for lost keys under a streetlight just because the light is better there, ignoring the actual bottleneck." — Source: [Performance Anti-Patterns]
- On random tuning: "The Drunk Man Anti-Method involves tuning parameters at random until the problem seemingly goes away, without understanding why." — Source: [Performance Anti-Patterns]
- On passing the buck: "The Blame Someone Else Anti-Method assumes the issue lies in a component you do not manage, like the network, without gathering evidence." — Source: [Performance Anti-Patterns]
- On disposable infrastructure: "Terminating a slow cloud instance and hoping the replacement is better is the Bad Instance Anti-Method." — Source: [Performance Anti-Patterns]
- On systemic warnings: "Killing bad instances can hide systemic bugs or early warnings of larger, cascading failures." — Source: [Performance Anti-Patterns]
- On gut feelings: "An anti-pattern is identifying bottlenecks based on intuition rather than empirical facts." — Source: [Performance Anti-Patterns]
- On local vs global optimization: "Optimizing a single local component and assuming it will improve global performance is flawed. Performance is emergent." — Source: [Performance Anti-Patterns]
- On client impact: "Tuning low-level OS metrics without measuring the actual impact on end-user latency is a strategic mistake." — Source: [Performance Anti-Patterns]
- On the Traffic Light Anti-Method: "Relying solely on green, yellow, and red dashboards abstracts away the raw data you need for real debugging." — Source: [Performance Anti-Patterns]
- On workload characterization: "Always identify who is making requests, what they are requesting, and why before you start tuning the system." — Source: [Workload Characterization]
Part 8: Tools, Culture, and the Future
- On the first 60 seconds: "Run standard commands like `dmesg`, `vmstat`, and `iostat` first. Get a broad view of the system before diving deep." — Source: [Linux Performance Analysis in 60 Seconds]
- On democratization: "We must move performance analysis away from a secret priesthood of senior admins and into a documented, methodical science." — Source: [USENIX LISA Award Interview]
- On subjective expertise: "Performance is a subjective field that requires rigorous, deep expertise to turn into a repeatable science." — Source: [BookFlocks Interview]
- On reading documentation: "I read Solaris Internals over 13 months, refusing to turn a page until I fully understood every concept." — Source: [BookFlocks Interview]
- On mentorship through writing: "Technical books should read like accessible mentors, much like Evi Nemeth’s System Administration Handbooks." — Source: [BookFlocks Interview]
- On the RED method: "While the USE method looks at resources, the RED method—measuring request rate, errors, and duration—is the counterpart for services." — Source: [Systems Performance Methods]
- On scaling urgency: "Do anything, do it at scale, and do it today." — Source: [OpenAI Announcement Blog]
- On AI limitations: "Even the best AI models currently only automate about 15 percent of a performance engineer's deep diagnostic work." — Source: [OpenAI Announcement Blog]
- On AI versus human agents: "There is a distinction between AI assistants that interpret metrics and the actual analysis done by a human." — Source: [OpenAI Announcement Blog]